

The gap between what a hyperscaler can build and what it might need seems to be increasing, and perhaps at a ridiculous pace. When the networking industry was first delivering 40 Gb/sec Ethernet several years back, search engine giant Google was explaining that it would very much like to have 1 Tb/sec switching.
And as we enter the epoch of 100 Gb/sec networking and contemplate perhaps delivering 1 Tb/sec Ethernet gear maybe in 2020 or so, Google has once again come forward and explained that what will be really needed soon is something closer to 5 Pb/sec networking.
You heard that right.
In a recent presentation where Amin Vahdat, a Google Fellow and technical lead for networking, gave some details on ten years’ worth of homemade networking inside of the company, he said “petabits per second.” This, in a 2015 world where getting a switch to do something north of 6 terabits per second out of a single switch ASIC is an accomplishment. Forget for a second that the Ethernet industry has no idea whatsoever about how it might increase the switching bandwidth by close to three orders of magnitude. The math that Vahdat walked through is as fascinating as it is fun.
“We are particularly excited about networking because we think networking will be playing a critical role in what computing means going forward,” Vahdat said in something of an understatement. There are two issues that hyperscalers will be struggling with as they build massive warehouse-scale datacenters with hundreds of thousands of servers and convert some of these machines (as Google, Microsoft, and Amazon have done) to public clouds for others to use. The first issue is that the I/O gap between storage and compute continues to grow, and it is being exacerbated by non-volatile storage like flash – and soon to be other technologies that are lower cost, higher speed, higher capacity and therefore even more attractive and widening the gap even further.
The second issue is that this I/O gap will compel companies to cram as much infrastructure in the smallest space possible to limit the latencies between compute and storage. And, equally importantly, from Google’s own experience running extreme-scale applications, scheduling work on 10,000 nodes is far easier than scheduling the same work on ten clusters with 1,000 nodes each. “The differences work out to be quite stark,” Vahdat said, without getting into any detail there.
The point is, the I/O gap between compute and storage and the desire to be more efficient in scheduling work on compute will both put tremendous strain on datacenter networks.
Without conceding that this is what the network load looks like inside of Google necessarily, Vahdat tossed up this slide, which gave the feeds and speeds of certain aspects of a network operating at the low-end of hyperscale:
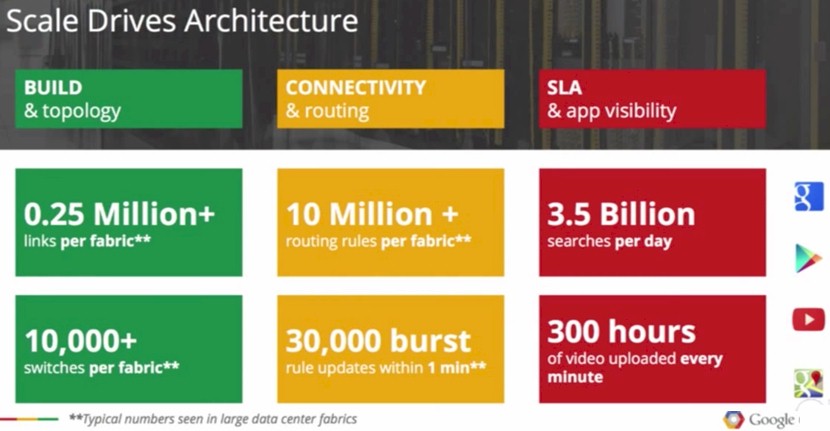
The most important thing for any network, whether it is operating at hyperscale or not, is balance. The compute and storage and the networks that lash them together have to be balanced, because if they are not, that means some resource – it could be any single one of the three, or even two of the three – is scarce and that will then limit the value you can extract from the other resources. If you have too much compute or storage capacity (more I/O capacity than actual physical storage capacity) relative to each other, that means some resource will be idle and that will increase overall costs. Ideally, you would overprovisioning the network relative to both compute and storage, and by overprovisioning we don’t mean oversubscribing the network bandwidth by a factor of two or three, but literally having so much bandwidth and low latency that there are no issues in keeping compute in synch with storage.
