

Apparently, it’s Rivalry Week in the compute section of the datacenter here at The Next Platform. There are a slew of vendors ramping up their processors and their ecosystems to do battle for 2018 budget dollars, and many of them are talking up the performance and bang for the buck of their architectures.
We have just discussed the “Vulcan” variant of the ThunderX2 processor from Cavium and how that company thinks it ranks against the new “Skylake” Xeon SP processors from Intel, which made their debut in July. AMD was talking up its Epyc processors at the recent SC17 supercomputing conference, which we will discuss in a follow-on story shortly, and Intel is, perhaps not coincidentally, also talking about how it thinks the Epyc processors stack up against its Xeons.
Intel looked at the publicly available benchmarks as a starting point, and then it actually got its hands on a two-socket Epyc system from Supermicro and then put it through the paces on a bunch of tests while at the same time testing three different configurations of a Xeon SP system to reckon against that Epyc box. We are, like you, understandably skeptical of any vendor tests performed on a rival’s architecture, but in the absence of independent, third party performance information we figure that all data we can assemble on behalf of readers is a good thing. You just half to remember to bring the salt shaker.
At the point where Intel had run its tests and had brought the public and private benchmark results together, which was a week ago, Intel had over 110 benchmark tests run where it had come out in top and AMD had only run four benchmarks publicly – the SPEC 2006 and 2016 integer and floating point tests – as well as two other benchmark tests with Linux kernel compilation and seismic reservoir analysis that we have reported on in the past as AMD was ramping up the first generation “Naples” Epyc processor to its June launch. The combination of having enough compute, with 32 cores on a Naples die, and lots of memory and I/O bandwidth (particularly on single-socket machines) is what, according to AMD, makes the Epyc chip competitive with prior and current Xeons.
The Intel benchmarks don’t precisely discount this assessment, and even Dave Hill, who heads up Data Center Group product marketing at Intel with a focus on servers, concedes that AMD Epycs lead on some of the benchmarks that Intel has run in its own labs.
“What we are seeing at a high level is that we are leading on the majority of the workloads, but AMD does lead on some memory bound workloads,” Hill tells The Next Platform. “As far as the key thing of performance per core, a lot of cloud workloads have grown up around the single-threaded performance of Xeon in the past ten years, and that is one of our key advantages. There is always a single-threaded bottleneck in some workload somewhere.”
Just for reference, here is the survey of published benchmarks that Intel rounded up on the Xeon SP and Epyc 7000 processors:
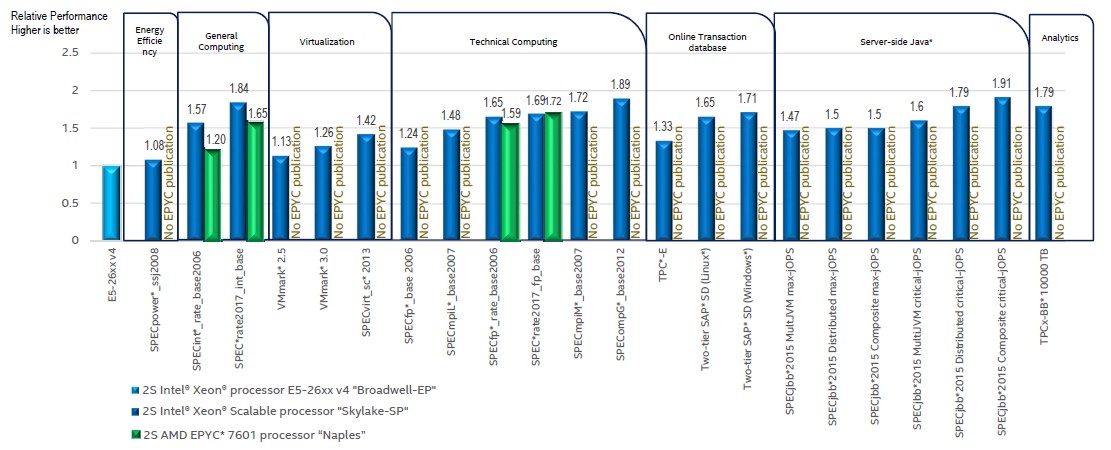
In the table above the relative performance of the Skylake and Naples processors are reckoned against a baseline “Broadwell” Xeon E5 v4 processor. In general on these tests, Intel is pitting a two-socket machine using the 2.2 GHz, 32-core AMD Epyc 7601 processor against the 2.4 GHz, 22-core Broadwell Xeon E5-2699A v4 processor and the 2.5 GHz, 28-core Xeon SP-8180M, a Platinum class chip in the new Xeon classification that also has the expanded memory that reaches to 1.5 TB per socket instead of half that for the regular Xeon SPs. The Epyc chip does a maximum of 2 TB per socket, regardless of model. In some cases, Intel is comparing across systems with similar prices, given that the top bin Xeon SP-8180M is not an inexpensive part with a list price of $13,011 a pop, and in that case is using the Xeon SP-8160, which has 24 cores running at a much slower 2.1 GHz. For HPC-style workloads, the comparisons are between the top bin Epyc 7601 part and a 2.4 GHz, 20-core Xeon SP-6148, which doesn’t have the Skylake memory tax on it. (See our coverage on the premium pricing Intel has for features in the Skylake/Purley platform at this link.) While AMD has been for the better part of a year talking up the advantage of pitting a single-socket Epyc 7000 system against a two-socket Xeon box using a middle bin SKU as is common among enterprises and HPC shops, Hill says that Intel has not done any testing yet to see how single-socket Skylakes might stack up to single-socket Epycs. (We suspect that this comparison would lean more in the favor of the Epycs on certain workloads, particularly where memory and I/O bandwidth mattered and workloads were NUMA aware.
