

Chocolate and peanut butter, tea and scones, gin and tonic, they’re all great combinations, and today we now have a new binary mixture — Quantum and AI. Do they actually mix well together? Quadrant, a new spin out from D-Wave Systems, certainly seems to think so.
D-Wave has been in the quantum computing business since 1999, raising in excess of $200 million from Goldman Sachs, Bezos Expeditions and others, they now list folks such as Google, NASA, Los Alamos National Laboratory and Volkswagen as examples of their signature customers. Quadrant is basically the new AI play from the D-Wave team, blending quantum annealing technology on the back end with a dash of machine learning on the front end.
D-Wave has focused on the class of quantum machines that are based on a quantum annealing algorithm, its first machine – the 128 qubit D-Wave One – entered the market in 2011. It turns out that this annealing-based quantum computer had some unintended advantages in a world dominated with traditional CPU/GPU machine learning.
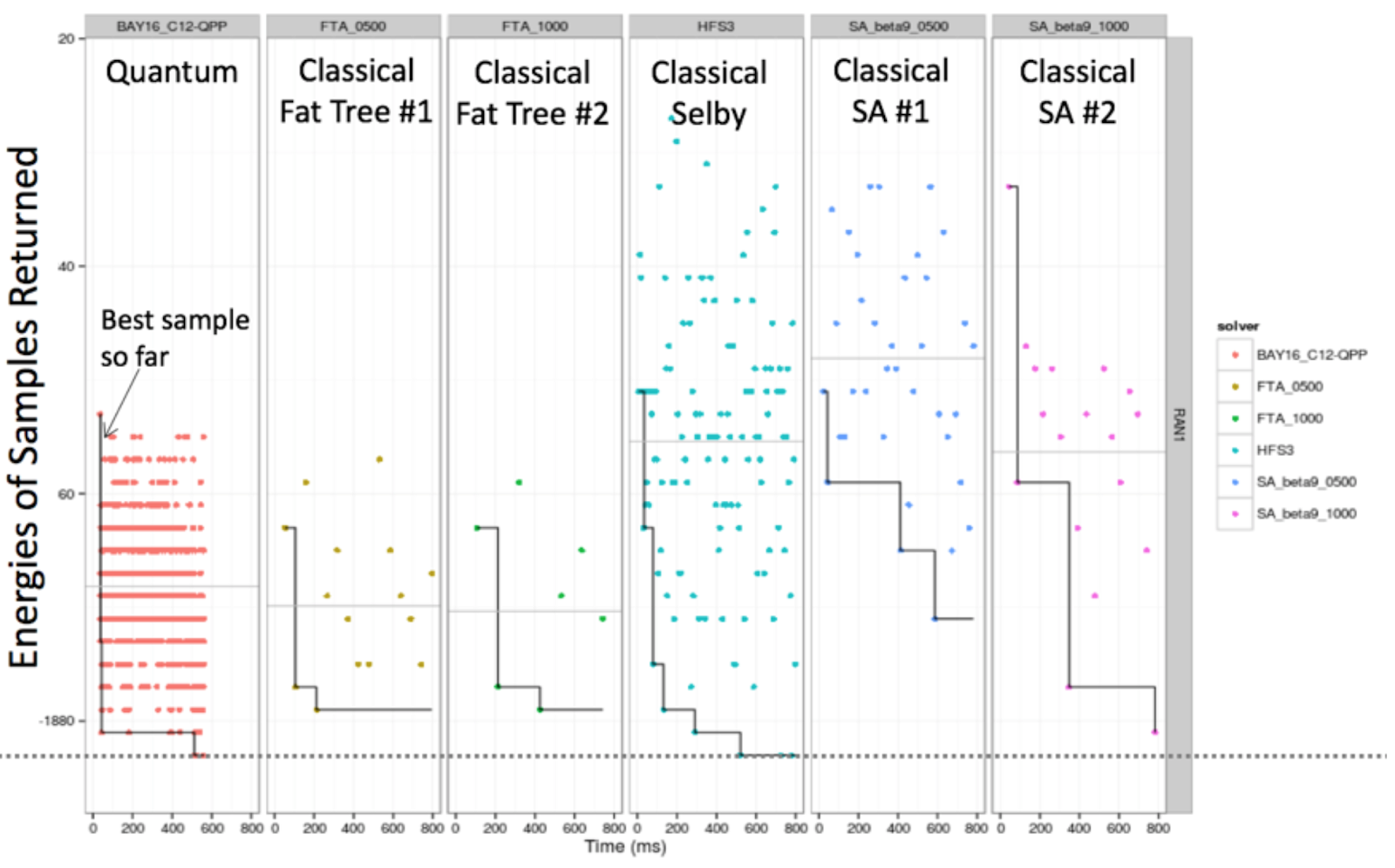
In setting up the Quadrant business, rather than directly compete for quantum supremacy, D-Wave has taken a different approach with its current 2000Q qubit machine, using it as a feeder for a more traditional CPU/GPU neural network system. It is a hybrid approach that only works if the architecture is annealing based. (Remember, D-Wave’s systems are different from the gate model approaches from IBM and Google.) In the graph below that compares quantum annealing with classical fat tree and simulated annealing, the quantum method naturally generates many high probability (low energy) results in significantly less time than the traditional simulation methods.
