

Over the last couple of years, Docker has become an increasingly popular tool for web-scale companies like eBay, but it appears to finally be catching on for some supercomputing centers. While there is additional complexity built into most HPC stacks, the desire to use Docker matched with key HPC-specific middleware makers’ know-how about the specific needs is creating a new wave of tools—and demand.
Even though containers are finally receiving mainstream IT attention following the success of Docker, they are not a new concept, and are definitely not a fresh concept in high performance computing. From workload resource isolation, process tracking, job controlling, and checkpoint and restart functions, they have been a go-to, but now several HPC middleware companies are embracing it as part of their approach to HPC datacenter management.
During the OpenPower Summit, held in conjunction with the GPU Technology Conference, IBM outlined its approach to moving Docker into the Platform LSF workload management tooling, we got a closer look into how HPC-specific tuning for Docker has been built into one of the more popular schedulers in the segment from Sam Sanjabi, Advisory Software Engineer for IBM Platform Computing.
“From our view, the OpenPower platform is a datacenter technology—it’s built for the cloud, it’s built to be deployed in complicated environments with a lot of different applications. To us, it seems natural to want to deploy Docker in an OpenPower environment so we have built it into the platform.”
The way LSF works with Docker is similar to how other companies with HPC workload management tools and schedulers are integrating it. In essence, as seen below, the administrator creates Docker images which might have two versions of the same application and pop those into the registry. When the user submits a job to the scheduler, they might submit both versions and let the scheduler pull the appropriate image into the execution node to run inside the Docker container. The value here, as it’s been proven out in mainstream IT and now HPC is that the admin’s job becomes far simpler than before in that she is freed from deploying the many applications that might be running on the cluster—it becomes a matter of creating the Docker images, moving them into the repository, then allowing the scheduler, in this case LSF, orchestrate the rest.
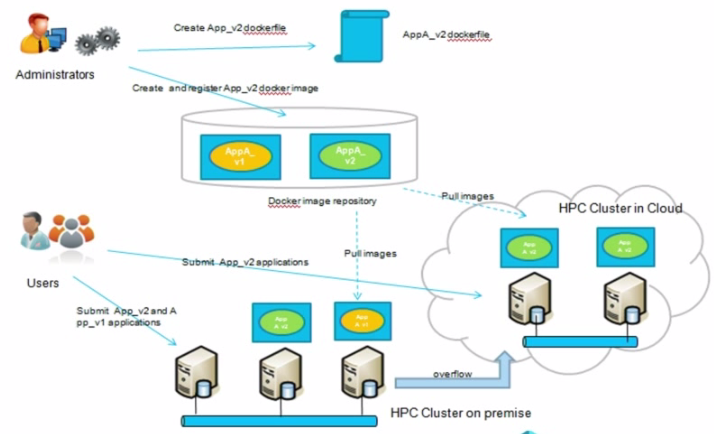
The case for having a more sophisticated approach to managing resources and applications is especially important in HPC where there might be thousands of nodes with different hardware, memory, OS, and other characteristics that are tuned for different workloads. LSF and other HPC schedulers are already primed for pulling the right resources for the job based on extensive policies but as a monolithic scheduler, this is still not a breeze on the application front.
 The benefits of Docker as implemented within the Platform LSF scheduler are the same that the general IT community is espousing, but again, it’s a matter of scale and complexity. Again, HPC centers are often working with a wide range of demanding applications and hardware configurations, so having something to keep that in check is useful. At the core, however, Docker as built into a workload manager like LSF means resource guarantees and performance isolation (using the same concept of Linux control groups), with the addition of providing application encapsulation and the ability to seamlessly jump from different systems (including other clusters or bursting into a cloud resource) without having to bother with changing all the libraries across those other systems. If Docker is installed, users pull the images to the new host and run.