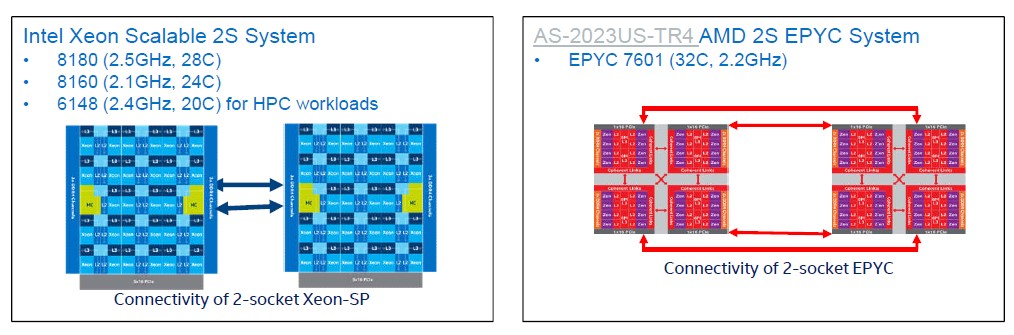
Here is what the systems under test looked like conceptually:
The Epyc 7601 system was loaded up with the Linux 4.10 kernel, which is the first one to support the Epyc processors, and on the commercial workloads the tests on both Xeon and Epyc machines generally run Canonical’s Ubuntu Server 17.04 for commercial workloads and CentOS 7.3.1611 for HPC workloads.
Recall from the architecture discussion on the Xeon SP chips that the cores and caches on the die are linked by a 2D mesh, and that in two-socket setups two Ultra Path Interconnect (UPI) links are used to lash the Xeons tightly together. There are three different variants of the Skylakes – the XCC variant with 28 cores and a 6×6 mesh, the HCC variant with 18 cores in a 5×4 matrix, and the LCC variant with 10 cores in a 3×4 mesh. The mesh runs at the same speed as L3 cache and varies from 1.8 GHz to 2.4 GHz, depending on what all of the elements on the die are doing.
With the AMD Epyc chips, there are four chiplets on the die linked by the Infinity Fabric that AMD invented (or rather re-invented and enhanced) and then a bunch of PCI-Express lanes that are used to link multiple processors together on an extended Infinity Fabric. We showed all of the feeds and speeds on this nested fabric in our coverage of the launch of the Epyc chips back in June. AMD contended back then that there was plenty of bandwidth between the chiplets and across the sockets for balanced performance, but we said that we wanted to know what the latencies were across the chiplets and sockets to get a sense of how workloads would performance if they were NUMA aware or not NUMA aware. (Those applications that did not know how to pin compute near memory would suffer.) Intel obliged and ran some tests on both Xeon SP and Epyc systems to shed some light on the issue. Take a look:
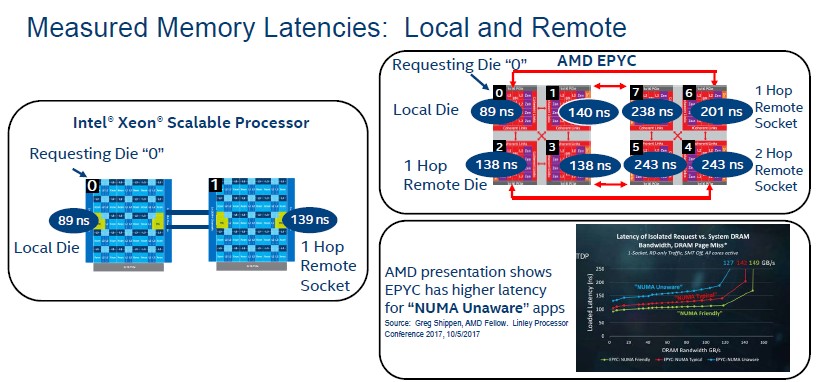
In the above chart, Intel is saying that it takes 89 nanoseconds to go from Core 0 on Die 0 on the left hand processor to any other core on Die 0; technically, there has to be some latency between the furthest core on the mesh, but apparently this is negligible. The big latency is jumping across the UPI links to the second socket, and it takes 139 nanoseconds to go out to Core 1 on Die 1 from Core 0 on Die 0, making the UPI hop about 50 nanoseconds. In the Epyc chip, as gauged by Intel’s Memory Latency Checker v3.4 software, the latencies range from 89 nanoseconds within a chiplet and anywhere from 138 nanoseconds to 140 nanoseconds within a socket to 201 nanoseconds to 243 nanoseconds jumping across the Infinity Fabric to the cores on the second socket.
