

It is safe to say that a little more than a decade ago, when the clone of Google’s MapReduce and Google File System distributed storage and computing platform was cloned at Yahoo and offered up to the world as a way to transform the nature of data analytics at scale, that we all had much higher hopes for the emergence of platforms centered around Hadoop that would change enterprise, not just webscale, computing.
It has been a lot tougher to build the road to enterprise customers and therefore profits, and the reason is simple. Databases are extremely sticky and very hard to change, even when the promise of extremely cheap storage – at least by the standards of the mid-2000s – is dangled like a juicy carrot. Hadoop, which became the name of a collection of mostly open source programs dealing with data storage and analytics at scale, has been brilliantly and carefully evolved into a number of different platforms by the likes of Cloudera, Hortonworks, MapR Technologies, and even IBM for a while.
But Hadoop has remained a complex if sophisticated platform aimed at the upper echelons of computing, suitable for the Global 5000 customers that were once on the bleeding edge, four or five decades ago, with IBM mainframes for transaction processing. The pace of technological change has accelerated much faster than Moore’s Law, and there are so many ways to skin the analytics cat that it is, frankly, as ridiculous as it is exciting and interesting. Enthusiasm tends to run ahead of practicalities, which is why old technologies persist. The question we have as we contemplate the merger between Cloudera and Hortonworks, arguably the largest commercial distributors and the only two who have made it to public offerings to investors on Wall Street, is whether or not their momentum is enough that Hadoop will be able to evolve and become a profitable business.
That is the central question, and while one might argue that merging two customer bases, two code bases with different licensing philosophies and some radically different approaches to storing and querying data, and two distinct companies so they stop fighting each other will make for a better and stronger Hadoop platform. It is certainly not a foregone conclusion that Hadoop as a business is as good as Hadoop as a platform, and the whole premise of a commercial open source distribution is that it has to be a good business so the platform can be reinvested in to keep it improving and evolving.
There are very few platforms that have succeeded in this regard, and Red Hat, with its Linux server, JBoss application middleware, OpenStack cloud controller, and OpenShift Kubernetes container orchestrator, is really the only good example worth bringing up from the open source realm. Nothing else even comes close. If Red Hat had created a Hadoop distribution, as many of us thought it should have, or bought one, as it certainly could have, it is probable that Cloudera and Hortonworks would have never become public companies, which allowed their investors, who collectively plowed $1.04 billion into the former and $248 million into the latter, to cash out. (Intel’s $740 million infusion into Cloudera in 2014 was just an example of the hubris and folly that the chip giant can indulge in thanks to its virtual monopoly in PC and server chips. It happens to all big tech companies that create large profit pools. This list of such acquisitions and partnerships by IBM is long, just as an example.)
As a venture capital harvesting machine, Hadoop has been brilliant. Don’t get us wrong. And from the humble beginnings of the MapReduce data chunking and chewing algorithm and the Hadoop Distributed File System, the Hadoop platform has grown into a vast ecosystem of tools that mirrors all of the wonderful things that have come to surround the Linux kernel and turned it into a proper operating system that can span everything from a smartphone to a supercomputer. Hadoop is ornate, and sometimes baroque, and has so many variations on the themes for everything from data storage to SQL and other kinds of database and data warehouse overlays to different distributed computation models to a layer for in-memory processing and machine learning. It is a very large Swiss Army knife. That is Hadoop’s best feature, and it has also been its curse. Perhaps now, with the two largest Hadoop players merging, the Hadoop stack can be pruned a bit and better optimized for the workloads of the 2020s.
That, we presume, is the idea behind the merger between Cloudera and Hortonworks. The two companies also want to remove costs and probably remove some of the intense competition on pricing to get the combination to profitability, as is expected from every public company. (Will it be called CloudWorks? HortonEra? Something different? Or just Cloudera? Probably not Hortonworks.) And it looks like the combined Hadoop distributions have a path to profitability, if the trend lines hold.
That said, these two companies have burned through a tremendous amount of money to get here, and in the past six and a half years where we have visibility into the numbers, the businesses have indeed grown, but at tremendous cost. Both Cloudera and Hortonworks had models that showed they would grow a lot faster than they actually did, and the slower growth has pushed out the point of profitability ahead of them every year. Adding more and more blades to the Hadoop Swiss Army knife has been costly, and to their credit, they have done innovative things that have kept Hadoop relevant as conditions in the market have changed dramatically in the past decade. What they are trying to do is extremely difficult, and we have nothing but tremendous respect for the effort that some of the smartest people we know in infrastructure and business have put in. But the numbers are not pretty, even if they are getting rosier here in 2018 and looking out into 2019 and 2020.