The benefits of Docker as implemented within the Platform LSF scheduler are the same that the general IT community is espousing, but again, it’s a matter of scale and complexity. Again, HPC centers are often working with a wide range of demanding applications and hardware configurations, so having something to keep that in check is useful. At the core, however, Docker as built into a workload manager like LSF means resource guarantees and performance isolation (using the same concept of Linux control groups), with the addition of providing application encapsulation and the ability to seamlessly jump from different systems (including other clusters or bursting into a cloud resource) without having to bother with changing all the libraries across those other systems. If Docker is installed, users pull the images to the new host and run.
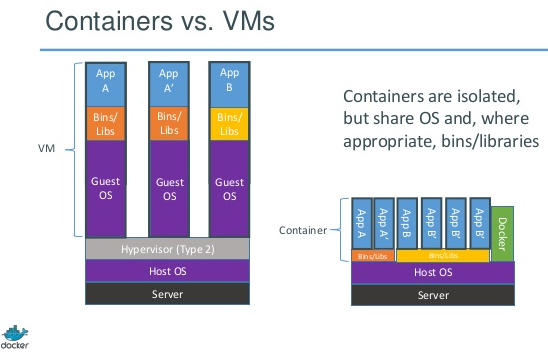
The real benefit of this approach for HPC centers, however is that different versions of applications can co-exist in the same environment without making the admin remember the different paths for all the different versions for a particular host. This also means it’s repeatable, all of which is leading to the argument that this is a much more lightweight, high performance, and transparent way of handling multiple workload and environment complexity than one could get with doing the same thing with virtual machines.
On that note, there was a rather compelling study from IBM Research that took a close look at how different container and virtual machine approaches rank for HPC workloads. There are several such comparison available, in part because since Linux can support both virtual machines and containers, but this was one of the few without vendor influence. Using a host of different workloads that stressed memory, CPU, and I/O in different ways, the team found that when using KVM as the main hypervisor and Docker to handle containers, containers showed equal or better performance than virtual machines in almost every instance.
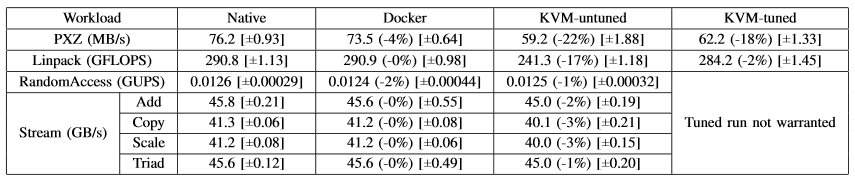
The authors of the study note that even with these results, both the virtual machines and the Docker containers did require some sizable tuning for I/O-heavy operations, which can be seen above. “Although containers themselves have almost no overhead, Docker is not without performance gotchas,” the IBM researchers caution. “Docker volumes have noticeably better performance than files stored in AUFS. Docker’s NAT also introduces overhead for workloads with high packet rates—these features represent a tradeoff between ease of management and performance and should be considered on a case by case basis.”
Accordingly, there are several HPC workload management and scheduler tools that are equipped with Docker aside from IBM Platform LSF. Adaptive Computing is another vendor that offers hooks into Docker containers and in recent conversations Univa, which is the commercial entity providing support for Grid Engine, told us that it is hard at work on its own Docker implementation.


Making The Red Hat Platform Bet Pay Off For Big Blue
In the long run of the history of International Business Machines, a conglomerate established back in 1911 whose Electric Tabulating System was custom built by Herman Hollerith for the federal government in the United States for the 1890 census and then commercialized, the acquisition of Red Hat by Big Blue …

This Is What The Most Powerful Server In The World Looks Like
While we are big fans of distributed computing systems here at The Next Platform, we never forget our heritage in big iron. And we never forget the important place that big, fat, shared memory NUMA systems still play in the spectrum of compute in the datacenter. And we like big …
The Financial Longevity That Red Hat Gives IBM
It is hard to imagine, but someday, IBM may not care much about its proprietary System z and Power Systems platforms. Or, more precisely, it may not be able to afford to care the way it has for decades But the good news for Big Blue is that it has …
Be the first to comment