Some applications will be affected by this difference in latency, some will not. Most HPC codes, for instance, are highly NUMA aware and will be least affected by the latencies in both architectures, according to Hill, but commercial applications written in Java, PHP, or .NET tend to not be NUMA aware and could be adversely impacted. Server virtualization hypervisors are not generally NUMA aware, either, so these latencies will matter if virtual machines span multiple chiplets and sockets but will not if they are sized to the core as is often the case. Basically, it depends. The point is to be aware of the issue.
Performance per core, as Hill said, is a big deal for certain kinds of workloads, so here is how SPEC 2006 integer tests rank on a per-core basis with the Epyc 7601 as the baseline and the Xeon SP 8160M and 8180M parts against them:
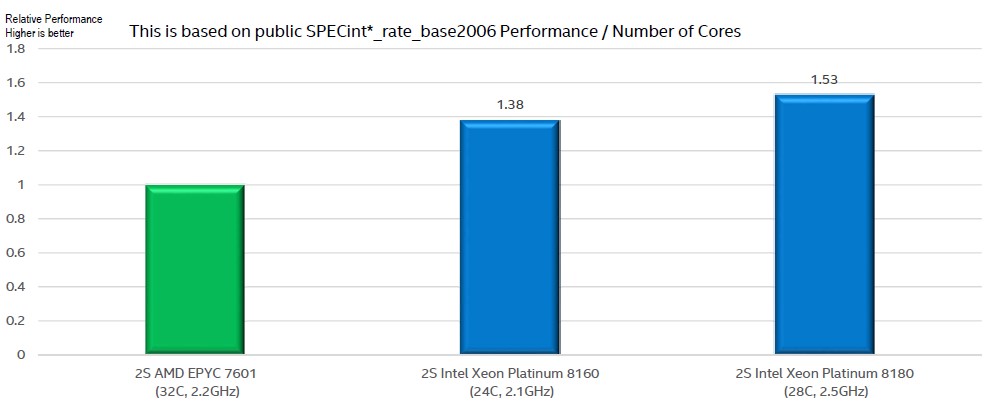
While performance per core is important, it comes down to a design choice. AMD has more cores with quite a bit lower SPEC integer throughput each, but the aggregate integer throughput on that Xeon SP-8160M part is only 3.5 percent higher, but it costs $7,704 for the Intel chip and only $4,200 for the AMD chip. And while that top bin Xeon SP-8180M has 58 percent more performance than the Epyc 7601 on a per core basis, it is 33.9 percent more SPEC integer throughput but for a chip that has a list price of $13,011. To be fair, on a configured system, where memory, disk, flash, and network costs add up, this difference shrinks. But it is not negligible.
