

The enormous amount of data being generated will do companies little good if they can’t more easily gather it from multiple sources, store it, analyze it and gain important insights into it that will help them drive better business decisions. There are myriad challenges to all this, starting with the sheer amount of data that is being created. The data also is coming from many different sources, is at rest and in motion, is created on-premises, in the cloud, and at the network edge, and is ruled by different data governance policies.
For the past several years, MapR Technologies has been undergoing a transformation from a commercial Hadoop distributor to a data platform company that offers a data fabric model that enables users to take large volumes of data from multiple sources – such as tables, streams and files – consume them once and then make them available to customers as a single pool of data. With the release this week of its Converged Data Platform 6.0, MapR is aiming to make it easier to manage data both at rest and in motion and to ensure the health and protection of the platform itself.
The update is in service to what MapR is tagging as DataOps teams, a variation of the DevOps application development practice that includes not only developers but also data scientists and data engineers. By integrating operations and analytics, businesses can more quickly derive benefits from all the data coming into their environments. To do that, businesses need both to have the data in place as well as the skillsets to manage the data. Key to that is ensuring that all the data is brought together and made available quickly.
“Organizations are trying to turn data into value,” Mitesh Shah, senior technologist of industry solutions at MapR, told The Next Platform. “Many are trying to do that more quickly and turn that into as much value as possible, moving faster than their competition. Data scientists should be able to tap into data on day zero. They shouldn’t have to wait for data to be stitched together.”
