

Edge computing can mean different things to different people, as is the case with any new phenomena in the IT sector. We like the definition that an Intel executive once gave us, which is that the edge, as we like to call it here at The Next Platform, is basically the transformation of the embedded market, bringing into the modern connected world lots of equipment that has compute hardware attached to control its operation.
Connecting up such gear opens up new possibilities to collect and analyse the data from these devices, data that could help to make operations more efficient or even generate new business models.
According to figures from Accenture, the number of sensors and devices that industrial applications of IoT depend upon have already hit tens of billions, and the firm estimates that taking full advantage of the opportunities these offer could add $14.2 trillion in value to the global economy by 2030.
One of the problems for companies looking to implement such a strategy is that the infrastructure to support IoT operations can appear fiendishly complex at first glance. Not only does it involve managing all the connected devices, but also collecting and managing the streams of data these generate (which could add up to a significant volume), and analyzing the data to extract the key nuggets of information you are looking for.
Another issue is that use cases for the IoT are so diverse that each organization’s exact implementation may well turn out to be unique. This leaves many with the option of building up their own stack from scratch, or using many of the turnkey IoT platforms that have been developed by the big cloud providers, for example, that make it easy to get up and running, but do not necessarily make a good fit with your requirements.
A third approach is to find a platform that can take care of the basic data management “plumbing”, but which provides APIs and developer hooks that allow the user to build their own custom solution on top. This is what Crate.io, developer of an open source clustered SQL database called CrateDB, claims it is offering just such a platform, called the Machine Data Platform (MDP) obviously. (We like platforms here at The Next Platform, as you might imagine.)
“What we learned from existing customers like Alpla and Zumtobel is that these guys want to build their own IoT platforms. They don’t want to use a full spec solution that gives them dashboards and everything with a few clicks, because that doesn’t really solve their challenges,” Crate.io’s chief executive officer Christian Lutz tells The Next Platform.
“All the visualizations, etc, that’s a commodity part. They really need to build custom logic, which has domain-specific knowhow and knowledge: what you have to look for in the production process, what parameters you have to watch, and what you are doing with that information. This is totally domain-specific and it’s actually something that companies don’t even want to share, because it’s their differentiation from the competition.”
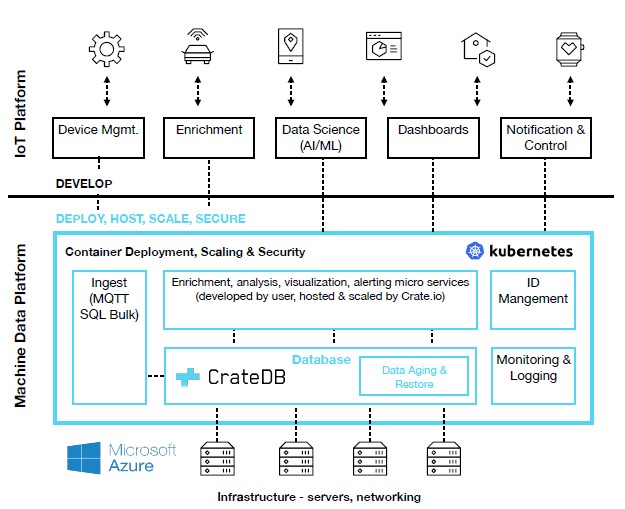
MDP builds upon CrateDB, which is implemented as a scalable, shared-nothing cluster of identically configured nodes that handles the write and query operations automatically distributed among them. This was developed by Crate.io with IoT applications in mind and is still available as a free-to-download version or in an enterprise edition backed by paid-for support.
In MDP, this database core comes packaged with additional functions, including those for data ingestion, data management and archival, monitoring and logging, and ID management. Many of these comprise other open source tools that Crate.io has done the integration work on, to glue them all together to enable the entire platform to be operated and scaled easily. Thus the data ingest is provided by RabbitMQ, Identity management relies on OAuth 2.0, logging uses Fluentd and monitoring is delivered through Prometheus and Grafana. All the components run on a Kubernetes managed cluster, as a Docker container.
This means that data can be ingested via MQTT or SQL bulk data insert, after which it typically undergoes an enrichment process to convert the raw data from the sensors into a more meaningful representation of the data, such as with cleartext names for fields that the developers can work more easily with. Crate.io can also provide the ability to enrich the captured information with SAP or ERP data drawn from the production process.
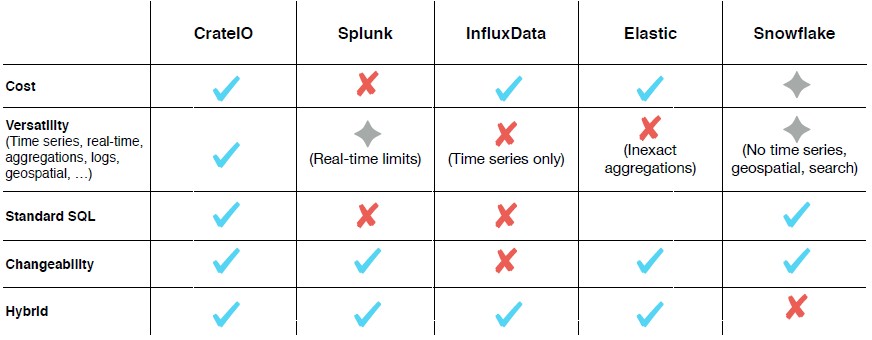
According to Crate.io, organizations can simply use developers with the relevant SQL skills to build their domain-specific application on top of the MDP. The CrateDB database at its core has had all SQL functions developed from scratch to be compliant with ANSI SQL-99, which Lutz claims is a key differentiator from many rival database platforms. Despite using SQL as the data access language, CrateDB otherwise has more in common with NoSQL platforms, able to handle time series data, geospatial data, JSON documents and relational data, all in the same system.
“We want to focus on those customers that need to really build custom applications to extract the value of the data from their production line, and this is the key piece really because the monitoring piece and the dashboard, these are already a commodity for most,” Lutz says.
“The way you get money out of this data, that’s when you totally understand your process and your sensors and from that you create a custom app, and that’s what we want to make very easy for the customers, so they don’t have to worry about the data collection and the data, it’s just there and they can focus on building their app.”