Now, on to the benchmarks that Intel ran on single-node systems. These measurements are all relative to the Epyc 7601 system under test, and in this case Intel is running the benchmarks on two machines – one with Xeon SP-6148 Gold processors and the other with Xeon SP-8160M Platinum processors. Take a look:
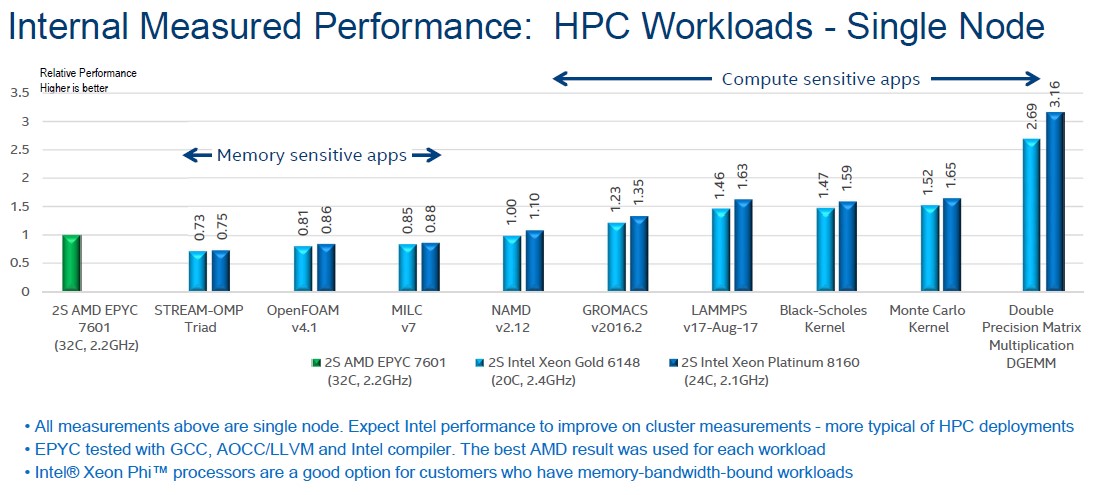
Intel used its own compilers on its own processors, and used its compilers, the GNU open source compilers, and the Open64 LLVM compiler on the Epyc chips – and then took the best result for the AMD chip on each test. This seems fair, but we suspect that AMD’s gurus could get more performance out of its own Epyc chips. (To which, we encourage AMD: Prove it.) As Hill suggested from the very beginning of our conversation, the Epycs do well on memory sensitive workloads like the STREAM memory bandwidth test, the OpenFOAM computational fluid dynamics test, and the MILC quantum chromodynamics test. On the NAMD molecular dynamics test, it is pretty much a dead heat, and then with the GROMACS molecular dynamics package, Intel Skylakes start pulling ahead of AMD Naples. With the LAMMPS molecular simulator the gap gets larger – around 50 percent more oomph for the Xeon node – and with the Black-Scholes and Monte Carlo algorithms commonly used in financial services HPC-style distributed pricing applications, it is about as wide. For raw double precision matrix math, the gap is very wide due to the AXV-512 vector units on the Skylake cores, but that is to be expected.
What immediately jumps out to us in this chart is the fact that the Xeon SP-6148 Gold chip, which only costs $3,072 at list price and which has 20 cores running at 2.4 GHz, does basically the same work as the Xeon SP-8160M Platinum processor, which costs more than twice as much at $7,704 at list price. That Skylake 6148 part is going to yield a lot better bang for the buck than the Epyc 7601, which costs $4,200 at list price. Given this, it is hard to believe the Platinum parts will be bought for anything but machines that need extreme memory capacity or lots of UPI links for NUMA expandability. This is a very small portion of the market, even if it is an important one that AMD has not addressed – and will very likely never do so.
Here is what the situation looks like on enterprise and cloud workloads:
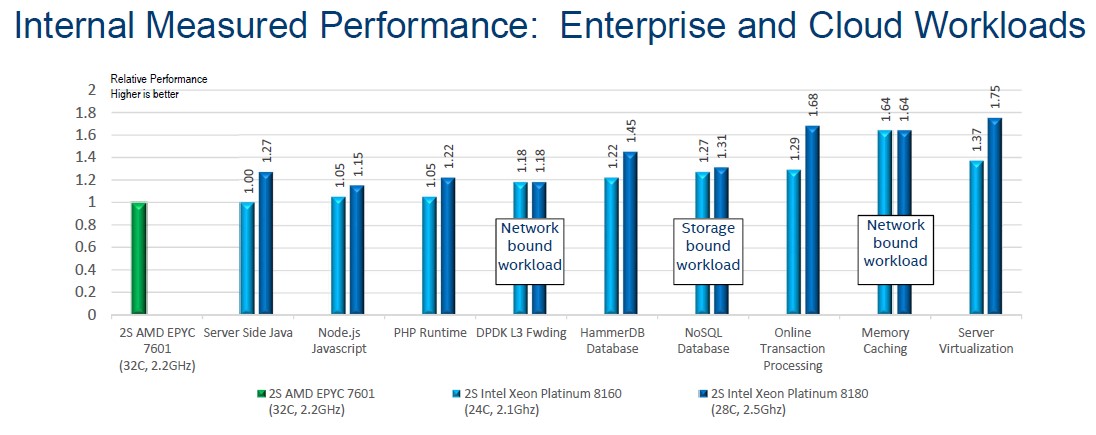
Hill said that unless otherwise marked, these applications were compute bound. On these workloads, Intel pulled out the big guns in the Platinum SKUs, the 24-core 8160M and the 28-core 8180M, to push the performance envelope. We would have loved to see what the 24-core 6148 Gold chip did on the same workloads. But in any event, the Skylake 8160M chip has parity to a slight advantage on Java, PHP, and Node.js applications, and a slightly higher advantage when it comes to network bound applications like network function virtualization as expressed by Intel’s DPDK L3 forwarding test or database workloads like HammerDB and NoSQL (which is Cassandra, not MongoDB). Transaction processing is SAP ERP code, memory caching is Memcached, and server virtualization is the VMmark test.