Speed is important. It can take data scientists weeks to find the data they need, clean it and then analyze it. The process needs to be faster, and new capabilities within Converged Data Platform 6.0 are designed to accelerate it, Shah said. Included in the latest version of the platform is MapR-DB, a database feature introduced in September that includes enhanced support secondary indexes and automation in applications, integrated machine learning and real-time processing. It also includes Open JSON Application Interfaces (OJAI) 2.0 APIs. Through MapR-DB, users can quickly ingest data into the platform for storage, processing and analytics. Changes made to the data are propagated throughout the MapR system, he said.
Through its recently announced Data Science Refinery technology, MapR offers self-service access to all the data within the same cluster and within MapR’s platform through connections with such offering as MapR-DB, MapR-XD cloud-scale data store, and MapR-ES event streaming offering. It supports Apache Spark, Apache Hive, Apache Pig and Python, and is easy to deploy via Docker containers. MapR’s new Changes Data Capture feature integrated with MapR-DB and MapR-ES to help keep track of changes in the database or the data stream and then takes steps to address those changes.
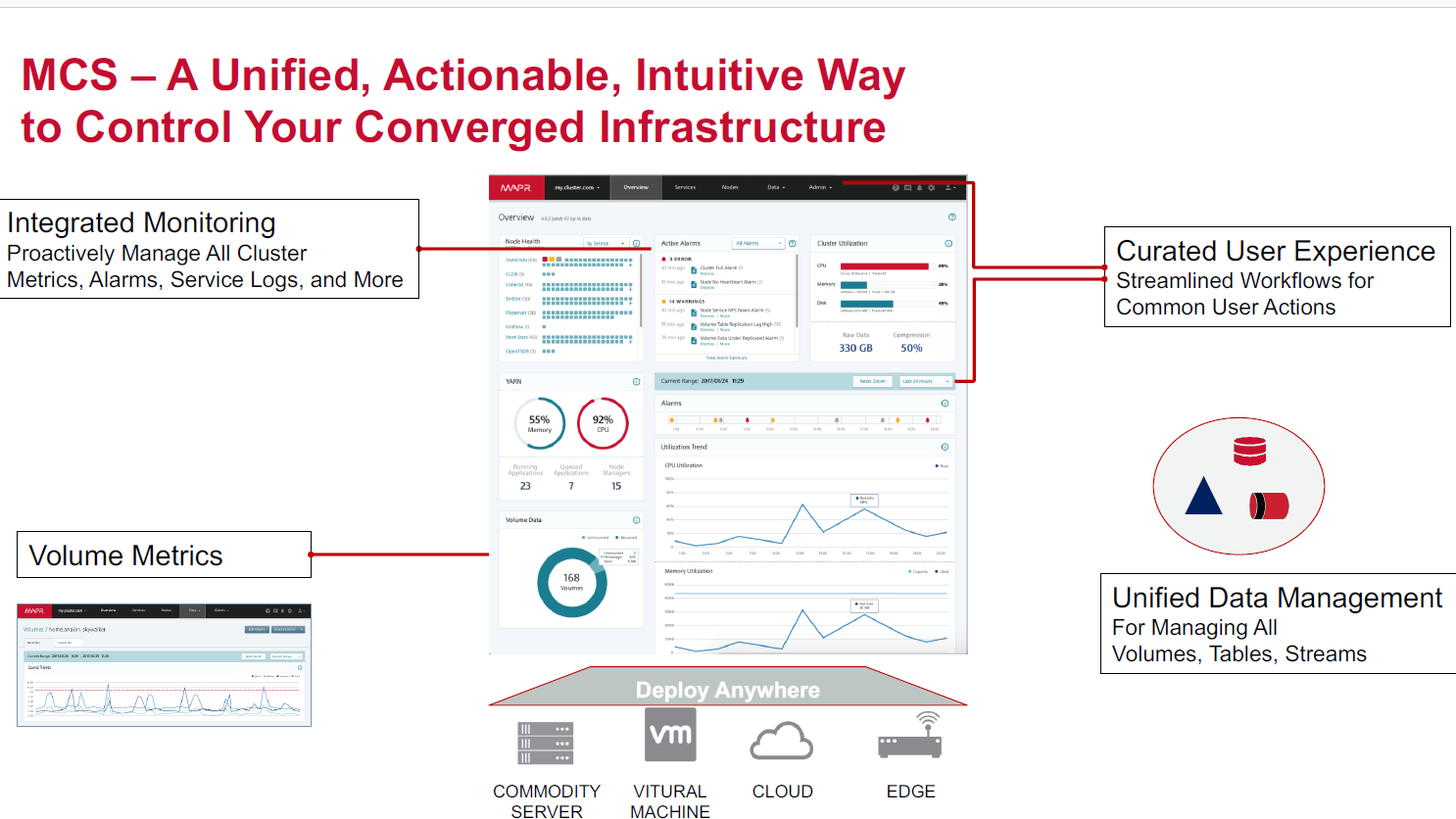
The vendor also is including automatic platform health and security capabilities. The MapR Control System (MCS) manages the data gathered from volumes, tables and streams and monitors the health of clusters through a single view. It includes dashboards for measuring various metrics, including throughput, capacity, latency and IOPs, and the metrics are pushed to MapR-ES for integration with enterprise systems. Also included is the recently announced database indexing capabilities.
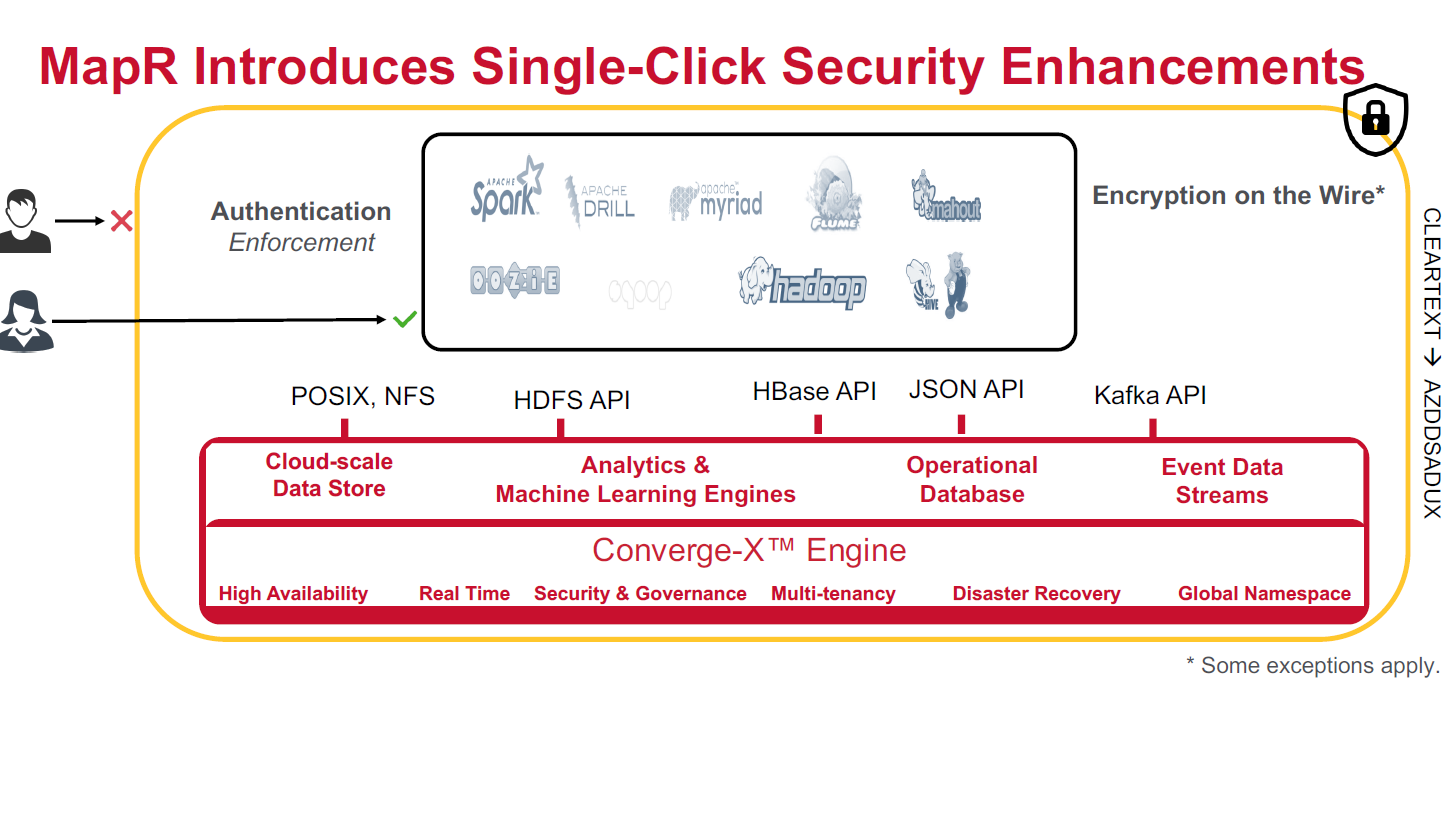
Through what MapR calls single-click security, Converged Data Platform 6.0 delivers faster authentication enforcement and standard encryption on the wire. Ensuring security in such a board data environment, Shah said. The goal of these security capabilities is to help customers increase security through “a simple toggle switch,” he said. Authentication is applied across a series of big data tools, including Hadoop, Spark, Drill, Mahout and Oozie.
