

Because space costs so much money and having multiple machines adds complexity and even more costs on top of that, there is always pressure to increase the density of the devices that provide compute, storage, and networking capacity in the datacenter. Moore’s Law, in essence, doesn’t just drive chips, but also the devices that are comprised of chips.
Often, it is the second or third iteration of a technology that takes off because the economics and density of the initial products can’t match the space and power constraints of a system rack. Such was the case with the initial 100 Gb/sec Ethernet products that came to market a few years back and that made sense only for network backbones where the need for 100 Gb/sec connectivity trumped any other factors such as cost or density, which was good in a way because the 10 Gb/sec signaling used in these products was woefully power hungry and too costly. The hyperscalers, led by Google and Microsoft, essentially forced the hand of the switch ASIC makers and forced them to create 100 Gb/sec switch chips that used 25 Gb/sec lanes and offered 25 Gb/sec and 50 Gb/sec connectivity at the server and 100 Gb/sec at the top of rack switch that was more compelling than the existing 40 Gb/sec technology that they were using in their racks at the time.
Broadcom, Mellanox Technologies, and Cavium (through its XPliant acquisition) were early and enthusiastic supporters of this 25G effort. Broadcom developed its “Tomahawk” chips, announced in September 2014 and shipped them first in switches made by Dell as soon as the chips were back from the foundry in the spring of 2015. XPliant dropped out of stealth the same month that the Tomahawks were announced and Cavium bought the 25G Ethernet upstart for $60 million in cash and stock (plus $15 million in seed investment) at the same time. In June 2015, Mellanox rolled out its “Spectrum” 25G products, including 100 Gb/sec switches and 25 Gb/sec adapters, which started shipping later that year. Cisco Systems came a little late to the party, but shipped switches based on its Cloud Scale ASICs starting in March of this year. Dell, Hewlett-Packard Enterprise, Arista Networks are big users of the Broadcom Tomahawk ASICs in their switches, as are a number of suppliers. Cavium has not revealed any design wins for its XPliant CNX chips among the big switch makers, and as far as we know, Mellanox is the only supplier of Spectrum-based switches.
The reason why the hyperscalers were so keen on creating and then pushing the 25G standard is simple. They were unhappy with the bandwidth, cost per bit, power consumption, and heat dissipation of existing 40 Gb/sec and 100 Gb/sec switches, which were based on chips using 10 GHz serializer/deserializer (SerDes) communication circuits that, after overhead is taken out, delivered 10 Gb/sec per lane of traffic. By using 25 GHz SerDes and delivering 25 Gb/sec per lane, the switch chips adhering to the 25G Ethernet standard could deliver 2.5X the bandwidth per lane at a cost of around 1.5X more per lane and about half the power per port. If history had progressed as normally, then the 40 Gb/sec Ethernet generation would have been 100 Gb/sec with 25 Gb/sec SerDes years ago. But at the time, using the same 10 Gb/sec lanes that made 10 Gb/sec switches possible and then crafting 40 Gb/sec switches by quadding the lanes up was the only way to get faster switching in a timely fashion. (And something that the hyperscalers and telcos were also pushing back then, by the way.)
The top-end Tomahawk ASIC has 680 Mb (85 MB) packet buffer and supports 3.2 Tb/sec of aggregate switching bandwidth. It can drive 32 ports at 100 Gb/sec, 64 ports running at either 40 Gb/sec or 50 Gb/sec, or 128 ports running at 10 Gb/sec or 25 Gb/sec. The Tomahawks can do a port-to-port hop in 400 nanoseconds or less, which is pretty fast; the chips support RDMA over Converged Ethernet (RoCE) direct memory access technology to get that low latency, a technique that was borrowed from InfiniBand, which still has a latency advantage at 100 Gb/sec speeds.
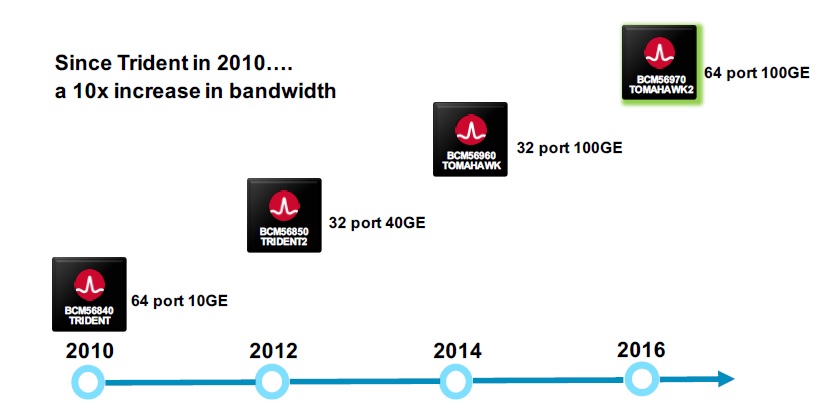
With the Tomahawk-II ASICs that Broadcom has just unveiled, the company is going to crank up the throughput of the switch ASIC for 25G-style switches and also double up the number of ports that can be crammed into a 1U device.

