

The year ahead for high performance computing promises some interesting twists and turns.
But we think two of the more defining developments for 2019, at least on the hardware side, are the beginning of a realigned processor market and the final sprint toward exascale supercomputers.
AMD and Intel Square Off in the HPC Arena
Let’s start off with the 800-lb gorilla in the room, Intel. Its chips are used in well over 90 percent of the HPC systems on the planet, which has been the case since the downfall of the AMD Opteron. While that may not change appreciably in 2019, AMD has its best chance in more than a decade to gain HPC market share at Intel’s expense.
![]() That’s mainly because, for the first time in history, this year AMD will be offering server silicon with smaller transistors than its arch rival. Rome, AMD’s second-generation Epyc processor, will be etched with Taiwan Semiconductor Manufacturing Corp’s (TSMC’s), 7nm process technology, while Intel will be offering its Xeons in the form of Cascade Lake-SP and the HPC-tweaked Cascade Lake-AP chips with 14nm transistors. Intel is not expected to ship Xeon CPUs with 10nm technology (which is roughly equivalent to TSMC 7nm) until 2020. That will give AMD at least a year-long window with an advantage it’s never had before.
That’s mainly because, for the first time in history, this year AMD will be offering server silicon with smaller transistors than its arch rival. Rome, AMD’s second-generation Epyc processor, will be etched with Taiwan Semiconductor Manufacturing Corp’s (TSMC’s), 7nm process technology, while Intel will be offering its Xeons in the form of Cascade Lake-SP and the HPC-tweaked Cascade Lake-AP chips with 14nm transistors. Intel is not expected to ship Xeon CPUs with 10nm technology (which is roughly equivalent to TSMC 7nm) until 2020. That will give AMD at least a year-long window with an advantage it’s never had before.
Conventional wisdom says transistor size doesn’t matter so much these days; processor design is much more important. But even in the waning days of Moore’s Law, fundamentals still matter. Some of Rome’s improved specs can be certainly be attributed to design innovation, but having smaller transistors to work with gave AMD a lot more options.
For example, the 7nm Rome CPU will sport up to 64 cores, while the core count for the 14nm Cascade Lake processor will top out at 48. More significantly, AMD is saying Rome will be four times as fast in the flops department as its first-generation Epyc, while Intel is claiming only a 21 percent bump from Skylake-SP to Cascade Lake-AP (with Linpack as the metric). Keep in mind that the Skylake Xeon is more than twice as fast as the original Epyc at executing floating point operations, but if both vendors’ performance claims hold up for their respective next-generation chips, AMD could very will end up with the floppiest server CPU in 2019. And its conceivable that those CPUs could even be less expensive than their slower competition.
Expectations of AMD’s renewed competitiveness is already being felt. Toward the end of 2018, Rome notched a couple of big supercomputer wins. The first is a 2.4-petaflop HPE-built system for the High-Performance Computing Center (HLRS) of the University of Stuttgart, which is slated for installation at the end of this year. The other is a 6.4-petaflop BullSequana system for the Finnish IT Center for Science. It’s that is expected to be installed by Atos in 2020. We expect Rome will turn up in a growing number of HPC systems, large and small, throughout 2019. Unless AMD has a major hiccup, 2019 is going to be a watershed year for company in the high end of the market.
Arm will make some inroads in HPC in 2019, but more than likely they will be modest. The first petascale Arm-powered supercomputer, Astra, garnered a spot on the TOP500 list in November 2018, but was the only Arm machine to do so. Astra, like a handful of other Arm-powered clusters in the field all rely on Marvell’s (previously Cavium’s) ThunderX2 processors. It is currently the only commercial Arm implementation designed for HPC systems and it suffered from an agonizingly slow rollout. Initially unveiled in 2016, ThunderX2 wasn’t released into the wild until 2018.
All the currently deployed ThunderX2 HPC systems, even the Astra supercomputer at Sandia National Laboratories, are, to one extent or another, testbed systems for evaluating Arm running HPC workloads. It’s entirely possible that the first production Arm supercomputer will be Japan’s Post-K supercomputer (see below), which isn’t scheduled to be up and running until 2021. In the meantime, we expect to see a lot more Arm-powered systems to be trialed at various national labs and research institutes in 2019, but nothing on a scale that would change the dominance of x86 at the high end of the market.
That said, Arm’s long-term prospects in high performance computing are rather good. Arm Holdings is taking an active interest in high-end computing by helping to build out the software and hardware ecosystem, while HPC vendors like HPE, Atos, and Cray all now offer ThunderX2-powered options. Plus, thanks to the licensing model, the technology is both accessible and malleable, which makes it very suitable for co-design and more customized implementations for HPC. Just don’t expect any miracles in 2019.
The Market Stakes Out Exascale Territory
With the first exascale systems expected to come online in the next year or two, supercomputer vendors are gearing up to get their entries into the field. In China, Europe and Japan, the developers are pretty much set. Oddly enough, it’s the US vendors that have yet to be decided on.
