

The HPC field hasn’t always had the closest of relationships with the cloud.
Concerns about the performance of the workloads on a hypervisor running in the cloud, the speed of the networking and capacity of storage, the security and privacy of the research data and results, and the investments of millions of dollars already made to build massive on-premises supercomputers and other systems can become issues when considering moving applications to the cloud.
However, HPC workloads also are getting more complex and compute-intensive, and demand from researchers for more compute time and power on those on-premises supercomputers is growing. Cloud computing has made it easier for enterprises to get the compute power and storage capacity they need for many of their workloads, and the HPC market is warming to the cloud for many of the same reasons.
One of the benefits of the cloud for enterprise and HPC organizations alike is the ability to “burst” workloads onto the cloud when in-house computing resources run tight, enabling them to leverage the resources in public clouds like Amazon Web Services (AWS), Microsoft Azure and Google Cloud Platform to continue running their applications without having to invest in more on-premises infrastructure to meet peak demand.
Adaptive Computing, a longtime player in the HPC space with its cluster management and monitoring tools, has recently been looking to make it easier for HPC customers to burst their workloads into the public cloud when in-house resources run low. The company in January ran out the first iteration of its Moab/NODUS Cloud Bursting solution for customers running its Moab job scheduler, and this month unveiled version 1.1.0 of the software. The solution ties Moab with the vendor’s NODUS Platform managing compute nodes in the cloud, giving HPC users the ability to more easily manage and configure the cloud-based nodes handling the workload overflow and to integrate those nodes with the customer’s on-premises infrastructure.
The company is running five demos on customer sites currently, with four of those organizations looking to move into the proof-of-concept (POC) phase, an indication that HPC users are embracing the idea of leveraging public clouds to ensure their work can get done, according to Arthur Allen, president of Adaptive Computing.
“Based on the live demos and other comments back from the market place, we feel there are three ways people want to burst: they want to burst based on backlog, so burst from the backlog queue; they want to burst on a high-priority job, so if that job has no resources to run, they want to burst on that one job; and/or they want to burst on demand,” Allen told The Next Platform.
“One the customers mentioned he has no problem keeping jobs on the queue for weeks at a time and would burst to up to 10,000 nodes or so during certain times of years and not really burst other times,” said Brad Serbu, NODUS engineer at Adaptive. “So we’re looking at a variety of different ways to flavor and target the bursting scenario. … What we try to do to make cloud effective and allow enterprises to leverage the resources and go after that market, whether that’s the HPC market or the cloud market at large. Cloud’s been around for a while, adoption rates are increasing, but they’re still low, and we think that’s because there’s not enough solutions that offer out of the box, sort of seamless ways of using the cloud that are both cost-effective and work in the scenarios that they’re used to. Our cloud bursting release really aims to go after that in the HPC space.”
Adaptive Computing is working now to give its Moab customers the tools they need to easily burst over the cloud, and also is planning to expand its capabilities to customers who may use schedulers other than Moab. The cloud-bursting solution is part of a larger strategy to support its current lineup of more than 300 current customers while extending its presence beyond HPC and farther into the enterprise space.
Essentially how it works is when the Moab scheduler senses the SLA of workload is about to be violated, such as if there is job backlog, it sends out a request to burst over to a public cloud. At the same time, the NODUS Platform provisions, configures and deploys the necessary nodes in the cloud to handle the workload that is moving into the cloud, and integrates those nodes with those in the user’s datacenter. Once the cloud nodes are no longer needed, NODUS gets rid of the cloud nodes. The technology supports a range of public cloud providers, including AWS, Azure, Google Cloud, Packet.net and AliCloud, as well as such container platforms as Docker and Singularity and OpenStack and VMware’s vSphere and Cloud Director. The company also is working on bringing bare metal support onto the platform, Serbu said.
