

The announcement last fall that top Hadoop vendors Cloudera and Hortonworks were coming together in a $5.2 billion merger – and reports about the financial toll that their competition took on each other in the quarters leading up to the deal – revived questions that have been raised in recent years about the future of Hadoop in an era where more workloads are moving into public clouds like Amazon Web Services (AWS) that offer a growing array of services that many of the jobs that the open-source technology already does.
Hadoop gained momentum over the past several years as an open-source platform to collect, store and analyze various types of data, arriving as data was becoming the coin of the realm in the IT industry, something that has only steadily grown since. As we’ve noted here at The Next Platform, Hadoop has evolved over the years, with such capabilities as Spark in-memory processing and machine learning being added. But in recent years more workloads and data have moved to the cloud, and the top cloud providers, including Amazon Web Services (AWS), Microsoft Azure and Google Cloud Platform all offer their own managed services, such as AWS’ Elastic Map Reduce (EMR). Being in the cloud, these services also offer lower storage costs and easier management – the management of the infrastructure is done by the cloud provider themselves.
The Cloudera-Hortonworks hookup was embraced by many in the open-source community, but others saw it as an indication that the Hadoop market was no longer strong enough to support two major vendors. MapR Technologies was a key Hadoop vendor that over the past several years has worked to transform itself from a commercial Hadoop vendor to a data platform company. It created a data fabric model – its Converged Data Platform – that enterprises can leverage to consume huge amounts of data from such sources as tables, streams and files and make them available as a single pool of data.
However, MapR also is expanding beyond its Hadoop roots, most recently embracing containers, Kubernetes and other tools for collecting, managing and analyzing data. The company certainly isn’t abandoning Hadoop or giving into the idea that all data will eventually reside in the cloud. There are some trends at work that play into all this, according to Suzy Visvanathan, senior director of product management at MapR.
The first is that there is a large bucket of legacy applications that are being restructured to be cloud-native or to take advantage of microservices, containers and Kubernetes for container orchestration, Visvanathan tells The Next Platform. Enterprises will continue to restructure the legacy applications over the next several years before diving more deeply into building next-generation applications.
“They’ll end up just really building it from scratch. … They do have the budget to invest. The thinking here is becoming more and more proficient with,” she says. “It would be easier for them to build new ones. We’ll start seeing less of restructuring and reform.”
They’ll also adopt a multicloud strategy that includes using more than one public cloud. However, while many workloads will be sent to the cloud, some will come back on-premises, where organizations will still need the on-site capabilities for handling the data being created by these applications, Visvanathan says. The reasons for this are focused around security and control.
“The notion and perception that if I put my data in the cloud that I can no longer control it, manage it and configure it myself would be huge and could cause some of it to come back,” she says, adding that it could take years for businesses to find that balance between which workloads will live in the cloud and which will remain behind the firewalls of data centers or private clouds. “Of course, there’s nothing preventing more and more data and applications going to the cloud.”
The second trend is the one toward data science, Visvanathan says, one that is being overshadowed to some extent by the focus on the cloud but that could play a significant role in enterprises in the future as adoption grows in the coming years. Certainly some in the growing population of data scientists will find their way to cloud providers, but organizations will also bring data scientists on board, which in turn will grow their own in-house data management expertise and play a role in keeping some data and applications on-premises and again will drive the need for tools like Hadoop, containers and Kubernetes.
MapR will play a role in whatever courses customers choose, whether it’s in the cloud or on-premises, she says. The company over the past year has been building up its capabilities with containers and Kubernetes, including with the introduction in February of version 6.1 of the MapR Ecosystem Pack, which included the implementation of the Container Storage Interface (CSI) for Kubernetes, giving persistent storage for compute running in containers managed by Kubernetes.
In June 2018 the company announced support for AWS’ Elastic Container Service for Kubernetes, enabling enterprises to manage their data both on-premises and in AWS. Three months earlier, MapR further drove container integration into its Converged Data Platform with the introduction of MapR Data Fabric for Kubernetes, easing the challenges of containers by offering easier access to data across clouds and on-premises deployments.
The company this month took another step in making its MapR Data Platform more container- and Kubernetes-friendly by making it easier for enterprises to deploy Drill and Apache Spark applications in Kubernetes. MapR is separating the compute and the storage, enabling enterprises to scale compute as needed without the costs and complexity of having to correspondingly scale the storage as well. This will make it easier for customers to manage these highly elastic Spark and Drill workloads as well as applications that leverage artificial intelligence (AI) and machine learning techniques, which Visvanathan notes “can be bursty in nature. We’re also offering all of these features that could be run on any environment that they prefer. They can run it in their on-prem data center, the edge or the public cloud.”