In China, Sugon, the National University of Defense Technology (NUDT), and the National Research Center of Parallel Computer Engineering and Technology (NRCPC) are building the first trio of exascale systems for that country. Sugon is in line to develop China’s x86-powered exascale supercomputer, which apparently will be based on a licensed AMD Epyc implementation plus DCU accelerators, both of which will be supplied by Chinese chipmaker Hygon. NUDT is responsible for Tianhe exascale system, which is expected to be powered by an Arm processor of some sort, possibly a Phytium Xiaomi chip, but that might have changed. The third system will be developed by NRCPC and will be based on some future ShenWei processor.
In 2018, all three developers put pint-sized prototypes (512 nodes) of these exascale systems into the field. The basic componentry in these prototypes – processors, network, and memory – is not exascale-ready, so will have to go through at least one more iteration. As a consequence, if any of these developers are expecting to install a full-up exascale supercomputer in 2020, which was the original goal of the Chinese government, they are going to have step up their game.
Given the current absence of pre-exascale deployments in the country – a system that delivers hundreds of petaflops — and the lack of legacy experience with semiconductor technology, it seems unlikely that the first Chinese exascale machine will come online next year. At this point, 2021 or 2022 seems like a more reasonable target. By the end of 2019, we should have a better sense of where these projects stand, assuming of course that the work continues to be made public.
In some ways, Europe is now following the Chinese exascale approach, inasmuch as they are using the opportunity to develop their own domestic HPC processors. In this regard, the key effort is the European Processor Initiative (EPI), a project whose goal is to develop home-grown chips for the local market – not just for HPC machinery, but also for the automobile market and the wider server and cloud space.
Even though the EPI project kicked off last June, the technical direction already appears to be well established. The plan is to develop an Arm chip as the general-purpose processor and use open-source RISC-V architecture as the basis for the HPC accelerator. The first generation of these processors are slated to end up in pre-exascale systems in 2021 and could be taped out as early as the end of this year. The second-generation chips will go into exascale systems that are scheduled for installation in 2023 to 2024. In any case, we should get some notion of the chip designs for both the Arm and RISC-V implementation in 2019. The latter will represent the world’s first implementation of RISC-V for HPC.
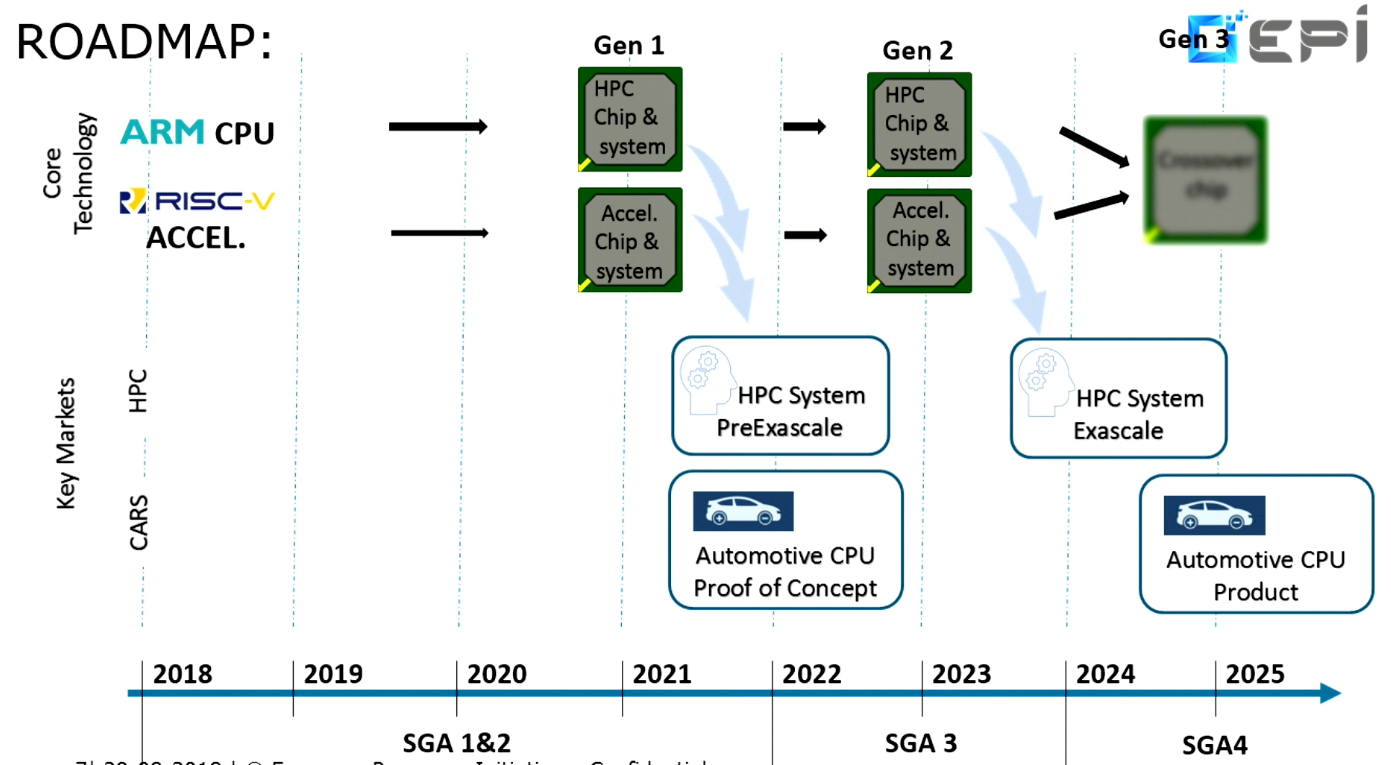
The EPI consortium is made up of 23 members, but the key commercial organization is Atos, which will be the system integrator and the lead for the development of the general-purpose processor. The Barcelona Supercomputer Center (BSC) will head up the accelerator work.
