

There are an increasing number of ways to do machine learning inference in the datacenter, but one of the increasingly popular means of running inference workloads is the combination of traditional CPUs acting as a host for FPGAs that run the bulk of the inferring.
This is distinct from machine learning training, which at the moment is dominated by the combination of CPUs hosts and GPU accelerators, the latter of which do the parallel processing that runs the neural network and creates the model upon which inference is based. There are good reasons for these distinct architectures to be used.
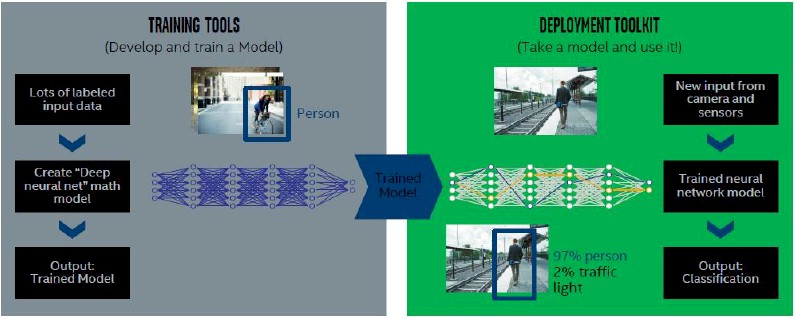
Deep learning consists of two phases: Training and inference. As illustrated in Figure 1 below, training involves learning a neural network model from a given training dataset over a certain number of training iterations and loss function. The output of this phase, the learned model, is then used in the inference phase to speculate on new data.
The major difference between training and inference is that training employs forward propagation and backward propagation (two classes of the deep learning process) whereas inference mostly consists of forward propagation2. To generate models with good accuracy, the training phase involves several training iterations and substantial training data samples, thus requiring many-core CPUs or GPUs to accelerate performance.
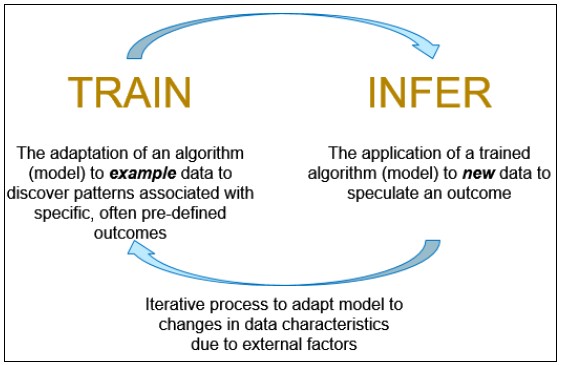
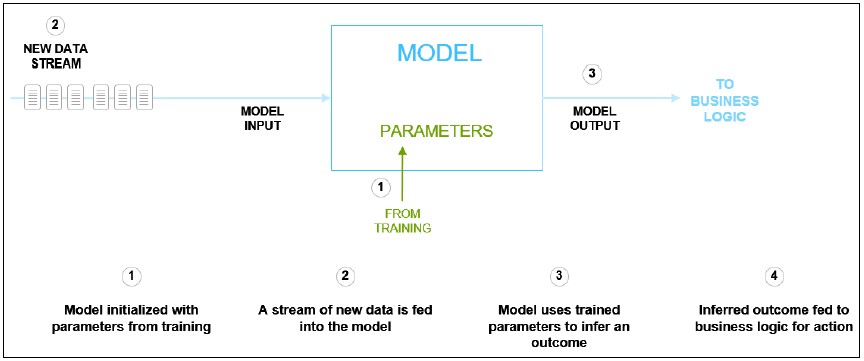
After a model is trained, the generated model may be deployed (forward propagation only) e.g., on FPGAs, CPUs or GPUs to perform a specific business-logic function or task such as identification, classification, recognition and segmentation [see Figure 2 below].
For this model deployment and inferencing stage, FPGAs are getting more and more attractive for Convolutional Neural Networks (CNN) because of their increasing floating-point operation (FLOP) performance, and secondly their support for both sparse data and compact data types. These trends are favoring FPGA-based platforms since FPGAs are designed to handle irregular parallelism and fine-grained computations compared to GPUs and CPUs. The focus of this tech note will be on FPGA as accelerated inference platform for CNNs.
