

Over the last few years the idea of “conditional computation” has been key to making neural network processing more efficient, even though much of the hardware ecosystem has focused on general purpose approaches that rely on matrix math operations that brute force the problem instead of selectively operate on only the required pieces. In turn, given that this was the processor world we live in, innovation on the frameworks side kept time with what devices were readily available.
Conditional computation, which was proposed (among other places) in 2016, was at first relegated to model development conversations. Now, however, there is a processor corollary that blends the best of those concepts with a novel packet processing method to displace traditional matrix math units. The team behind this effort blends engineering expertise from previous experiences building high-end CPU cores at ARM, graphics processors at AMD and Nvidia, and software and compiler know-how from Intel/Altera and might have something worth snatching us out of those “yet another AI chip startup” doldrums.
At this point in this chip startup space it takes actual differentiation to make waves in the neural network processor pond. What’s interesting about this effort, led by the startup in question, Tenstorrent, is that what they’ve developed is not only unique, it is answers the calls from some of the most recognizable names in model development (LeCun, Bengio, and Hinton, among others) for a reprieve from that matrix math unit stuffing approach that is not well-suited to neural network model sizes that are growing exponentially. The calls from this community have been for a number of things, including the all-important notion of conditional computation, freedom from matrix operations and batching, the ability to deal with sparsity, and of course, scalability.
In short, relying on matrix operations is so 2019. The ability to do fine-grained conditional computation instead of taking big matrices and running math does run into some walls. The real value is in being able to cut into the matrix and put an “if” statement in, removing that direct tie between the amount of required computation and the model size. Trying to do all things well (or just select things like inference or training) on a general purpose device (and even in some cases, specialty ones focused on just inference for specific workloads) there is much left on the table, especially with what Tenstorrent CEO, Ljubisa Bajic calls, the “brute force” approach.
But how to get around brute force when it’s…well, the most forceful? The answer is surprisingly simple, at least from the outside. And it’s a wonder this hasn’t been done before, especially given all the talk about conditional computation for (increasingly vast) neural networks and what they do, and don’t, need. For nearly every task in deep learning, some aspects are simple, others complex, but current hardware is built without recognition of that diversity. Carving out the easy stuff is not difficult, it’s just not simple with current architectures based on fixed sized inputs with high padding.
Tenstorrent has taken an approach that dynamically eliminates unnecessary computation, thus breaking the direct link between model size growth and compute/memory bandwidth requirements. Conditional computation enables adaptation to both inference and training of a model to the exact input that was presented, like adjusting NLP model computations to the exact length of the text presented, and dynamically pruning portions of the model based on input characteristics.
Tenstorrent’s idea is that for easier examples in neural networks, depending on the input, it’s not likely that all the neurons should be running but rather, one should be able to feed in an image and run a different type of neural network that’s determined at runtime. Just doing this can double speed in theory without hurting the quality of results much, but even better, if you’re redesigning the model entirely for conditional computation it can go far beyond that. It’s there where the solution gets quite a bit more complicated.
Each of the company’s “Grayskull” processors are essentially packet processors that take a neural network and factor the groups of numbers that make it up into “packets” from the beginning.
Imagine a neural network layer with two matrices that need to be multiplied. With this approach, from the very beginning these are broken into “Ethernet-sized chunks” as Bajic describes. Everything is done on the basis of packets from that point forward, with the packets being scheduled onto a grid of these processors connected via a custom network, partially a network on chip, partially via an off-chip interconnect. From the beginning point to the end result everything happens on packets without any of the memory or interconnect back and forth. The network is, in this case, the computer.
