
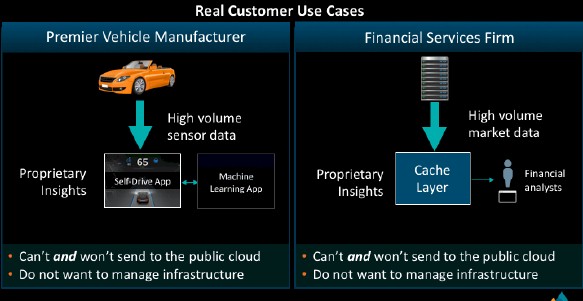
The only companies that want – and expect – all compute and storage to move to the public cloud are those public clouds that do not have a compelling private cloud story to tell. But the fact remains that for many enterprises, their most sensitive data and workloads cannot – and will not – move to the public cloud.
This almost demands, as we have discussed before, the creation of private versions of public cloud infrastructure, which interestingly enough, is not as easy as it might seem. Scaling infrastructure down so it is still cost effective and usable by IT shops is as hard as scaling it up so it can span the globe and have millions of customers all sharing the compute and storage utilities as well as higher level services running atop this infrastructure.
Aside from the scale down issues, which present their own engineering challenges, there is another big problem: The gravity of data. Moving data is much more of a hassle than computing against that data at this point, and the biggest public cloud providers and hyperscalers have spent enormous fortunes creating vast compute and storage utilities that make all compute and storage look local to each other (thanks to some of the biggest networks ever built). Enterprises running private clouds want to have scalable compute and storage too, but the much smaller scale they operate at requires a different kind of architecture.
At least that is the contention of Kiran Bhageshpur, CEO and co-founder at Igneous Systems, which has just uncloaked from stealth mode after three years of funding and development. Bhageshpur was previously vice president of engineering at the Isilon storage division of Dell EMC and prior to that was senior director of engineering at Isilon Systems, where he was responsible for the development of the OneFS file system and its related clustering software. Bhageshpur started Igneous in the public cloud hotbed of Seattle back in October 2013, and brought together public cloud engineers from Amazon Web Services and Microsoft Azure as well as techies from Isilon, NetApp, and EMC, and is creating a series of networked appliances that will be able to mimic the compute and storage functions of the big public clouds – meaning support their APIs – but do so on hardware that is radically different from both that used by the cloud providers themselves and the standard rack-based gear used by enterprises. The Igneous hardware is developed to be tightly integrated with its software and provide a lower-cost for a given compute or storage service than the public clouds offer.
This is a neat trick, if Igneous can pull it off, and it is at the heart of the data-centric computing architecture that Bhageshpur discussed last week here at The Next Platform.
“Workflows are really much more around and about the data itself and the infrastructure on which the data lives,” Bhageshpur explains. “This is the broad problem that we are here to solve. If you think about it, in a traditional infrastructure from the EMCs and NetApps and HPEs and IBMs of the world, it is all local in a customer’s datacenter, but they are all managed one at a time and acquired as a capital asset upfront well ahead of need. Clearly, the reaction to this was the birth of the public cloud, with Amazon Web Services leading the way, which was compelling because companies did not buy hardware and they don’t install software or monitor or manage the fleet of infrastructure. Instead, they focus on its logical consumption across APIs. We have gone from the world of talking file and block and Oracle databases to talking S3 and Elasticsearch and having Elastic Container Services or higher-level services like AWS Lambda. The reaction to the public cloud has been the birth of the private cloud, which in our opinion is certainly not cloud. You are still buying the hardware, you are still installing software, and you are still monitoring and managing infrastructure and apart from improvements in orchestration, you are not getting any of these higher-level services is what makes the cloud services so rich. This is the gap that we are shooting with Igneous.”

To develop its first products, Igneous raised $26.7 million in funding from NEA, Madrona Venture Group (an early investor in Amazon), and Redpoint Ventures. The very first of those, which is launching this week, is called the Igneous Data Service, and it is a fabric of disk drives with ARM-based compute attached to each drive that are configured to look and smell and taste like the S3 object storage Amazon Web Services. This last bit is the key, and it means that applications that are written to the S3 protocol won’t be able to tell they are not using the S3 service out on the AWS cloud even when it is running locally inside of a private datacenter.
