

The sign of a mature technology is not just how pervasive it is, but in how invisible and easy to use it is. No one thinks about wall sockets any more – unless you happen to need one to charge your phone and can’t find one – and that is but one example of a slew of technologies that are part of every day life.
Since Google first open sourced the Kubernetes container controller, inspired by its Borg and Omega internal cluster and container management systems, more than four years ago, we have been betting that it would become the dominant way of managing containers on clouds both public and private. The irony is that the people in charge of Google’s infrastructure were not initially all that enthusiastic in giving away such intellectual property, but the Kubernetes and open source enthusiasts correctly predicted that Google would get tremendous cred with the open source community and help create a Google-alike containerized private cloud environment and also possibly spread Google’s approach to rival clouds as well as helping its own Cloud Platform expansion by giving Kubernetes to the world.
It is safe to say that the Cloud Native Computing Foundation, which steers Kubernetes as well as the related Prometheus monitoring tool, has done the job set out by Google and friends to transform Kubernetes into a tool backed by an ecosystem that spans a wide variety of platforms, vendors, and customers, and that is why months ago it went from its incubation to graduate status at the CNCF, a kind of rite of passage, and boasts plenty of big name production users, too. But Kubernetes is still an unfinished product and has yet to reach the kind of invisibility status that the Linux kernel and its surrounding operating system components, for instance, has achieved in 25 years. (It probably only took 15 years to hit that level, really.) As part of the recent announcement of the Kubernetes 1.11 container orchestrator, we pondered when this ubiquity and invisibility might happen.
He community is certainly strong. This data is a bit out of date, but ranked the activity of the 85 million software projects of 28 million users of the GitHub repository from November 2016 through October 2017:
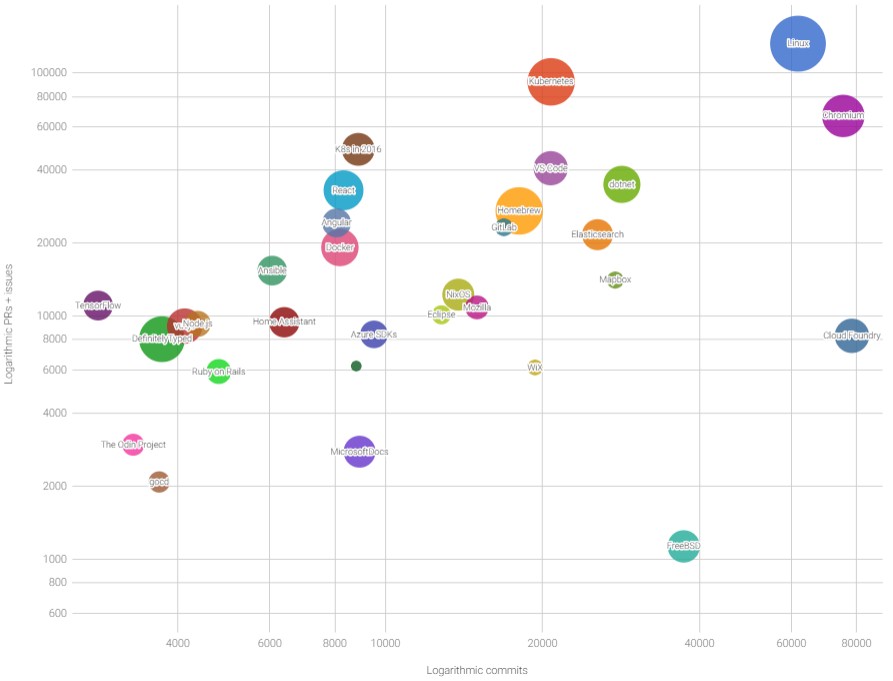
This is a bubble chart that plots the number of pull requests and issues for each project on the Y axis and the commits done by project members on the X axis, with the relative size of the community shown by the bubble. The size is actually the square root of the number of authors in each project, with the Linux kernel having 3,843 authors at the time, followed by Kubernetes with 2,380 and Docker having 1,346.
Kubernetes has wisely ceded the container runtime format to Docker, and buried the hatchet several years back with CoreOS, which had its own rkt format, and now that everyone agrees that Docker is the format of the container, everyone can apparently agree that Kubernetes is going to be the way to manage sophisticated pods of them that actually encompass and embody modern microservices applications and even some legacy monolithic ones.
The big three public clouds in the Western economies – Amazon Web Services, Microsoft Azure, and Google Cloud Platform – all support Kubernetes in one form or another, and both the OpenStack and CloudStack open source cloud controllers have a means of letting Kubernetes run the show. As we have discussed, VMware has many different ways of delivering Kubernetes container services (perhaps too many given the conservative nature of its enterprise customer base). Earlier this year, RedHat acquired CoreOS, and now its own Kubernetes stack based on CoreOS Tectonic and its OpenShift tools. Docker has inevitably embraced Kubernetes as an alternative to its own Swarm container controller in its Docker Enterprise stack. In China, Baidu is embracing Kubernetes on its cloud for its PaddlePaddle machine learning framework and has its own Cloud Container Engine based on Kubernetes. Alibaba has its own Cloud Container Service and Tencent has its own Kubectl Container Engine. Windows Server will have general availability of native Kubernetes support early in 2019.