Many organizations know that Kubernetes is an important tool when adopting containers, but few have a firm understanding of how to manage Kubernetes, she says. MapR’s goal is to make it easier for enterprises to run Kubernetes by providing deeper integration into its own Data Platform and lifting many of the tasks of running the orchestration tool off their shoulders. Separating the compute and storage is a key to that.
“Historically, big data has been deployed on environments where the computer and storage were co-located and the premise behind that was in order to achieve data locality and to achieve the lowest latency possible, you want to keep them both together,” Visvanathan says, adding that there is growing demand to keep “compute independent from storage. It has grown quite significantly to where there is no longer a one-to-one correspondence between compute and storage.”
She outlined several use cases that are impacted by this need for greater elasticity. Enterprises are building next-generation applications and also creating huge data lakes for hybrid cloud environments. At the same time, they also are embracing multicloud strategies in which they’re putting applications in more than one public cloud. All of these demand easy container management and easy scaling, and MapR will address all of them, Visvanathan says.
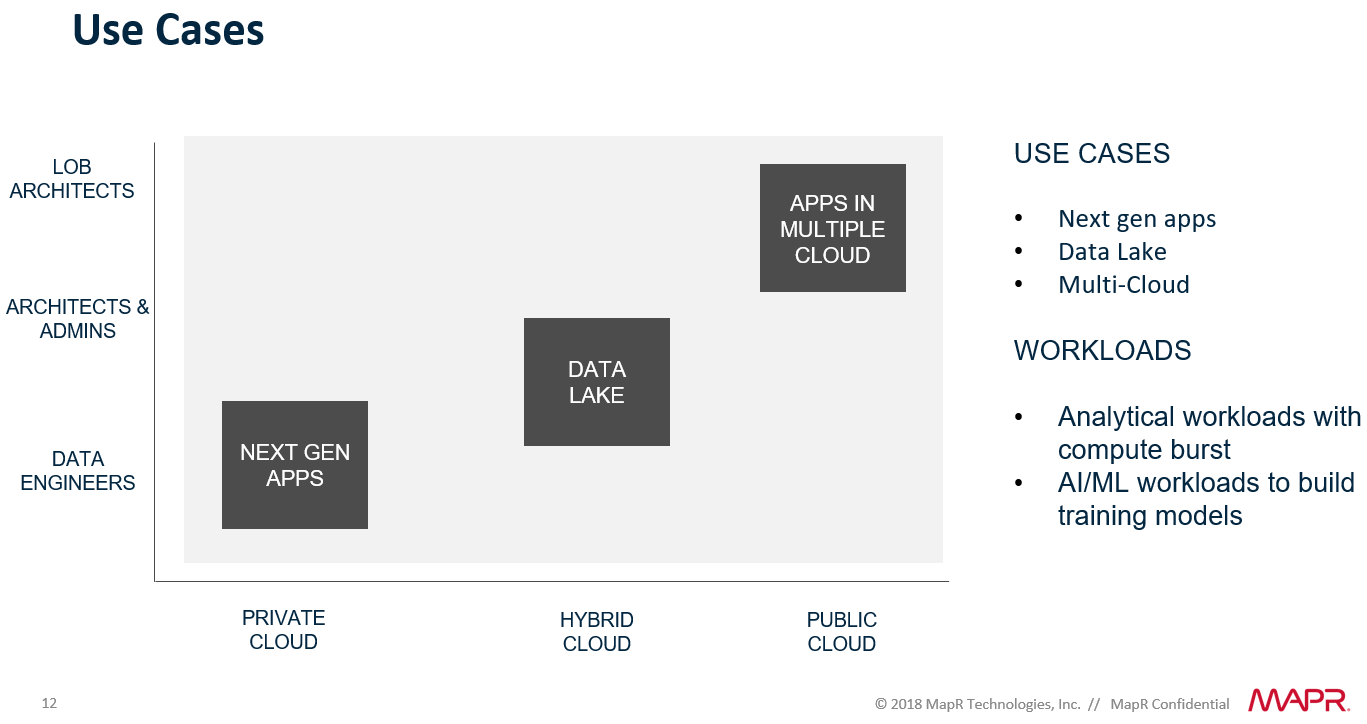
“If they are building next-gen apps, we are there, making it easy for them,” she says. “For those who are moving to the cloud and having that be orderly, we are supporting this in any development model and breaking compute and storage out so you can move to the cloud easily. We are also going another step forward and saying that most of these folks who have different use cases will invariably end up building a data lake, so when you’re there, we have all the tools where all those lines of businesses meet.”
The latest Data Platform release will be available this quarter.


Why the Fortune 500 is (Just) Finally Dumping Hadoop
Remember how, just a decade ago, Hadoop was the cure to all the world’s large-scale enterprise IT problems? And how companies like Cloudera dominated the scene, swallowing competitors including Hortonworks? Oh, and the endless use cases about incredible performance and cost savings and the whole ecosystem of spin-off Apache tools …

Getting Hadoop to Jump Through AI/ML Hoops
Just a decade ago, the enterprise IT push was to make Hadoop the platform for storage and analytics. At that time, cloud hesitancy was still looming for large on-prem organizations. Hadoop, no matter how that ecosystem played out over the years, became a major source of investment with the idea …
Cloudera Pivots To Data Management As Hadoop Fades
It was only two years ago that Cloudera, once one of the top vendors in what had been a white-hot Hadoop market, found itself fighting for survival. Hadoop, the open-source data analytics technology that a decade ago was seen as the answer to enterprises’ large-scale data analytics and management woes, …
Love MapR. We use it for device data collection and have seen a huge increase in performance. Hope to deploy 6.1 before the fall.