
For many enterprises these days, managing data has the feel of a three-ring circus. Data can be created and housed in a growing number of places, from central datacenters to the cloud and, increasingly, the network edge, and it needs to be able to move easily back and forth between these places to be of any use. None of this is easy.
As we have noted at The Next Platform, MapR Technologies has spent the past several years building out its data management platform to help enterprises overwhelmed with the challenges presented by the flood of data coming in from an increasingly distributed computing environment. The company originally started off as a Hadoop distributor, but has bulked up its platform to expand beyond the open source file system and, more recently, to address the needs of businesses as they tackle a multi-cloud world. The platform supports the Hadoop Distributed File System (HDSF), but also NFS, Posix, REST, HBase, JSON and Kafka, giving it a broad reach across the data spectrum. MapR offers a data fabric model though which customers get access to a single pool of data that comes from multiple sources, including streams, files and tables. In the latest major upgrade of its MapR Data Platform, the company addresses the need for greater automation for AI and analytics and the need to extend the reach deeper into the cloud.
“If AI is the electricity of this new world, then you need a distribution grid for it, and the distribution grid needs to span from your edge into your cloud and into your on-premises environment and it needs to distribute data so that AI can power itself,” Anoop Dawar, senior vice president of product management and marketing, tells The Next Platform. “When you do that, you need a lot of capabilities that are traditionally not found in real-world data analytical systems. Those are the capabilities that we’ve added to the platform.”
With MapR Data Platform 6.1 release, the company is putting more of a focus on on-premises and multicloud environments rather than the edge, Dawar says. The challenge when a customer is handling hundreds of petabytes of data is classifying it into hot, warm and cold tiers and then identifying what data to move where, moving it and then bringing it back. That’s being accomplished through object tiering and intelligent and automated data placement in the upgraded platform, he says. At the same time, the goal is to optimize the process for both performance and cost, which is where new features like erasure coding capabilities come in to protect data in object stores like those found with Amazon Web Service’s S3.