In fact, it might have been better for these two companies to have merged a few years back, cleaned everything up, got the synergies reckoned, and be going public right now.
Cloudera got the early jump as the dominant revenue generator of the Hadoop stack, but in recent years, Hortonworks has been catching up fast. Take a look:
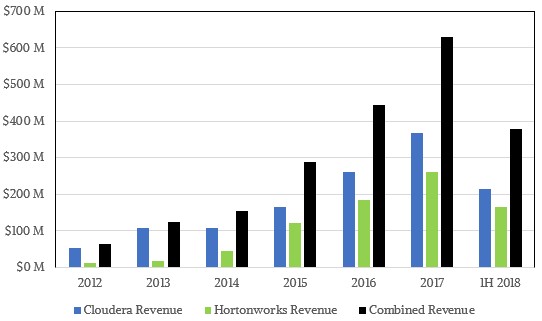
The bars at the far right show figures for the first half of calendar 2018, so don’t mistakenly think revenues have dropped.
Here is our analysis in tabular form, so you can see the numbers yourself:
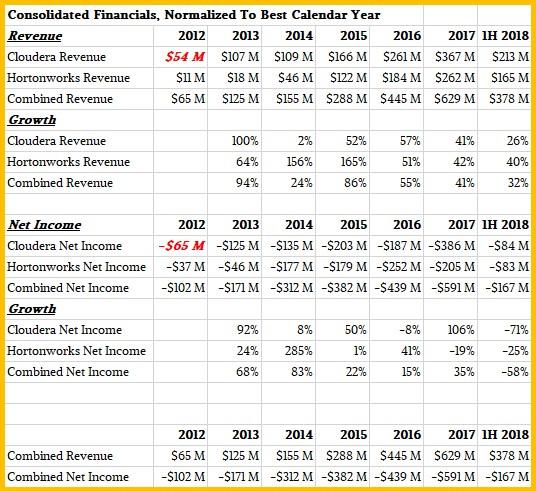
Clearly sales growth has cooled for Cloudera – it only grew 26 percent in the past two quarters compared to the same period 12 months earlier and down from the 42 percent growth rate in 2017 – while Hortonworks is still humming along at 40 percent growth here in 2018 thus far. The combined companies is probably the best way to reckon the overall growth rate, and for the first half that is 32 percent growth for $378 million in sales. There is no reason to believe that the combination cannot break through $800 million in sales in calendar 2019 and push up through $1 billion in 2020.
If you do the math, Cloudera has raked in $1.28 billion in revenues in the past six and a half years, while Hortonworks only brought in $808 million. Add in the venture capital of $1.31 billion in venture capital, plus $225 million that Cloudera raised in early 2017 for its IPO and the $100 million that Hortonworks raised in late 2014 from its IPO, and the total pile of cash that has come to the pair is $3.69 billion. Hortonworks still has $86 million of cash and Cloudera still has $440.1 million. But over that same time period, Cloudera has booked cumulative losses of $1.19 billion and Hortonworks has cumulative losses of $979 million, for a total of $2.16 billion. Both separately and together, these companies are burning the wood a lot faster than they can cut it. This chart shows it visually:
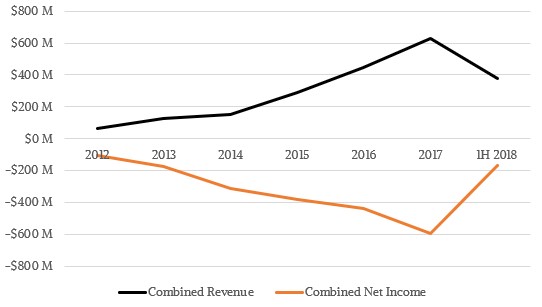
But the financial situation is getting better, as the data shows. The Cloudera and Hortonworks presentations accompanying the merger announcement use trailing twelve month data, which is suitable but we mixed the quarterly data above because it has a longer trend line. Here is what the profit top-level financials look like:
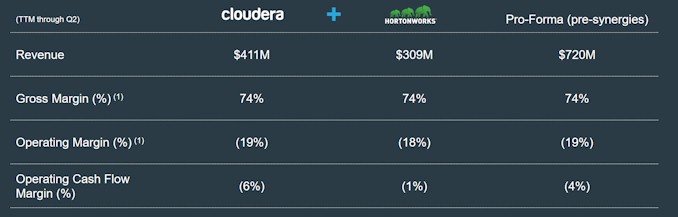
The combined companies, on a trailing twelve month basis, have $720 million in revenues, and gross margins are pretty good at 74 percent. A software company with a legacy installed base can pull in 85 percent to 95 percent gross margins, and aside from the elimination of redundant costs and other synergies that Cloudera and Hortonworks are talking about eliminating, the reduction in competition is going to help, too. No one is talking about that, of course, but that is no doubt part of the thinking behind the merger. There is some cross-selling that is possible to boost revenues, but we think the reduction in competition is a bigger deal. Rationalizing the very different licensing models – Hortonworks is pure open source with subscription support, while Cloudera is open core with support plus enterprise add-ons with subscription licenses for key features – is not going to be easy, and many products and projects will have to be merged or picked one over the other. Still, even with the $125 million in synergies removed, the combined company will move closer towards profitability, and with a reasonable 30 percent revenue growth rate, the new entity should break through $1 billion and be profitable in 2020. And that is precisely the plan:
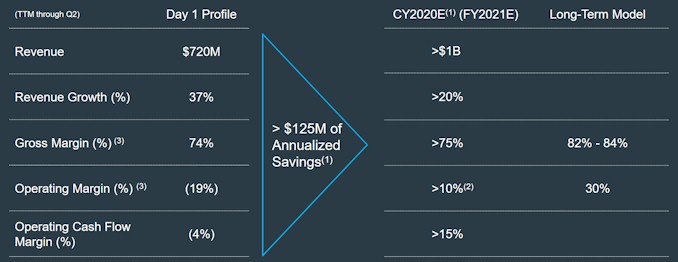
To be precise, the combined Cloudera-Hortonworks is telling Wall Street that it can get above $1 billion in sales and have gross margins about 75 percent and operating margins above 10 percent for calendar 2020. Which implies that it will have actual profits, if all goes well.