The MDP is available on Microsoft’s Azure cloud as a fully managed service, or as an on-premises solution, with pricing starting at $700 per node per month. Customers can choose to have the CrateDB core only, CrateDB plus data ingestion functionality, or the entire platform.
Crate.io also released an updated CrateDB 3.0, which is the version used in MDP. This brings a number of enhancements requested by customers, such as support for hash joins, views of tables, and a shard visualizer, where you can now dynamically see how your data is allocated on which node in the cluster. Enhanced security features include user admin and role-based access controls in addition to encryption and authentication.
In conjunction with the rollout of the new software stack, Crate.io also announced that it has secured $11 million in Series A funding from Zetta Venture Partners and Deutsche Invest Equity with participation from Mike Chalfen (who made a fortune on Candy Crush), Momenta Partners, and Charlie Songhurst (a former Microsoftie who has also invested in quantum computing startup Rigetti). Original angel investors that helped get Crate.io off the ground – Draper Esprit, Vito Ventures, and Docker founder Solomon Hykes – also kicked in some dough.


The Continuum From Edges To Datacenters
Enterprise IT continues to cast its attentions – and sometimes its aspersions – out to the edge, that place outside of traditional datacenters and beyond that cloud where data is increasingly being generated and processed. At The Next Platform, we have written about the systems and platforms that hardware and …

Dell Ties Storage To Kubernetes, Sharpens Edge Strategy
Dell Technologies, since its founding 37 years ago, has been about infrastructure — from the servers, networking systems and storage appliances that populate enterprise datacenters to the corporate clients that are designed to make employees more productive. Infrastructure is what has driven Dell to become a multinational IT giant that …
Hybrid Computing Sharpens Its Edge
Computing has become more complex as the digital age has progressed. In the early days, companies had a central machine or a collection of them doing all of their processing, and then clients like PCs and then smartphones got smart and some of the work of these central processors was …
Be the first to comment