The object tiering feature enables many of these goals by allowing customers to store seldom-used data, based on policy, in an external object store. The move takes the data out of the MapR environment, though MapR keeps hold of metadata related to that data. That enables enterprises to quickly and automatically access the data in the external store, Dawar says.
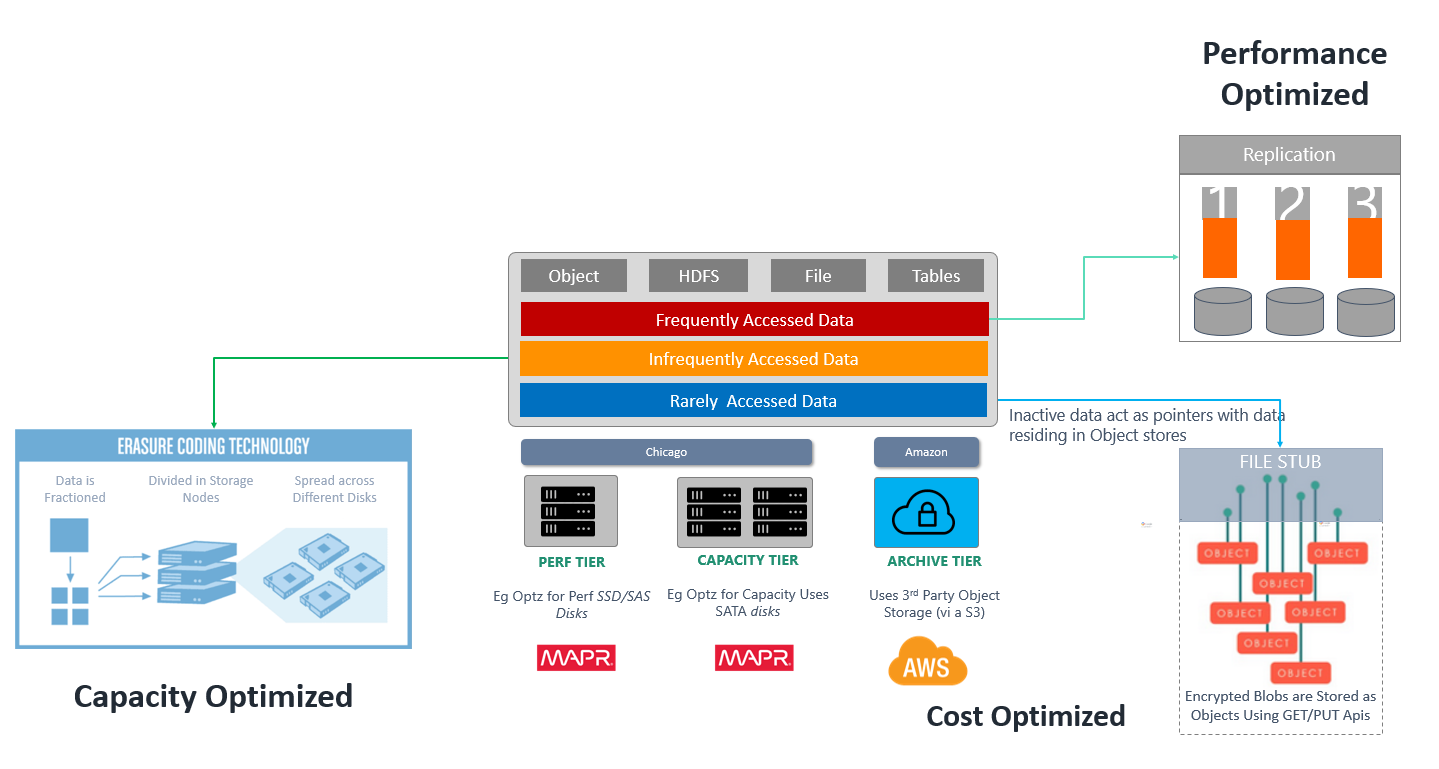
With tiering, “because we’re a software-defined system, we can allow you to logically group and create a performance tier, with SSDs with 2X application performance if you wanted,” he says. “We can create a capacity tier with hard disks that are 8 TB in size in dense nodes, and then we can create an object tier which is not actually stored in MapR. Only the metadata is stored in MapR and the data is stored in an object store of your choice, either on-prem or in the cloud. There is a simple policy-based, multiple-template for storage tiering going on. The easiest way to think about it is, data comes in, it’s hot, it needs fast analytics, it’s in your frequently accessed data tier.”
If the policy states that after the data is 30 days old it shifts to the external object store, then it’s moved automatically.
“We will keep the metadata in the system,” Dawar says. “So what are the security permissions on it? What is the size of the file, who created the file, who’s the owner? If you had some extended information, like ‘This was for an autonomous car prototype run, the weather was 37 degrees, the route was a 17-mile drive,’ all of that information is there. So if you want to recall it, all of that information is there.”
The MapR platform had tiering previously, but the policy-setting capabilities and erasure coding weren’t. Neither was the ability to tier data out of the platform to an external object store and then bring it back.
“The tiering was still performance and capacity [optimized], but it was without erasure coding,” Dawar says, noting that it was a very manual process. “You could still do capacity tiering with dense disks, but … the cost was really high. With erasure coding, your costs can be reduced significantly and the same cluster can store more data. There was no policy, so you would do a CLI, but you didn’t know what data to move. You had to figure out that all this data is two days old. Now that’s automatic.”
Object storage tiering also drives down the cost of disaster recovery on the platform. It can be done today, but it’s expensive, especially if the goal is simply to store the data. Customers can have a 100 PB cluster on-premises and then stand up another 100 PB cluster in another datacenter or the cloud, but if it’s used for disaster recovery, an enterprise won’t want to run analytics on it. With the upgraded platform, disaster recovery is a simpler and less expensive proposition.