The total addressable market is expanding, too, and that will help. Here is how Cloudera and Hortonworks see the opportunity out in front of them:

The core market that Hadoop is chasing is comprised of three different segments, according to Cloudera-Hortonworks, and will grow at a compound annual growth rate of 21 percent between 2017 and 2022, from $12.7 billion to $32.3 billion. Within that, cognitive and artificial intelligence workloads represent a $14.3 billion opportunity in 2022, $4.9 billion for advanced and predictive analytics software, and $13.2 billion for dynamic data management systems (what we would call modern storage). In addition to that, the Hadoop platform is also chasing relational and non-relational database management systems and data warehouses, which is another $51 billion opportunity in 2022, for a total TAM of $83 billion. Even a small slice of this, which is what Hadoop currently gets today, could be billions of dollars by then. (We shall see.)
The deal for the merger of the two companies is surprisingly simple. Shareholders in Hortonworks will get 1.305 shares in Cloudera and Cloudera will be the remaining company in fact, if not necessarily in name. This means that Cloudera shareholders will own 60 percent of the combined company and Hortonworks shareholders will own the remaining 40 percent. The combined companies had a fully diluted equity value of $5.2 billion before the merger was announced. At the time the deal was announced, the combined firms had more than $500 million in cash, no debt, and 2,500 customers who largely do not overlap. There are more than 120 customers who spend $1 million a year and another 800 customers who spend more than $100,000 a year for subscriptions and such.

Cloudera Pivots To Data Management As Hadoop Fades
It was only two years ago that Cloudera, once one of the top vendors in what had been a white-hot Hadoop market, found itself fighting for survival. Hadoop, the open-source data analytics technology that a decade ago was seen as the answer to enterprises’ large-scale data analytics and management woes, …

The Endless Pursuit Of Scale At LinkedIn
There is nothing at all wrong with legacy application and system software as long as it can deliver scalability, reliability, and performance. Changing from one software stack to another is so difficult and so risky — the proverbial changing of the front two tires on the car while going down …
The Opposite Of Snowflake: Analytics Without The Data Warehouse
As we have pointed out before, large enterprises have to deal with a different kind of scale issue than the hyperscalers, and in many ways, the hyperscalers have it easier. The hyperscalers have dozens of core applications that they have to run at massive data scale – pushing up to …
Not one mention of the cloud vendors? There’s currently a mass migration of Enterprise data from on-premise to “the cloud”, and while some data will always be hard to move (for security or legal reasons), Hadoop-based analytics projects are a natural fit for offloading to cheap object storage with on-demand compute. Both Cloudera and HWX were too late to the cloud party (Cloudera especically so) with the real risk now that Amazon and Microsoft will suck up the big data market before they ever reach profitability. Merging two “legacy” vendors for better economic scale in the face of a disruptive technology is a classic corporate tactic, but usually just delays the inevitable.
There are a lot of downsides to moving to the cloud for these workloads, so adoption has been slow, if at all.
I believe its a meaningless merger in the overall grand scheme of things
I would like to see more written on MapR. Their software is very good and is much more suitable for running real production workloads. My guess is that they spend less on marketing so they can invest in the product, and it shows.