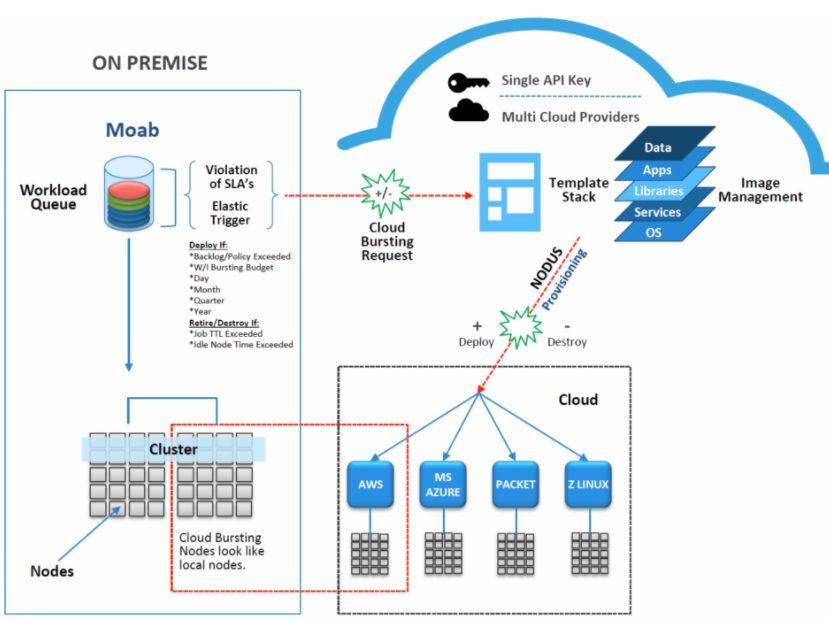
Moab is an Adaptive tool that was built from the Maui open-source program a couple of decades ago, and is primarily used by government, academia and large corporations that run supercomputers in their on-premises environments, according to Tim Shaw, a Moab developer with Adaptive. The bursting capabilities enables the company to serve those Moab users while growing its customer base and adapting to an evolving compute market. Allen said more large commercial companies in such areas as oil and gas and manufacturing are using HPC clusters in their environments, and they also “have budgets, more so than maybe government, research and academia would have, so the market flavor has changed a bit.” So have the business opportunities for vendors like Adaptive: he said there are about 750 locations in North America that run HPC clusters.
The HPC space also continues to evolve, adopting technologies such as GPU accelerators from the likes of Nvidia and AMD and many-core processors like Intel’s Xeon Phi “Knights Landing” chips, as well as fast-growing platforms like containers, all of which the vendor is supporting with its Moab/NODUS cloud bursting solution. Accelerated systems are “somewhat different from your traditional HPC servers, and we’ve put in support for those types with the GPUs and other things to make sure we can support those types of configurations as well,” Shaw said. “Moab has been hanging with the trends that have come over the few years. Otherwise you wouldn’t be able to compete with the marketplace.”
Going forward, the plan expand the cloud-bursting capabilities in the NODUS Platform to support schedulers other than Moab, a scheduler-agnostic offering coming in the second quarter, Serbu said.
“What we’ll have then is the ability to provision and manage the clusters entirely from the NODUS side and choose what scheduler you’d like to provision,” he said. “That will broaden the marketplace for anybody running an HPC cluster. We do have some strengths by having the [Moab and NODUS] products integrated. We provide a more seamless out-of-the-box experience where we’re more able to hook into the actual jobs and workloads in our Moab/NODUS cloud bursting, but for the bring-your-own-scheduler, we want to replicate a lot of those different scenarios into the NODUS platform itself. NODUS will include its own web administration user interface for provisioning a cluster. The user will be able to choose their own cloud provider, choose to spin up the cluster, and then they’ll be able to choose the type of cluster they want to spin up. That could be a cluster for Moab with the agent already pre-installed and that plugs into their Moab cluster. That would be the Moab/NODUS cloud bursting that we have. If the customer has Swarm, we will offer a native scheduler that is part of NODUS for container-based workloads that are more microservices-type oriented, so that’s not a scheduler that is necessarily designed for HPC-type workloads and clusters, but more a general-purpose scheduler will be available for submitting jobs. Then we will have support for Swarm and integration points to allow us to take that solution on-site to any customer and any scheduler they have.”
Customers will be able to burst into any cloud market they want, with an administration interface to manage the cluster and view the status, provisioning templates from Adaptive, “a layer for connecting their cluster that they’re spinning up to any on-premises services that they need. We have workflows that can be used and extended to talk back to an on-premises VPN to augment the provisioning pieces with the IP addresses and host names for the services that they would need to talk to or any of the on-premises resources they have.”


HPC Schedulers Snap To Docker
Over the last couple of years, Docker has become an increasingly popular tool for web-scale companies like eBay, but it appears to finally be catching on for some supercomputing centers. While there is additional complexity built into most HPC stacks, the desire to use Docker matched with key HPC-specific middleware …
Be the first to comment