“Imagine creating a tiny, tiny cluster in the cloud or on-prem and establishing a disaster recovery relationship between the source cluster and this tiny, tiny cluster,” Dawar says. “Then configure this tiny cluster to use object tiering. It doesn’t story any real [data], you just push it to the object storage. The good thing is the entire 100 petabytes is available on-prem [and] the tiny cluster could be as small as five nodes and then all the 100 petabytes is stored in the object store. Imagine your primary datacenter goes down – no big deal. Your cluster is already up and running in the cloud – you can add more nodes if you want, you can run the jobs that you want. As you run those jobs, the system will fetch only the objects that need to be fetched back into the cluster. If your jobs are running so that only 20 petabytes need to be accessed, only 20 petabytes will come up from the object store. The other 80 will stay happily in the object store, and you have a very cost-optimized disaster recovery in the cloud.”
MapR also is introducing the Data Object Service. S3 has become the key place for applications and in-place analytics, and holds a large amount of datasets for hybrid and multicloud environments as well as disaster recovery, he says. With the Data Object Service, MapR is offering an API that is compatible with S3 and that enables customers to write data into the MapR cluster. In addition, they can move data from the MapR S3 cluster to the datacenter or to another cloud. In addition, enterprises can create a data store on-premises that is compatible with S3.
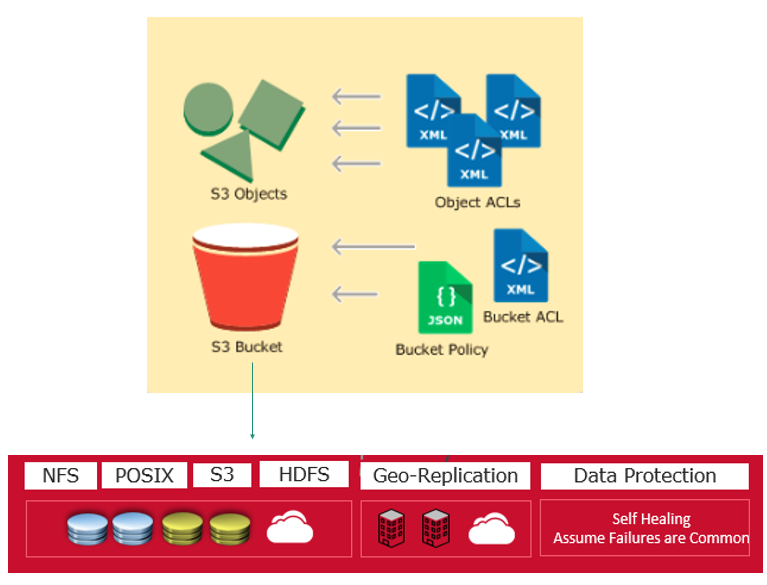
MapR supports not only AWS but also Microsoft Azure and Google Cloud Platform. MapR Data Platform 6.1 – which is in beta now and will be available this quarter – also includes security as a default and native encryption of data at rest.
“We rotate the keys uniquely for every megabyte of storage,” Dawar says. “The reason we do that is if you take one key and you try to encrypt one petabyte of data, it’s very easy to figure out what the key is, because you have a lot of data to look over to figure out what the actual key is. So we rotate the key every megabyte to make sure that nobody can hack your key. It’s all seamless key management.”


How AWS Can Undercut Nvidia With Homegrown AI Compute Engines
Amazon Web Services may not be the first of the hyperscalers and cloud builders to create its own custom compute engines, but it has been hot on the heels of Google, which started using its homegrown TPU accelerators for AI workloads in 2015. AWS started with “Nitro” DPUs in 2017 …

The Least Crazy And Least Mean GenAI Model Will Win
It takes big money as well as big ideas to compete in the generative AI space. Not hundreds of millions of dollars, but billions of dollars. And because of this, and because the stakes are so high as GenAI goes from hype cycle to commercialization, we see alliances and partnerships …
Google Follows Suit With Microsoft On Ampere Arm Instances
A long time ago, when we first started The Next Platform, Urs Hölzle, then senior vice president of the Technical Infrastructure team at Google, told us that to gain a 20 percent improvement in price/performance it would absolutely change from the X86 architecture to Power architecture – or indeed any …
My company started using MapR late last year and I have to say it’s quite good. The filesystem in particular let is get rid of a lot of legacy storage that slowed us down. MapR-DB and object tiering are on the roadmap for us.