“We tend to underprovision the network because we don’t know how to build big networks that deliver lots of bandwidth,” explained Vahdat, which is why Google ended up designing and building its own datacenter switches, network operating systems, switch fabrics, and control systems starting a decade ago.
To illustrate the issues facing datacenter and system designers in the future, Vahdat brought up another of Amdahl’s Laws, the one that says you should have 1 Mbit/sec of I/O for every 1 MHz of computation to maintain a balanced system in a parallel computing environment. And pointed out that with the adoption of flash today and other non-volatile memories in the future, which have very high bandwidth and very low latency requirements, keeping the network in balance with compute and storage is going to be a big challenge. This is the hypothetical math that Vahdat did on a datacenter with 50,000 servers in it:
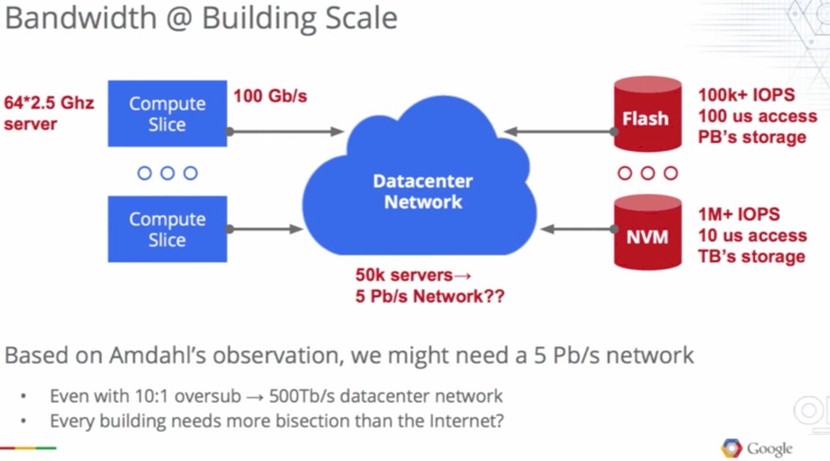
The servers used in the above hypothetical datacenter are using 32-core processors running at 2.5 GHz and they have 100 Gb/sec ports reaching out into the datacenter network. This is a few years away, perhaps, but not all that many. Flash in storage systems will weigh in at petabytes of capacity and will be able to generate hundreds of thousands of IOPS and have latencies on the order of hundreds of microseconds. That future NVM memory, whatever it might be, will deliver millions of IOPS in its tier, with terabytes of capacity, and have very low latencies on the order of tens of microseconds. For 50,000 servers running at those clock speeds, Amdahl’s lesser law suggests, according to Vahdat, that we need a 5 Pb/sec network. And even with a 10:1 oversubscription rate on the network, you are still talking about needing a 500 Tb/sec network.
To put that into perspective, Vahdat estimates that the backbone of the Internet has around 200 Tb/sec of bandwidth. And bandwidth is not the only issue. If you want that NVM memory to be useful, then this future hyper-bandwidth network has to provide 10 microsecond latencies between the servers and the storage, and even for flash-based storage, you need 100 microsecond latencies to make the storage look local (more or less) to the servers. Otherwise, the servers, which are quite expensive, will be sitting there idle a lot of the time, waiting for data.


Nvidia’s Enormous Financial Success Becomes . . . Normal
For the past five years, since Nvidia acquired InfiniBand and Ethernet switch and network interface card supplier Mellanox, people have been wondering what the split is between compute and networking in the Nvidia datacenter business that has exploded in growth and now represents most of revenue for each quarter. Now …

Mellanox Doubles Up Ethernet Bandwidth With Spectrum-3
The relentless need for bandwidth is probably something that all of us are well aware of these days in our home lives thanks to the coronavirus outbreak. Now we can all appreciate at a fundamental level what it feels like in the datacenter most days, and why Ethernet switch ASIC …
With “Ironwood” TPU, Google Pushes The AI Accelerator To The Floor
If you want to be a leading in supplying AI models and AI applications, as well as AI infrastructure to run it, to the world, it is also helpful to have a business that needs a lot of AI that can underwrite the development of homegrown infrastructure that can be …
Comment from an old mainframe dog: Incredible!