Igneous is not limited to only supporting AWS protocols for storage, and Bhageshpur hints at some of the possibilities without giving too much away about the company’s plans. “The way we are thinking about this as we build out is that the back-end is what is more important, and where needed we will use the appropriate APIs from Amazon Web Services or Microsoft Azure or Google Cloud Platform. We do not believe there is any reason to reinvent any APIs for various services, and using these existing APIs with customer data is where the value really is.”
It is not difficult to imagine that Igneous will come up with local versions of the AWS Elastic Block Storage (EBS) service as well as equivalents to its Elastic Compute Cloud (EC2) service, and then move on to provide the equivalents to the compute and storage services provided by Google and Microsoft on their public clouds. It would be useful to have this all running on the same iron, and it would be even more interesting if Igneous is the one that comes up with truly hybrid compute and storage services that run on the same physical infrastructure that it develops, manufacturers, installs in datacenters, and sells as a service instead of as a capital investment to end users.
This would be yet another type of hybrid cloud, and quite a feat. Bhageshpur is not promising this, mind you, but it is not s stretch to see that it could be done, and be a lot more useful than having something that is incompatible with the public clouds (as OpenStack is) running internally.
The software for the S3 service running atop the Igneous Data Service is all internally developed and closed source, just as it is at all of the cloud providers, by the way. For hardware to support this private S3 clone, Igneous has developed a compute element based on a Marvell Armada 370 processor, which is a 32-bit processor with two Cortex-A9 cores running at up to 1 GHz. This is not a lot of compute, but it can run a Linux instance and, importantly, it puts the compute right on the 6 TB disk drive itself. This system-on-chip has two 1 Gb/sec Ethernet ports, which is not a lot of bandwidth mind you, but you are creating a mesh fabric of compute and storage, so the aggregates and the topology matter as much as the speed and latency of any port. The whole thing is called a “nanoserver” by Igneous, something that may or may not be trademarked by Microsoft, whose new cut-down version of Windows Server 2016 is called Nano Server.

“If you think about a traditional storage server, it has not changed in 30 years,” says Bhageshpur. “It consists of a CPU, now based on an Intel Xeon, with a bunch of disks, and this is really an I/O bottleneck for large datasets that are growing. You have a powerful CPU and lots of capacity, but a thin straw in between them. And these are also large fault domains – an enterprise could have a dozen or more of these, but if one of these fail, it could be up to a half petabyte of capacity today, you have a major outage and you need to figure out how to resolve that. This is antithetical to how you do things at hyperscale. On the pets to cattle spectrum, this is about as pets as pets can be.”
The architecture of the Igneous Data Service does not have such large fault domains across its distributed cluster of disks, and the idea is to have a consistent ratio of clock cycles, disk capacity, and network bandwidth as the system scales up. A single disk drive becomes the fault domain, and using tweaked Reed Solomon erasure coding techniques common with object storage systems and local processing from the ARM processors on adjacent drives, spare compute on the drives in the Igneous Data Service enclosures where the drive fails help rebuild that lost data quickly (and in parallel) on spare drives in the system.
The Igneous Data Service enclosure is a standard 4U rack-based unit that holds 60 of the Igneous ARM-based drives, which all run Linux and the Igneous object storage system that is compatible with S3. This unit is manufactured by the same ODMs that make iron for AWS, Google, and Microsoft (and that probably means it is Quanta Computer), and instead of SAS disk controllers in the chassis it has two embedded Ethernet switches. Multiple enclosures can be daisy-chained together to grow the storage system.
The private S3 clone that Igneous has created employs whitebox servers based on Intel Xeon processors to work as “data routers” to steer data around the disk drive fabric and to do some intelligent processing and indexing of the data that is spread across the drives. Finding data is a lot harder that storing it, and this is where companies spend a lot of their time.
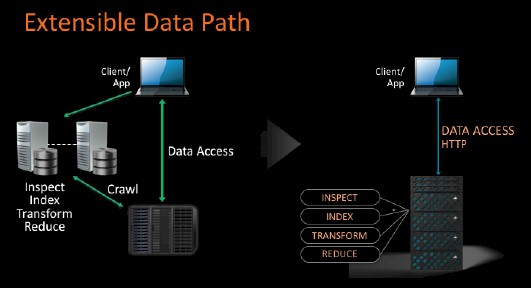
All of the management and monitoring of this S3 storage clone is done remotely on a cloud run by Igneous itself.