Why Choose An FPGA Accelerator?
FPGAs provide flexibility for AI system architects searching for competitive deep learning accelerators that also support differentiating customization. The ability to tune the underlying hardware architecture, including variable data precision, and software-defined processing allow FPGA-based platforms to deploy state-of-the-art deep learning innovations as they emerge. Other customizations include co-processing of custom user functions adjacent to the software-defined deep neural network. Underlying applications are in-line image and data processing, front-end signal processing, network ingest, and I/O aggregation.
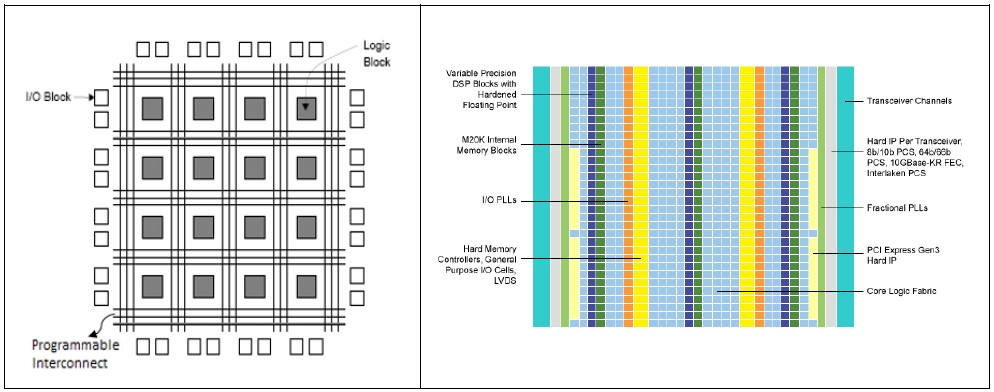
Figure 3 above illustrates the variety of building blocks available in an FPGA. The core fabric implements digital logic with Look-up tables (LUTs), Flip-Flops (FFs), Wires, and I/O pads. FPGAs today also include Multiply-accumulate (MAC) blocks for DSP functions, Off-chip memory controllers, High-speed serial transceivers, embedded, distributed memories, Phase-locked loops (PLLs), hardened PCIe interfaces, and range from 1,000 to over 2,000,0000 logic elements.
FPGAs In Mission Critical Applications
Mission-critical applications (for example, autonomous vehicle, manufacturing, etc.) require deterministic low-latency. The data flow pattern in such applications may be in streaming form, requiring pipelined-oriented processing. FPGAs are excellent for these kinds of use cases given their support for fine-grained, bit level operations in comparison to CPU and GPUs. FPGAs also provide customizable I/O, allowing their integration with these sorts of applications.
In autonomous driving or factory automation where response time can be critical, one benefit of FPGAs is that they allow tailored logic for dedicated functions. This means that the FPGA logic becomes custom circuitry but highly reconfigurable, yielding very low compute time and latency. Another key factor may be power – the cost per performance per watt may be of concern when determining long-term viability. Since the logic in FPGA has been tailored for a specific application/workload, the logic is very efficient at executing that application which leads to lower power or increased perf per watt. By comparison, CPUs may need to execute 1000’s of instructions to perform the same function that an FPGA maybe able to implement in just a few cycles.

The Intel Programmable Accelerator Card (PAC) features an Intel Arria 10 FPGA, an industry-leading programmable logic built on 20 nanometer process technology, integrating a rich feature set of embedded peripherals, embedded high-speed transceivers, hard memory controllers and IP protocol controllers. Variable-precision digital signal processing (DSP) blocks integrated with hardened floating point (IEEE 754 compliant) enable Intel Arria 10 FPGAs to deliver floating point performance of up to 1.5 teraflops. Arria 10 FPGAs have a comprehensive set of power-saving features. Combined, these features allow developers to build a versatile set of acceleration solutions.