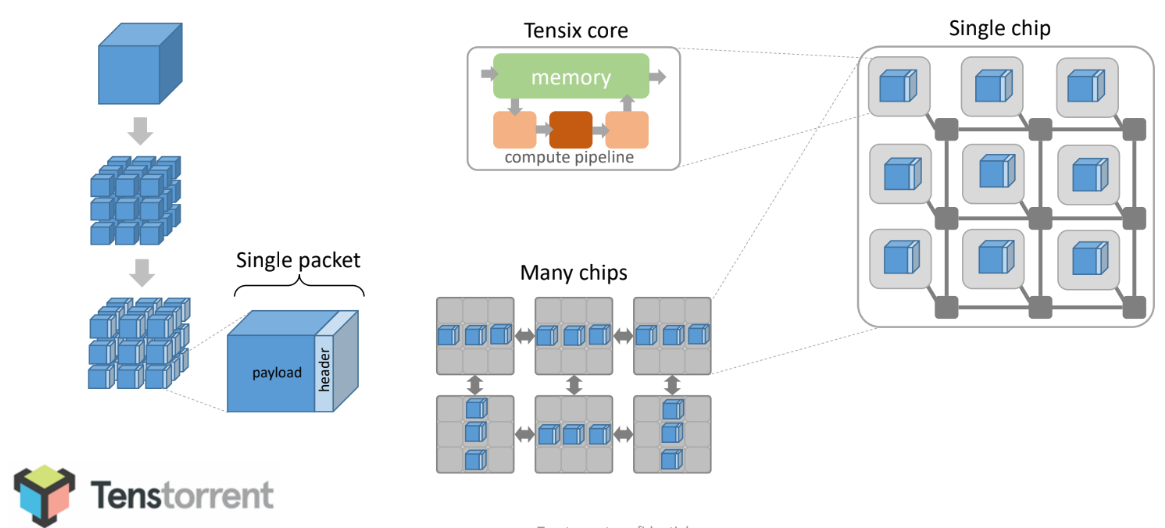
The blue square at the top is basically a tensor for numbers like input for a neural network layer. That gets broken into sub-tensors (those “Ethernet-sized chunks” Bajic referred to), which are then framed into a collection of packets. Their compiler then schedules movement of those packets between cores on one or multiple chips and DRAM. The compiler can then target (one or some of the chip) when the configuration is fed into it, to create a right-sized, scalable machine.
All of this enables changing the way inference runs at runtime based on what’s been entered, a marked difference from the normal compile-first approaches. In this world, we have to live with whatever the compiler produces so the ability to adapt to anything (including size of the input, an increasingly important concern) but this comes with a lot of wasted cycles with a lot of padding. Bajic uses a BERT example and says that input can vary from 3-33 words. Currently, everyone has to run a superset number but the brute force of making one-size-fits-all leaves quite a bit of performance and efficiency on the table.

The Tenstorrent architecture is based on “Tensix” cores, each comprising a high utilization packet processor and a powerful, programmable SIMD and dense math computational block, along with five efficient and flexible single-issue RISC cores. The array of Tensix cores is stitched together with a custom, double 2D torus network on a chip (NoC), at the core of the company’s emphasis on minimal software burden for scheduling coarse-grain data transfers. Bajic says flexible parallelization and complete programmability enable runtime adaptation and workload balancing for the touted power, runtime, and cost benefits.
“Grayskull” has 120 Tensix cores, with 120MB of local SRAM with 8 channels of LPDDR4, supporting up to 16GB of external DRAM and 16 lanes of PCI-E Gen 4. At the chip thermal design power set-point required for a 75W bus-powered PCIE card, Grayskull achieves 368TOPS. The training device is 300W. As clarification, each chip has 120 cores each with a single MB or SRAM. Some workloads can fit comfortably on that, others can pop out to DRAM (16GB/DDR4).