Broadcom is being a little vague about the specifics of the Tomahawk-II chip, which is known as the StrataXGS BCM56970 chip in the company catalog, but Nick Kucharewski, vice president of product marketing for the Switch Products Group, tells The Next Platform that the updated Tomahawk chip has twice the number of SerDes circuits running at the 25 Gb/sec per lane speeds, which doubles up the aggregate switching bandwidth to 6.4 Tb/sec across the single ASIC.
That is, significantly, ten times the bandwidth that Broadcom was able to deliver in a single chip with the “Trident” ASICs that were largely adopted by hyperscalers and cloud builders adopting 10 Gb/sec Ethernet in their top-of-rack switches many years ago that got that speed of Ethernet ramping.
Kucharewski says that the Tomahawk-II ASIC has double the forwarding scale of the original Tomahawk chip, but Broadcom is not divulging the size of forwarding tables or packet buffers in the chips. (Network ASIC makers are very leary of even giving out pictures of their chips so competitors can’t sort it all out.) The port-to-port hops on the Tomahawk-II are about the same at 400 nanoseconds. The new ASIC supports 64 ports running at 100 Gb/sec or 128 ports running at either 40 Gb/sec or 50 Gb/sec with splitter cables, all within a 1U form factor.
By cramming more ports into a device, the net effect is that customers building large networks are going to be able to save a lot of dough on switches and optical links to hook switches to each other in leaf-spine networks and to server racks. Kucharewski provides the following example to illustrate how this works. To hook 2,000 racks together using 100 Gb/sec ports to create a Clos fabric (as all hyperscalers use), it takes a maximum of six hops across two tiers of leaf switches and one tier of spine (or aggregation) switches based on 32-port devices to reach from any one server across the network to any other server. (This is important since east-west traffic across racks dominates these applications in the hyperscale world.) By switching to 64-port switches, the Clos network is knocked back to two tiers (one spine layer and one leaf layer), with the same 2,000 racks can be configured using 33 percent fewer optical links and have 40 percent lower network power and 40 percent fewer switches because it only takes a maximum of four hops to make it from one machine to any other in the cluster. The new ASIC also has much-improved dynamic flow distribution, says Kucharewski, which provides better network load balancing, allowing companies to run their networks a bit harder for the bandwidth.
The one thing that Kucharewski did not confirm (and really could not) is the expected price of a 100 Gb/sec port with the Tomahawk-II switch. We suspect that the price has to come down some per port – nothing huge, but enough to make the hyperscalers happy – and that all of the economic benefits will come from eliminating leaf tiers in the fabric. Broadcom is going to sell fewer ASICs for any given number of servers, so it has to make it up by allowing hyperscalers, cloud builders, telcos, and large enterprises to build larger clusters and hope they do.
The Tomahawk-II chip is sampling now from Broadcom, and as far as it knows, it is the first 64-port ASIC for 100 Gb/sec switches. Broadcom does not set the launch schedules for devices using its chips, and is not about to pre-announce products for its customers, but generally speaking, it takes about a year for switch makers to get products into the field after the sampling date. So we can expect updated 100 Gb/sec switches based on Tomahawk-II sometime in the fall of 2017. And we can expect for Mellanox, Cavium, and Cisco to react with their own updated 25G Ethernet ASICs with higher density, too.
Perhaps more importantly, with 200 Gb/sec InfiniBand around the corner next year and Broadcom on a two-year or so cadence for Ethernet ASICs, it is reasonable to assume that Broadcom and its peers are working to get 200 Gb/sec Ethernet chips ready for sampling by the end of 2018 or so and into products about a year later in the fall of 2019.




Please correct me if i am wrong, i thought the buffer size of Tomahawk is 16MB, not 85MB.
I know a part number of BCM56968, but with no spec.
Answering Donnie, Arista is now listed a 7060CX2-32S that has more than 16 MB but is in other respects the same as a Tomahawk. Presumably, if the switch has more buffers, it’s part number should be different. But I can’t find that.