This covers a lot of bases in the enterprise, and it has most of the world now able to orchestrate containers the way Google wants – with input from the community, of course. The reason why Google opened up Borg through Kubernetes (and made it multiuser and more friendly, to be sure) is a perfect example of enlightened self-interest. Now, it is in theory going to be a lot easier to move workloads from on-premises datacenters or rival public clouds to Google Cloud Platform. The converse is also true. If customers are not happy with Google Cloud Platform, they can move their containerized applications off that cloud to Google’s rivals or back to on premises machinery. It is up to Google to attract customers and keep them on its cloud, which seems like a decent incentive.
To reach a state of ubiquity, a technology has to be well integrated with other technologies before it can become invisible – and vice versa. They work hand in hand. But clearly, there is a large community of developers and a large ecosystem of platforms that have embraced Kubernetes, and now we will see how Kubernetes is actually adopted and if it can, as we suspect, become pervasive.
We had a chat about the Kubernetes 1.11 release with Josh Berkus, Kubernetes community manager at Red Hat and the lead for this latest update for the container controller, and we talked a bit about the potential for Kubernetes. As it turns out, a lot of work down in the guts of Kubernetes has been done to make it better suited for widespread use – and there is still more work to be done.
The Kubernetes 1.11 update is a good case in point. Berkus says that the of the core 25 features tweaked or added in this release, seven of them were for user facing features – things the user can actually see and experience – while 18 of them were for replumbing inside of Kubernetes – things that users will not see, but will benefit from just the same.
“It is a little bit hard to try to figure out when we will be treating Kubernetes as a known quantity, because some of this replumbing is pretty substantial,” Berkus tells The Next Platform, referring to one of the replumbing jobs relating to integration with the public clouds and that will be ongoing for the next couple of releases. “In the original Kubernetes 1.0, cloud integration is in the main code. So, if a new cloud provider like Digital Ocean, for instance, wants to have a Kubernetes offering, they actually have to get patches accepted into Kubernetes to make all of their stuff work. That is obviously bad, and nobody is arguing that it is a good thing. The cloud provider team has been working hard in turning the cloud provider stuff into a clearly defined and relatively feature proof API. In Kubernetes, we actually move out the first cloud platform, which is OpenStack, which needed to overhaul its own cloud provider code anyway and they volunteered to be the first ones to move out of Kubernetes core and use the API exclusively. There is a bunch of stuff like this we need to do. We need to move out the cloud providers to the cloud API, we need to move all of the storage providers to the cloud storage interface (CSI) API. We need to move all of the container runtime stuff and make sure it is using the container runtime API and not using back channels. In terms of the number of lines of code, that is the majority of the work in the Kubernetes project right now. So the point where Kubernetes becomes a known quantity and you are not expecting any radical changes will be done when we are finished turning everything into APIs.”
This moment is probably years away, Berkus agrees, because as the APIs come out, their shortcomings will be revealed – as happens when all code is created – and they will have to be revved slowly and carefully to not break compatibility. Considering we are coming up on the third anniversary of the 1.0 release that made Kubernetes deployable (though not mature), and that is still a pretty fast ramp from a code dump from Google onto GitHub four years ago. That Google code – a simplified version of Borg written in Go and made more generic than the precise use cases inside of the search engine giant – was a very good headstart, to be sure. And Google has in effect outsourced some of the work to make the Borg-alike portable across platforms while having community partners do the work enthusiastically.
That brings us to Kubernetes adoption. No one knows for sure, this being an open source software stack. The majority of companies that are involved with cloud technology, either on premises or on public clouds, are using Kubernetes in some way, but for general enterprises, which still represent 80 percent of organizations (a rough guess) and maybe half of compute spending (meaning direct spending on iron), they are not there yet. But they are starting up the adoption curve.
The Kubernetes 1.11 release has features that will make that adoption easier. The project is switching from the homegrown KubeDNS server to the CoreDNS code that is a CNCF project, and a set of code that Berkus says is better code and more widely supported by the community. The 1.11 update also has dynamic configuration (through a configuration file or a ConfigMap) of kubelets, the Kubernetes daemon that resides on all systems in a container cluster; in the past, admins had to go into Kubernetes and change startup flags and restart the systems. Custom Resource Definitions, or CRDs, have been tweaked to make it easier to create applications that see a Kubernetes cluster as a system, and not get down into the granularity of containers in an explicit way. (This is the genius of Borg.) These CRDs are the main way that Kubernetes gets extended, and the KubeVirt add-on, which allows Kubernetes to reach down into clusters and control hypervisors and their virtual machines, is but one example. The release also includes priority and preemption features, which means Kubernetes can take a high priority job and run them now, even if it means knocking other applications off the cluster to be finished later. The last big visible change is an in-kernel IPVS load balancing tool, which load balances Kubernetes services on the cluster.




Be the first to comment