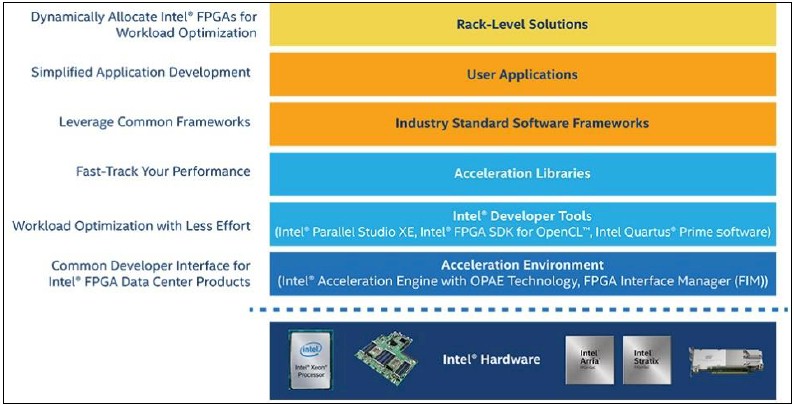
The Intel FPGA Acceleration Stack
The Acceleration Stack for Intel Xeon CPU with FPGAs is a robust collection of software, firmware, and tools designed and distributed by Intel to make it easier to develop and deploy Intel FPGAs for workload optimization in the data center. The Acceleration Stack for Intel Xeon CPU with FPGAs provides multiple benefits to design engineers, such as saving time, enabling code-reuse, and enabling the first common developer interface.
It also provides optimized and simplified hardware interfaces and software application programming interfaces (APIs), saving developer’s time so they can focus on the unique value add of their solution.
Intel OpenVINO
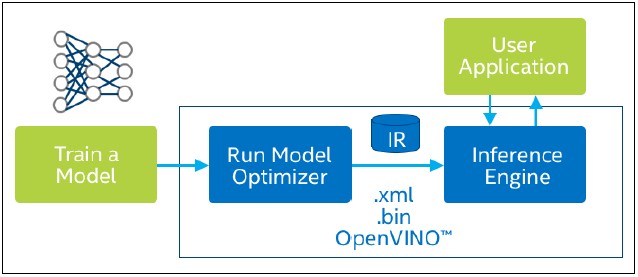
When packaged with Intel OpenVINO toolkit, users have a complete top to bottom customizable inference solution.
This toolkit allows developers to deploy pre-trained deep learning models through a high-level C++ inference engine API integrated with application logic. It is included in the OpenVINO toolkit and is also available as a stand-alone download. As shown in Figure 8 below, this toolkit comprises the following two components:
A. Model Optimizer
This is a Python-based command line tool that imports trained models from popular deep learning frameworks such as Caffe, TensorFlow, and Apache MXNet.
- Runs on both Windows and Linux
- Performs analysis and adjustments for optimal execution on endpoint target devices using static, trained models
- Serializes and converts a model into an intermediate representation (IR) format from Intel
- Supports over 100 public models for Caffe, TensorFlow, and MXNetInference Engine
B. Inference Engine
This execution engine uses a common API to deliver inference solutions on any platform of choice: CPU, GPU, VPU, or FPGA.
- Executes different layers on different targets (e.g., FPGA and selected layers on a CPU)
- Implements custom layers on a CPU while executing the remaining topology on a FPGA – without having to rewrite the custom layers
- Optimizes execution (computational graph analysis, scheduling, and model compression) for target hardware with an embedded-friendly scoring solution
- Takes advantage of new asynchronous execution to improve frame-rate performance while limiting wasted processing cycles
- Uses a convenient C++ API to operate on IR files and optimize inference
Evaluation Methodology
In this section, we give a brief overview of sample image-classification application, the hardware inferencing infrastructure used, and the deep learning models that were evaluated.
Application Case Study
ResNet is one the most widely used models for image recognition, known for its high accuracy, and in fact, the winning model of the ImageNet competition back in 2015. Compared to AlexNet (Table 1), RestNet-50 (a variant of the ResNet model) executes more than 60x operations for one image cycle, at an error rate of less than 3.5 percent versus 15 percent for AlexNet.

