

There has been a lot of research and development devoted to bringing the Arm architecture to servers and storage in the datacenter, and a lot of that has focused on making beefier and usually custom Arm cores that look more like an X86 core than they do the kind of compute element we find in our smartphones and tablets. The other way to bring Arm to the datacenter is to use more modest processing elements and to gang a lot of them up together, cramming a lot more cores in a rack and making up the performance in volume.
This latter approach is the one that British server maker Kaleao is taking with its KMAX line of machines. The KMAX servers are the culmination of work done by a team led by John Goodacre, a professor of computer architectures at the University of Manchester, the director of technology and systems at chip designer ARM, and co-founder and chief scientific officer at Kaleao. The development work that the Kaleao team is founding its product line upon has been funded from various sources, as we explained in detail in August 2016, importantly including the European Horizon 2020 program, an €80 billion effort spanning 2014 through 2020 to spur research and innovation in all kinds of fields relevant to the competitiveness of Europe in the global economy.
Kaleao shipped the first of its KMAX machines late last year, and after some feedback from those engaged in proof of concept testing, has modified the iron a bit to make it better suited to specific use cases in the datacenter. The founding principles of the KMAX machines are similar to those espoused by Facebook in the creation of its various microservers, namely that sometimes a collection of relatively modest processors tightly packed in an enclosure can do the same work for less money and with a lot less power and cooling overhead than a collection of commodity X86 servers with far fewer but brawnier cores and processors comprised of them. Facebook has compelled Intel to create the Xeon-D processors to suit its microserver purposes at large scale, which Intel has also sold as storage controllers and within other embedded servers. Kaleao, being British and wanting to push European technology as much as possible, instead basing its initial machines on the Arm architecture.
Specifically, the KMAX system uses the Exynos 7420 processor developed by Samsung for its Galaxy S6 smartphones, which includes a four-core Cortex-A57 processor complex from Arm running at 2.1 GHz paired with a less brawny four-core Cortex-A53 complex running at 1.5 GHz. The Cortex-A53 cores are used for system and management functions, and only the Cortex-A57 cores are used for compute. The chips are etched in a 14 nanometer process and made by Samsung itself, and they support low profile DDR4 main memory and also have an embedded Mali-T760 MP8 GPU included in the complex.
The KMAX compute node has four of these Exynos 7420 processors on them, which you can see on the left hand side in the image below:

The KMAX system has fully converged storage and networking alongside the compute, with a couple of switches embedded on the node and 4 GB of DDR4 memory and 128 GB of flash memory per processor, the latter of which supplies the I/O bandwidth equivalent of around 300 SATA disk drives, all local to each processor. Each server has a pair of 5 Gb/sec Ethernet ports coming off of it.
This fully converged approach is an important distinction. Rather than disaggregating components as the hyperscalers and cloud builders are doing – they separate storage from compute and aggregate across vast and fast Clos networks that span a datacenter of 100,000 nodes – the KMAX design brings memory, storage, and networking down to a single block and then scales the number of those blocks out to support ever-larger workloads. In a sense, the compute is distributed alongside of the storage on which it chews, with network embedded close to it so the network bottleneck that is seen with other converged systems (servers plus network) or hyperconverged systems (virtual compute and virtual storage) is largely eliminated. Those embedded switches create a system-wide fabric that is far cheaper than beefier networks, too, which brings the overall cost of the system down, Goodacre tells The Next Platform. Four of these compute nodes are put onto a KMAX blade, with a Xilinx Zync FPGA being used to implement various protocols – the Partitioned Global Address Space (PGAS) memory addressing scheme for coherency within a node and the Message Passing Interface (MPI) protocol for sharing memory across nodes. Those FPGAs sit between the compute and 16-port Ethernet switches on each blade, and represent a kind of memory and network offload at the blade level. The 10 Gb/sec downlinks on the switches are used to link the pair of 10 Gb/sec links that come off each compute node, and a pair of 40 Gb/sec uplinks are used to link multiple KMAX enclosures to each other and to the outside world. Here is the block diagram of what this looks like:
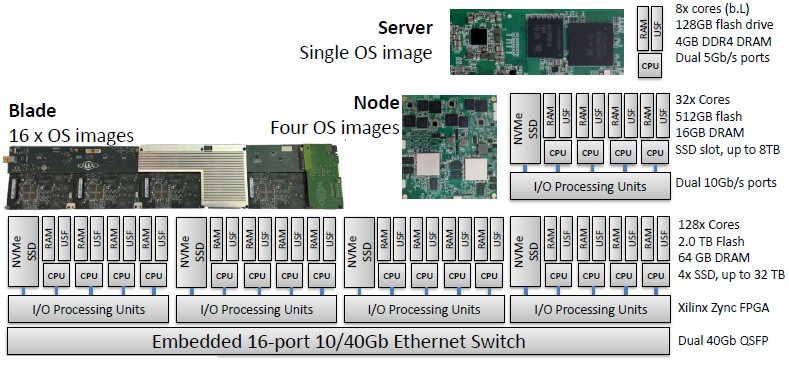
A dozen of these KMAX blades fit into a 3U rack-mounted enclosure, which has a total of 128 cores (half relatively big ones and half relatively small ones), 64 GB of memory, 2 TB of embedded flash on the compute nodes (delivering around 450 MB/sec of bandwidth for each server, or around 80 GB/sec per chassis and around 10 million I/O operations per second), plus up to 32 TB of NVM-Express flash SSDs per blade for storage external to the nodes within the chassis. A standard 42U rack has 14 of these 3U enclosures in it, for a total of 10,752 worker cores (and an equal number of smaller utility cores), 10.5 TB of main memory (1 GB per worker core), 344 TB of local flash, 5.2 PB of NVM-Express flash with about 50 GB/sec of aggregate bandwidth, and a total of 13.4 Tb/sec of aggregate Ethernet bandwidth across that tiered network.
The existing KMAX-HD chassis was able to pack 42 kilowatts into a 42U rack, but the enclosures were a little bit deeper than standard racks to accomplish this. This KMAX-HD chassis had external 48 volt DC power supplies, which allowed multiple enclosures to hang off those supplies. It looks like this:

Early enterprise adopters wanted a standard-depth server rack, and so Kaleao bent some tin to create the KMAX-EP chassis. This setup comes with a 4U enclosure, which is much less demanding in terms of power and cooling density. It supports a dozen blades as the original chassis did, and that extra height is used to allow all of the components to fit into a regular-depth rack. The new KMAX-EP chassis also uses standard 120 volt AC power supplies and has 48 volt DC power as an option. Importantly, this enterprise option also has all of the cables and access coming out of one side, as seen here:

Either way, customers end up with 192 Linux images per enclosure, although the KMAX-EP does not offer the same compute density since only ten enclosures can fit into a single 42U rack. The KMAX-EP 28.5 percent lower compute density across a rack, however, and that means a rack only delivers 7,680 worker cores.
The real issue is how a KMAX rack will compare to a rack of two-socket Xeon E5 or Xeon SP servers, and a lot depends on the workload.
“If we look at a single thread on KMAX, it varies between a third of a Xeon thread all the way up to actually beating it by a bit,” Goodacre tells The Next Platform. “For code that has been optimized for using the very wide SIMD and other features of the Xeon, you can see the Arm core run three or even four times slower. But other code takes very good advantage of the Arm caching architecture and can actually beat a Xeon. On average, if you just load up Linux and a web stack and a WordPress content management benchmark, we are seeing about 50 percent of the performance of a thread on a 2.5 GHz Xeon E5 processor. That means that one of our 3U KMAX enclosures has the equivalent of 48 Xeon E5s in it.”
Chew on that for a second. Let it sink in. OK, now let’s talk about the money to drive it all home. That KMAX-HD machine costs about $3,000 per node, according to Goodacre, and each blade has four nodes and there are twelve of them in a chassis. That’s $144,000 for the base compute, memory, storage, and networking all rolled in, including system management. If you add in four dozen 1 TB NVM-Express drives for the enclosure (four per blade), that takes the price up to around $180,000.
Let’s compare this to the same number of X86 servers needed to handle the same WordPress workload of 25,000 pages per second per node on the KMAX-HD. A single Xeon E5-2690, says Goodacre, which has 14 cores running at 2.6 GHz, has the same 25,000 pages per second of oomph on WordPress. With similar configurations of memory and storage per unit of capacity, a pair of racks of Dell 7000 series Xeon E5 servers would cost $8,000 a pop, and after adding in a pair of Ethernet switches – and without management software – the X86 cluster would cost around $500,000.
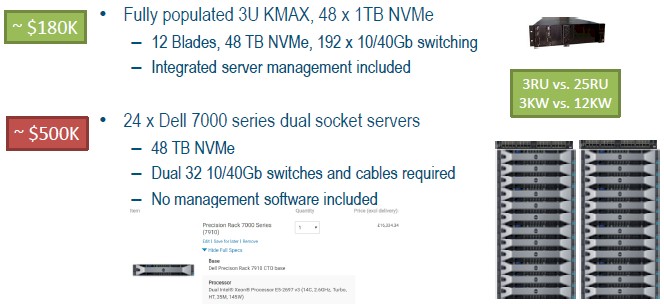
That is 2.8X more money for the X86 setup, and with 8.3X the amount of space and 4X the power compared to the single KMAX-HD chassis.
Goodacre realizes full well that not every workload can run on this Arm system, and that is why it has partnered with OnApp to bring its cloud management and hyperconverged storage software to bear to be able to deploy workloads on a hybrid clusters that mix KMAX and X86 iron side by side. This OnApp HCI software is leveraging the FPGA offload of storage and network processing, by the way.
As for the future, Kaleao is looking to add various kinds of accelerators to the architecture, with GPUs and FPGAs (above and beyond the ones it has already for I/O and memory processing) being the obvious candidates. There is always the possibility that the KMAX architecture could adopt beefier Arm processors, from say Cavium or Qualcomm, into the enclosures, too, to provide a unified Arm platform.
Early adopters of the KMAX systems are doing web infrastructure with OpenStack and video streaming, but it would be very interesting indeed to see this KMAX system run some machine learning inference and embarrassingly parallel HPC workloads that rely on integer processing, such as genomics. There are lots of possibilities, and Kaleao is only just getting started.

Intel Is Counting On AI Inference To Save The Xeon CPU
There is little question that generative AI as well as other kinds of machine learning are going to augment applications in every industry and in every part of the application stack in the coming years. It is also pretty obvious that AI training for the most advanced models, with trillions …
The Third Time Charm Of AMD’s Milan Epyc Processors
With every passing year, as AMD first talked about its plans to re-enter the server processor arena and give Intel some real, much needed, and very direct competition and then delivered again and again on its processor roadmap, it has gotten easier and easier to justify spending at least some …
Supermicro Sets Its Sights On $20 Billion Business
Only a few years ago, motherboard and system maker Supermicro set a target of breaking through $10 billion in sales, and thanks to the explosion in systems for training and inference for AI applications, it looks like the company is going to bust through that goal in its fiscal 2025 …
Be the first to comment