

It would be surprising to find a Hadoop shop that builds a cluster based on the high-end 68+ core Intel Knights Landing processors—not just because of the sheer horsepower (read as “expense”) for workloads that are more data-intensive versus compute-heavy, but also because of a mismatch between software and file system elements.
Despite these roadblocks, work has been underway at Intel’s behest to prime Knights Landing clusters for beefier Hadoop/MapReduce and machine learning jobs at one of its parallel computing centers at Indiana University.
According to Judy Qiu, associate professor of intelligent systems engineering in IU’s computing division, it is not off-base to find Knights Landing and Hadoop to be strange bedfellows. However, Intel approached the center to see what data analysis jobs might be a fit—and how to tune them for high performance across many cores.
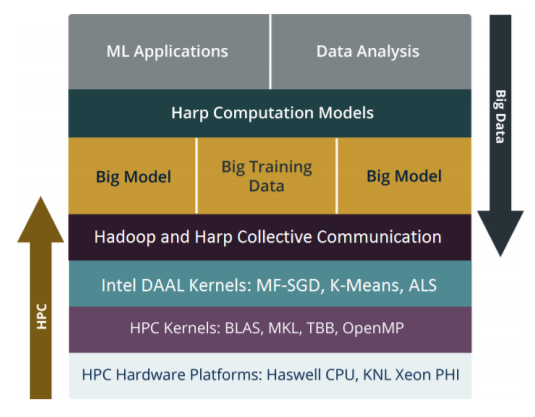
Hadoop’s reliance on Java and Intel’s libraries on C++ are just one of several non-starters for the HPC processor running Hadoop. This is where Qiu’s team started working, beginning with a distributed framework based on Intel’s DAAL analytics libraries designed for high performance data analysis on a single node. They then cobbled together layers for data transformation and copying that could speak both HPC and analytics and meshed together the programming environment into a hybrid C++ and Java base.
The IU team ran several benchmarks to highlight HPC performance on data analysis, including a test across a 64-node InfiniBand connected cluster at the parallel computing center equipped with the 68-core variant of Knights Landing.
The full results can be found here but among those, the most impressive are 15-40X performance over Java-based Hadoop in Spark running on standard X86 Hadoop clusters. Core to this was DAAL working with Harp—an open source project developed at IU that is a plug-in for native Apache Hadoop and provides the high performance communication library that works alongside DAAL.
“Many machine learning applications can be implemented with MapReduce-like interfaces with significantly boosted performance by scaling up. Through evaluating computation and communication-bounded applications, Harp-DAAL combines advanced communication operations from Harp and high performance computation kernels from DAAL. Our framework achieves 15x to 40x speedups over Spark-Kmeans and 25x to 40x speedups to Spark-ALS. Compared to NOMAD-SGD, a state-of-the-art C/C++ implementation of the MF-SGD application, we still get higher performance by a factor of 2.5,” says Qiu.
Qiu says that it is now practical for supercomputing centers to use HPC nodes for data analytics when required with the framework, which is available on GitHub. The next step will be to provide comparisons between Haswell and GPU nodes on the same benchmarks in addition to broadening the range of applications on top of Hadoop.


The Endless Pursuit Of Scale At LinkedIn
There is nothing at all wrong with legacy application and system software as long as it can deliver scalability, reliability, and performance. Changing from one software stack to another is so difficult and so risky — the proverbial changing of the front two tires on the car while going down …
Cloudera Pivots To Data Management As Hadoop Fades
It was only two years ago that Cloudera, once one of the top vendors in what had been a white-hot Hadoop market, found itself fighting for survival. Hadoop, the open-source data analytics technology that a decade ago was seen as the answer to enterprises’ large-scale data analytics and management woes, …

Why the Fortune 500 is (Just) Finally Dumping Hadoop
Remember how, just a decade ago, Hadoop was the cure to all the world’s large-scale enterprise IT problems? And how companies like Cloudera dominated the scene, swallowing competitors including Hortonworks? Oh, and the endless use cases about incredible performance and cost savings and the whole ecosystem of spin-off Apache tools …
Be the first to comment