To understand more, The Next Platform spoke with Handol Kim, senior director of Quadrant machine learning at D-Wave. “Machine learning has the potential to accelerate efficiency and innovation across virtually every industry,” says Handol. “Quadrant’s models are able to perform deep learning using smaller amounts of labeled data, and our experts can help to choose and implement the best models, enabling more companies to tap into this powerful technology.” What Handol is describing here is the coupling of traditional machine learning with a system that supports quantum annealing algorithms that naturally generates results in less time than more classical algorithms. Back in the 1980s in the depths of the AI Winter, many of these Boltzmann, or energy based, computational methods were abandoned due to the sheer amount of compute that would have been needed. Now, with the ability to build quantum systems to quickly produce likely energies based on quantum annealing effects, those doors have essentially been reopened, if only a crack.
When we suggested that this is effectively converting the more traditional computationally intensive “simulated annealing” approach into more of what we termed “observed annealing,” by essentially reading off the results from the quantum part, Handol agrees, and adds that the real power of this approach was the concept of generative learning. The claim is that this generative learning method can do significantly better on data with minimal labels or datasets with an insufficient quality of labels. Quadrant’s generative models combine the flexibility of deep neural nets with more probabilistic graph models.
Quantum Surgery
To give an example of how the method performs on such weakly labeled data, Handol pulls up recent results in the healthcare field, specifically with cataract surgery. Cataract surgery is the most common surgery in the world, with 19 million interventions being carried out each year. As is often the case in modern AI, in order to benchmark the efficiency of methods, a contest called CATARACTS, short for Challenge on Automatic Tool Annotation for cataRACT Surgery, was initiated.
The contest takes 25 training videos with an average length of 11.3 minutes or 20,000 frames, from which per frame binary annotations for 21 surgical tools are constructed. The goal was to train a classifier to predict the presence of each tool in unseen surgical videos. It turns out that 500,000 frames often isn’t enough data to train deep classical AI models. For example, some surgical tools are very scarce and only appear in one video.
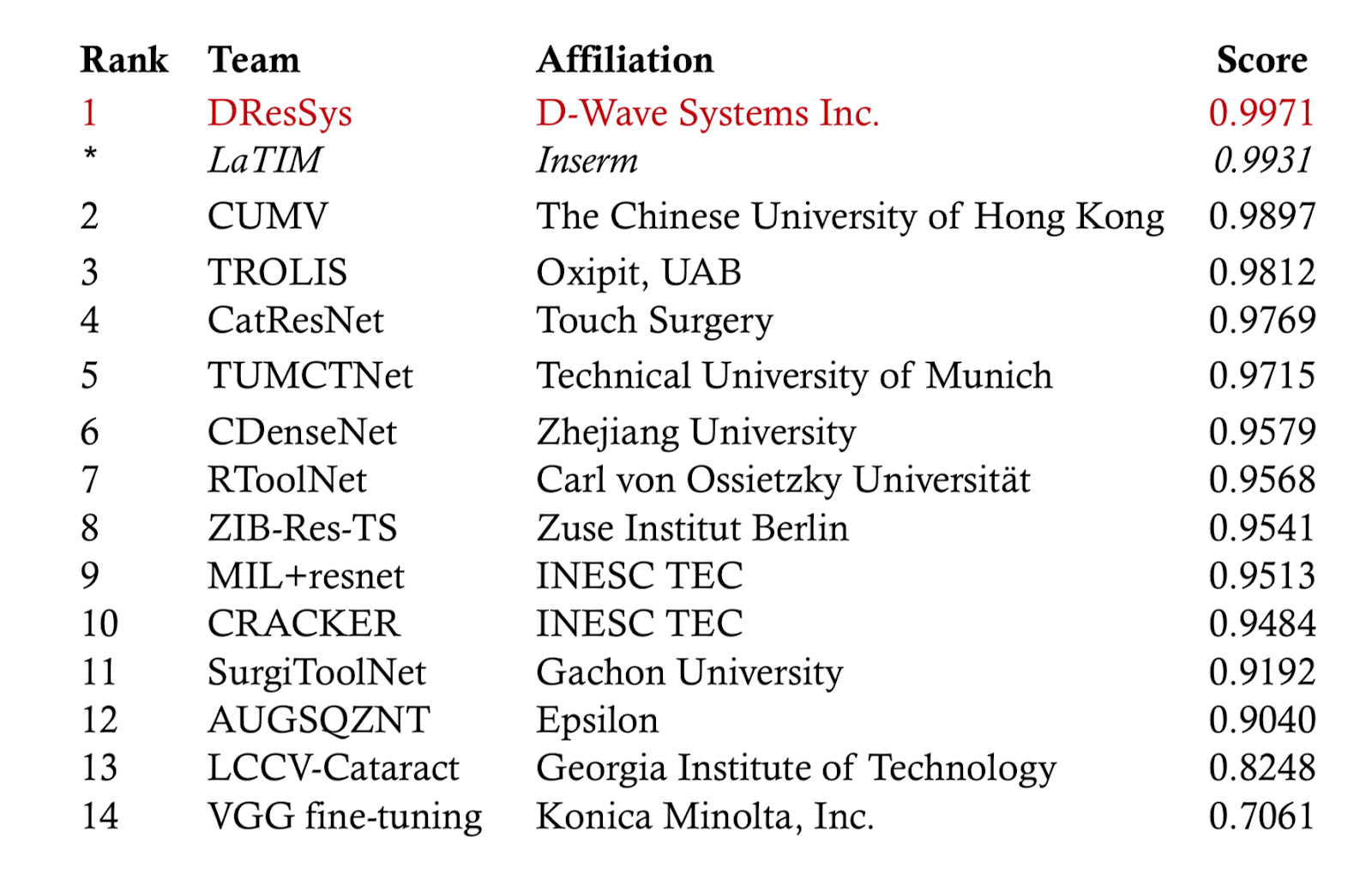
Quadrant, collaborating with alongside the Siemens Healthineers, a medical technology company that is part of the Siemens conglomerate, used a two stage approach using its Akros system to process the video frame by frame and then incorporate temporal smoothing from Quadrant. The tests initially reached 99.19 percent on its aggregated models for the validation set. By applying Markov random fields on the output, the accuracy could be bumped up to 99.77 percent. This managed to rank the D-Wave hybrid approach as number one in the final tests, beating out LaTIM the second place system at 99.31 percent. See the table below:
This cataract surgery result shows great promise, Bill Macready, senior vice president of machine learning at D-Wave, says. “Quadrant has the potential to unlock insights hidden within data and accelerate innovation for everything from banking and quantitative finance, to medical imaging, genomics, and drug discovery.”
We see that Quadrant is a long way from being finished in working out how to best couple quantum computing and AI as the proverbial market winning “chocolate and peanut butter” combination. However, Quadrant did make a solid analogy in its discussion of this challenge of labeled versus unlabeled data. It involved rocket ships. If AI is the rocket ship, you need both a large engine and lots of fuel. With a small engine and large amounts of fuel, you won’t have enough energy to lift off; with a large engine and a small amount of fuel, you won’t reach orbit. Quadrant claims that the rocket engine is the deep learning model and the fuel is the amount of labeled data you can feed into that algorithm, and says that with its generative learning approach you can essentially make enough high quality fuel from your low octane data. It is a nice metaphor, and makes sense particularly when your data has high dimensionality, but you don’t have a lot of it, which is the case in a number of data science domains.
Importantly, because quantum supremacy is still many years in the future, it appears at first glance that using a hybrid combination of quantum computing with more traditional CPU/GPU computing actually makes for a good match, at least based on these very early results.


Quantum Computing Providers Pick Their Dance Partners
Toward the end of 2019, a flurry of announcements by some of the most prominent IT companies suggests that collaborations will become increasingly important in the quantum computing space as the players jockey for position in the nascent market. The companies in question include some of the biggest in the …

Why AWS Could Own the Future of Quantum Computing
Without any of its own hardware and most of its software heavy-lifting dedicated to front-end development, security, and broader AWS systems integration, the cloud giant could own the quantum computing user base. The reasons are simple, even if the business could get complicated. We often talk about future leadership in …

Testing the Limits of a Quantum Hardware Market
D-Wave today announced another milestone in its quest to keep adding qubits, jumping from the previous generation 2000 qubit device to one with 5000. This is a notable achievement that doubtlessly will be written to death elsewhere from a quantum progress point of view but should probably be discussed from …
Be the first to comment