Compared to China or Europe, the plan for Japan’s initial exascale supercomputer, known as Post-K, is downright simple. Fujitsu is the prime contractor for both the system itself and the processor that will power it. The system is on track to be installed at RIKEN in 2021.
Post-K is the exascale update of the K computer, with a spiffed-up Tofu interconnect and a swap-out of Sparc64 processors with Arm silicon. Last year, Fujitsu unveiled its Arm implementation, the A64FX, a 64-bit Arm8.2-A processor outfitted with the Scalable Vector Extension (SVE) addition that is specifically designed for HPC duty. We expect the chip will undergo one more iteration between now and its exascale debut in two years.
In the US, things are a bit more up in the air. While the first US exascale supercomputer, known as Aurora/A21, is already set to be built by Intel and Cray for the Department of Energy’s Argonne National Lab in 2021, there is very little known about the details of the machine (although we offer some speculation here, here, and here). A21 will almost certainly be a Cray Shasta system of some sort, but with what componentry from Intel?
With any luck, sometime in 2019 Intel will reveal at least the processor (or processors) used to power A21 and if it has decided to forge ahead with its second-generation Omni-Path interconnect. The company’s roadmaps for Xeon, their AI portfolio, and their dataflow accelerator appear to be filling out, so we may see the end to all this secrecy from Intel in the next few months.
The DOE is also funding two or three other exascale supercomputers that will follow the A21 deployment. This is being done under the contract known as CORAL-2 (Collaboration of Oak Ridge, Argonne, and Lawrence Livermore Labs). CORAL-2 will fund the first exascale computers for Oak Ridge National Laboratory (ORNL) and Lawrence Livermore National Laboratory (LLNL) plus a potential third system to be deployed Argonne National Laboratory (ANL). The Argonne machine could be an upgrade to the A21 supercomputer or a new installation altogether. ORNL is scheduled to install its system in the Q3 of 2021, followed by the LLNL system in Q3 of 2022. If the Argonne option is exercised that machine will also be deployed in the third quarter of 2022.

None of the vendors for these two or three systems are known, but the most likely candidates are the ones with pre-exascale systems in the field, that is, IBM, NVIDIA, and Mellanox; or the A21 vendors, Cray and Intel. On the other hand, HPE and AMD have a good shot at upsetting the incumbents, either as the system vendor in the case of HPE, or as a CPU or GPU provider in the case of AMD. Marvell is perhaps a longer shot with a third-generation ThunderX Arm CPU. Although all the CORAL-2 systems are three or four years away, the awards should be announced in the first half of 2019.
As a result, before the end of the year, we should have a pretty good picture of the early exascale landscape around the world – which vendors will be building the initial systems and what processors, accelerators, and interconnects will be used to power them. And maybe even who will reach the milestone first.

TSMC Makes The Best Of A Tough Chip Situation
If you had to sum up the second half of 2022 and the first half of 2023 from the perspective of the semiconductor industry, it would be that we made too many CPUs for PCs, smartphones, and servers and we didn’t make enough GPUs for the datacenter. Or rather, Taiwan …
Liqid Launches Its Own Systems, Chases AI And HPC
To hardware or not to hardware, that is a real question for vendors peddling all kinds of software in the datacenter. To get a bigger slice of the revenue and to help accelerate its installations, composable infrastructure and switch maker Liqid is grabbing the hardware bull by the horns and …
Why The UK Should Have Its Own Exascale AI/HPC Machine, And How
We were away on vacation at a lakeside beach in northern Michigan when we caught the news that the UK government was pulling the plug on a plan for an exascale supercomputer to be installed at the EPCC at the University of Edinburgh. And then we caught COVID – because …
“…AMD is saying Rome will be four times as fast in the flops department as its first-generation Epyc…”
Context is important here, as the 4x increase is at the socket level, so the per core increase is 2x.
For perspective look at the Top500 list and you’ll understand that they are only matching the peak theoretical performance of the SuperMUC-NG with the brand new HAWK super computer. The HAWK system is reported to have 640k cores, versus Intel only having 305k.
Rome will win some deployments, but it isn’t likely to be a game changer for AMD
SuperMUC-NG
https://www.top500.org/system/179566
HAWK
https://insidehpc.com/2018/12/hpe-build-24-petaflop-supercomputer-64-core-amd-epyc-processors-hlrs/