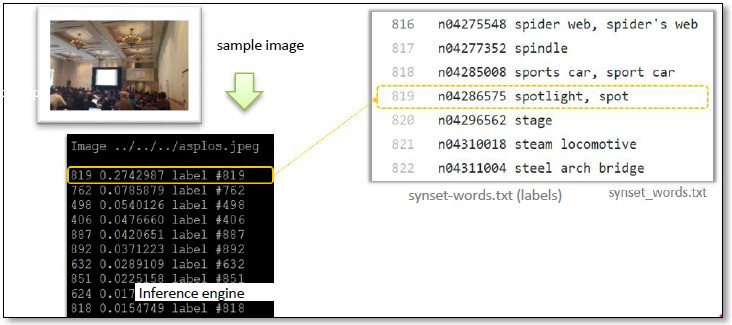
The application outputs various labels with varying confidence levels. Assuming the application was embedded in a mission-critical application requiring low-latency, what are the sort of things one would most importantly care about?
Given some trained models, the aim is to deploy them for inference bearing latency, cost, and developer efficiency.
The Dell PowerEdge Server
We used the Dell PowerEdge R740/R740xd servers to host the PAC boards. The PowerEdge R740/R740xd is a general-purpose platform with highly expandable memory (up to 3TB) and impressive I/O capability to match both read-intensive and write-intensive operations. The R740 is capable of handling demanding workloads and applications such as data warehouses, E-commerce, databases, high-performance computing (HPC), and deep learning workloads.

The PowerEdge R740/R740xd is Dell EMC’s latest two-socket, 2U rack server designed to run complex workloads using highly scalable memory, I/O capacity, and network options. The R740/R740xd features the Intel Xeon processor scalable family, up to 24 DIMMs, PCI Express (PCIe) 3.0 enabled expansion slots, and a choice of network interface technologies to cover NIC and rNDC. In addition to the R740’s capabilities, the R740xd adds unparalleled storage capacity options, making it well-suited for data intensive applications that require greater storage, while not sacrificing I/O performance.
Accelerating Inference
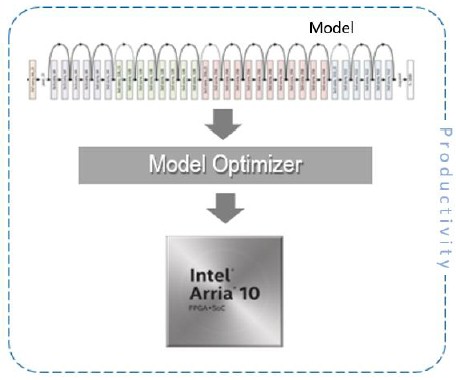
As shown in Figure 12 below, our goal is simple.
- Flexibly import models
- Model optimization: by quantizing floating-point operations – which would lead to reduce model size (good for embedded), low energy utilization, also execute quicker
- Deterministic low-latency by using FPGA-based accelerators like Intel PAC with Arria 10 FPGA
- Productivity: simplified ease-of-use and streamlined development through Intel OpenVINO.
Putting It All Together
For the complete solution, we roll up all these components (hardware, software, and developer toolkit) and a created a cluster based on Dell R740 server and Intel Xeon Scalable processors as shown in Figure 13 below:

Performance Results
We benchmarked SqueezeNet at batch sizes of 1 and 64 using FP11 precision. We are currently working closely with the Intel FPGA acceleration team in optimizing other models such as ResNet, GoogLeNet and VGG. These are some early results and Dell EMC is working closely with Intel in further optimizing these results. We will release these new optimizations using OPENVINO toolkit on Intel PAC as a follow-up to these early results. Take a look:
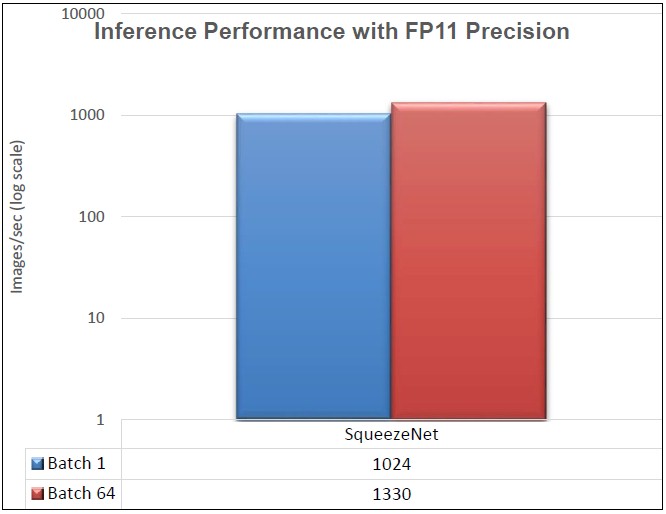
The performance gain with SqueezeNet architecture makes it attractive in streaming applications, particularly in low power, memory-constrained, embedded devices.