The one thing that Intel observed, and Hill did not have an explanation for, was performance variation on certain tests. In a run of ten tests on the HammerDB and Memcached benchmarks, Intel’s variation in performance was within 2 percent across those runs, but on the AMD Epyc systems, the variation was up to 64 percent on the Memcached test and up to 22 percent on the HammerDB test. This is obviously not an acceptable level of variation, but it is probably just a matter of tuning up the software for the hardware, which Intel has obviously done, to make it more NUMA aware and to hide some of those latencies across the chiplets and sockets. It probably has a lot to do with the initial configuration of data when the system starts, we suspect, and Intel didn’t have a better explanation. Perhaps AMD does.

TSMC Will Have An AI Business Bigger Than All Of Intel Foundry
Everyone is in a big hurry to get the latest and greatest GPU accelerators to build generative AI platforms. Those who can’t get GPUs, or have custom devices that are better suited to their workloads than GPUs, deploy other kinds of accelerators. The companies designing these AI compute engines have …
Energy Giant Eni Boosts Its HPC Oomph By An Order Of Magnitude
The big oil and gas companies of the world were among the earliest and most enthusiastic users of advanced machinery to do HPC simulation and modeling. The reason for these decades of experimentation and investment was simple: If you can figure out where the oil and gas is – and …
Intel Networking: Not Just A Bag Of Parts
What is the hardest job at Intel, excepting whoever is in charge of the development of chip etching processes and the foundries that implement it? We think it is running its disparate networking business. The competition is tough, and getting tougher with both incumbent and upstart players taking on Intel …
This is a very interesting but biased article. Everybody knows that benchmark selection and optimization is key. The study does not use a wide set of bechmarks and does not tune them either. The conclusion that a proc is slower than another can not be made unless the entire stack and optimizations are the same. This is not the case in this study.
AMD will be releasing EPYC2 chips with more thsn double the number of cores, faster memory support, higher frequencies, etc. at less than half Intel’s price..
Intel is paying AMD huge money for AMDs Vega integrated GPUs, which can result potentially in more than 200 million Vega iGPUs per year, since Intel sold 100 millin igpus in one quarter only in 2016..
Intel having almost 100% of the server market because AMD was designing its new architectures fir 5 years means Intel will barely have around 50% of the market share..more because AMDs Vega gpus wipe out anything Intel has or will have since Intel doesn’t have any GPU patent portfolio and Raja will be working on the new PHI architecture since they are late in government contracts and Intel does not have the patent pirtfolio needed to catch up with AMD or Nvidia.. which is why Intels first GPU project Larrabee failed miserably and Intel had to kiss Nvidia feet to licence nvidia iGPU technology which is now obdolete..
It’s too bad that AMD has their Custom Armv8A running micro-arch. K12 , moved onto the back burner as I was hoping to see maybe a custom ARM Chip with SMT capabilities in the low power using server markets and that K12 core maybe finding its way into tablet form factor devices with maybe some Vega graphics. Sometime 2018 is K12 new announced date but that’s on some old AMD roadmaps with K12 missing on any of the newer AMD roadmaps. I still have hope that AMD will not pin its entire future on only the x86 ISA/IP and would have had to consuder its current Seattle ARM core clients that are currenty using the Opteron A1100 Seattle cores beased on a very narrow order superscalar ARM A57 refrence core design, they probably want an upgrade path in the future that is a little more performant.
K12 is supposed to shared DNA under the bonnet with its Zen Project design that is engineered to run the x86 ISA, so a wider order superscalar K12 design similar to zen that can run the ARMv8A ISA and make use of SMT for better core execution resources utilization is just wjt the ARM server market would want.
A recently published detailed comparison of Broadwell and Zen architectures efficiency for the VASP code can be found here https://doi.org/10.1007/978-3-319-71255-0_35