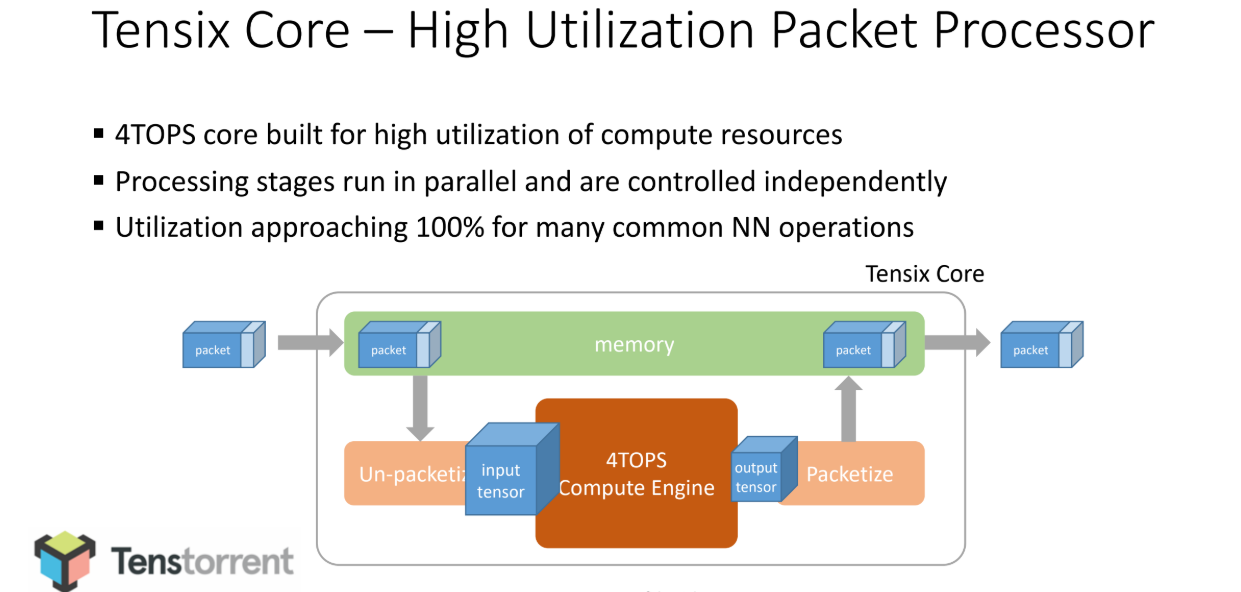
“In addition to doing machine learning efficiently, we want to build a system that can break the links between model size growth and memory and compute limits, which requires something that is full stack, that’s not just about the model but the compiler for that model. With current hardware, even if you manage to reduce the amount of computation you still need huge machines, so what is needed is an architecture that can enable more scaled-out machines than what we have today. Anyone serious about this needs to scale like a TPU pod or even better. The quick changes in models people are running now versus a few years ago demonstrate that zooming in on a particular workload is a risky strategy, just ask anyone who built a ResNet-oriented machine,” Bajic says.
“The past several years in parallel computer architecture were all about increasing TOPS, TOPS per watt and TOPS per cost, and the ability to utilize provisioned TOPS well. As machine learning model complexity continues to explode, and the ability to improve TOPS oriented metrics rapidly diminishes, the future of the growing computational demand naturally leads to stepping away from brute force computation and enabling solutions with more scale than ever before.”
There is still plenty to watch in the AI chip startup world, but differences are often minute and nuanced. This is indeed also nuanced but the concept is valid and has been demanded for years from hardware makers. What is also notable here, in addition to the team (Bajic himself worked on early Hypertransport, early Tegra efforts for autonomous vehicles on the memory subsystems side at Nvidia, and more, for instance) is that they have brought two chips to bear for $34 million in current funding (Eclipse and Real Ventures with private backing from what Bajic says is a famous name in the industry and in hardware startups) with “quite a bit” left over to keep rolling toward their first production chips in fall 2020.
Definitely one to watch. Bajic says he knows that the hyperscale companies are ready to try on anything that might be promising and knows that the AI chip startup space is crowded but thinks this approach is different enough in terms of what’s lies ahead for model size growth and complexity and what will be in demand when general purpose or matrix-based processors aren’t up to the task.


Tenstorrent Eyes Datacenter Deals With Another Star Hire From AMD
If Jim Keller makes a move, it’s best to watch closely. Even though the chip design legend’s tenure at Intel was cut short in 2020 due to family matters, Keller still made his mark at the semiconductor giant in a smaller but similar way he did for AMD, Apple and …

Unleashing An Open Source Torrent On CPUs And AI Engines
When you combine the forces of open source and the wide and deep semiconductor experience of legendary chip architect Jim Keller, something interesting is bound to happen. And that is precisely the plan with AI startup and now CPU maker Tenstorrent. Tenstorrent was founded in 2016 by Ljubisa Bajic, Milos …
Be the first to comment