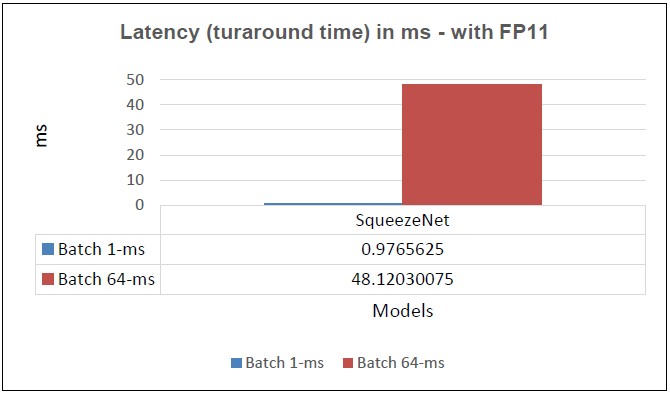
Another way to evaluate performance is through latency as plotted in Figure 15 above. We see with SqueezeNet it takes less than 1 millisecond as the total turnaround time to perform inference on a single image, that is., at batch size of 1. Again, the performance difference is less significant when running these models at batch size of 64. These sorts of analyses are useful when trading-off between inference time, model footprint and model accuracy at specific precisions, in this example, FP11.
Results For Peak Performance/Watt
Efficient energy utilization is important to minimize operational costs. In large-scale scenarios, for example, in the datacenters, the economics of scale is a crucial factor when deploying hardware accelerators on servers. Consequently, performance/watt becomes a key metric for normalizing performance. Since the PAC accelerator has a low power envelope (a thermal design point of 50 watts), it can achieve increased throughput/watt compared to CPUs or GPUs which are typically orders of magnitude higher in TDP. Table 2 below summarizes the energy efficiency of the PAC accelerator running SqueezeNet architecture:

Conclusions
This tech note has presented an overview of deep learning and CNN inferencing, motivating the need for FPGAs as inferencing accelerators in mission-critical (low-batch, low-latency) applications. We then presented the Intel Programmable Acceleration Card (PAC) along with the developer toolkit (OpenVINO) for deploying FPGA-accelerated CNN models. Using this PAC accelerator as an add-in card to a Dell PowerEdge R740 server, we demonstrated how we deployed pre-trained CNN models with no additional programming effort. Our results highlight achieved throughput for batch sizes of 1 and 64, for popular CNN models. We also presented latency (or turn-around time) of these models, observing the lowest latency with SqueezeNet at batch size of 1. Since the PAC accelerator can be reconfigured with improved logic, we can expect that continued development of this new logic will not only improve performance, but will also enable different bit precisions (for example, FP8 rather than FP11) and additional CNN and RNN architectures like SSD and LSTM.
Bhavesh Patel is a Dell EMC distinguished engineer and drives server architectures and technologies within the Server Advanced Engineering group. In addition to his duties as a server architect, he is focused on machine learning/deep learning, high speed IO technologies and optical communications. Patel has served in various Engineering roles spanning from signal integrity to system design to architecture; he also hold patents in areas of high-speed I/O design, power sub-system and system architecture.




FPGAs for autonomous driving and factory automation? Given Single Event Upsets (SEUs) of FPGA image RAMs, would you ride in a FPGA-controlled autonomous vehicle?
Very interesting article that shows the potential of FPGA for inference acceleration. In fact, FPGAs can be used not only to speedup the inference but also the training part of the machine learning algorithms as it is demonstrated in several cases. E.g. InAccel http://www.inaccel.com provides ready-to-use cores for the acceleration of the training part of the ML without need to change the code.
Where is and what is figure 6?