“There are a lot of moving parts in the platform,” Shah said, noting the challenges of trying to apply security to each one of those parts individually. “We are trying to make it easier with this switch.”
 Also new in the platform are enhancements to the MapR Orbit Cloud Suite for cloud-scale multitenancy, a MapR OpenStack Manila plug-in to enable self-service provisioning of files by tenants, and real-time automatic movement of files from the edge to the cloud.
Also new in the platform are enhancements to the MapR Orbit Cloud Suite for cloud-scale multitenancy, a MapR OpenStack Manila plug-in to enable self-service provisioning of files by tenants, and real-time automatic movement of files from the edge to the cloud.
Converged Data Platform 6.0 is available now, with cloud providers like Amazon Web Services, Microsoft Azure and Oracle Cloud making it available through their marketplaces by the end of the year.

Everybody Has Big Data – How To Cope With It
Enterprises are awash in data, and though many are tempted to save it all for later analysis – after all it worked for Google for many years – the store then analyze approach is poorly suited to environments with data sources that never stop. Storing all data is costly if …
The Opposite Of Snowflake: Analytics Without The Data Warehouse
As we have pointed out before, large enterprises have to deal with a different kind of scale issue than the hyperscalers, and in many ways, the hyperscalers have it easier. The hyperscalers have dozens of core applications that they have to run at massive data scale – pushing up to …

Why the Fortune 500 is (Just) Finally Dumping Hadoop
Remember how, just a decade ago, Hadoop was the cure to all the world’s large-scale enterprise IT problems? And how companies like Cloudera dominated the scene, swallowing competitors including Hortonworks? Oh, and the endless use cases about incredible performance and cost savings and the whole ecosystem of spin-off Apache tools …
Be the first to comment