The whole shebang is priced at utility pricing that is actually lower in cost than the real S3. (We don’t know how its performance is, but such data is no doubt coming.) With 6 TB drives and those Armada 370 processors and that relatively modest networking, the base Igneous Data Service enclosure has 360 TB of raw capacity and about 212 TB after erasure encoding and spares are taken into account. This unit is available for a subscription price of under $40,000 per year for the service, or around $188 per TB or 1.5 cents per GB per month. On premises storage can cost on the order of $1,000 per TB to acquire, says Bhageshpur, and that does not include the operational headaches and personnel costs associated with managing such storage. Call it $250 per year just for the base hardware if you amortize over four years, and software and operational costs add to this base storage cost, and we think at least doubling it if we had to guess. (And we do.) AWS S3 storage costs 3 cents per GB per month, not including data access and data transfer charges across the AWS network. This is a pretty compelling price difference in favor of Igneous, and one that is bound to get some attention.
What will be even more interesting is when Igneous has a full suite of iron that can deliver compute and storage services on private clouds that are compatible with the AWS API stack. While the company is using ARM chips on its S3 appliances, it does not stand to reason that its EC2 clone, when it appears, will be based on ARM.
“For regular compute tiers, just running compute-heavy workflows, this is still very much Intel Xeon, which has a great price/performance and there is no question about that,” says Bhageshpur. “But when we start looking at the number of chips and putting compute close to data, that is where we believe ARM is the way to go because price/performance and power profiles are unmatched.”
The question we have is how much the Igneous Data Service hardware looks like the actual iron behind the real S3 service. Amazon bought Apurna Labs and makes its own ARM chips, after all.
Applications are not yet running in large numbers on ARM server chips proper – and we do not think of the Marvell Armada 370 chip as a proper server chip – but when and if they do, you can bet that Igneous will be putting together a compute chassis based on some 64-bit ARM nodes as well as what will probably be Xeon D and Xeon compute nodes for an EC2 clone. We shall see.


The World Has Changed – Why Haven’t Database Designs?
It seems like a question a child would ask: “Why are things the way they are?” It is tempting to answer, “because that’s the way things have always been.” But that would be a mistake. Every tool, system, and practice we encounter was designed at some point in time. They …
AWS Tunes Up Compute And Network For HPC
When it comes to hardware, there was not a lot of big news coming out of the Amazon Web Services re:Invent 2022 conference this week. And to be specific, there was not an announcement of a fourth-generation, honegrown Graviton4 processor that many had expected given that AWS, like other cloud …
The Sugar Daddy Boomerang Effect: How AI Investments Puff Up The Clouds
Here’s a question for you: How much of the growth in cloud spending at Microsoft Azure, Amazon Web Services, and Google Cloud in the second quarter came from OpenAI and Anthropic spending money they got as investments out of the treasure chests of Microsoft, Amazon, and Google? We think this …
We need to not get caught up in the hype and remember that Public Clouds are simply another form of selective IT Outsourcing.
Private Clouds are where most companies are headed for most of their important workloads. The reason is simple – while many state security as their biggest concern about public clouds, the real issue is lack of control over Security and Data POLICY that is the biggest reason to keep control over IT.
While cost is certainly a factor, the biggest driver to moving to private clouds is improved service delivery while at the same time getting more value for $’s spent.
To accomplish this, an integrated stack with proactive service management strategies that resolves issues before they impact the business requires CI alerts, traps ect. to be integrated with the companies service desk architecture and three tier support model. In addition, the private cloud (aka internal shared services that has been around for decades) uses the same basic principles of standardization, virtualization, automation and rationalization integrated with a ITSM based service catalogue.
Kerry
How is this different from the Huawei UDSN (universal distributed storage node), announced back in 2012 as part of its OceanStor system?
http://enterprise.huawei.com/ilink/cnenterprise/download/HW_259595
“UDS capacity expansion is based on its UDSNs (smart disks), each of which consists of a disk drive with an energy-efficient ARM chip, smallcapacity memory, and an Ethernet interface. “
Clearly they are very similar, and thanks for the heads up since I did not know this existed. I guess one difference is the market model, with the management being done by Igneous and the annual subscription model, too.
“The software for the S3 service running atop the Igneous Data Service is all internally developed and closed source, just as it is at all of the cloud providers, by the way. ” — Clouds like Helion and Rackspace run on open source. Most of telco/cell clouds are like that too.