

The oil and gas industry has been among the most aggressive in pursuing internet of things (IoT), cloud and big data technologies to collect, store, sort and analyze massive amounts of data in both the drilling and refining sectors to improve efficiencies and decision-making capabilities. Systems are increasingly becoming automated, and sensors are placed throughout processes to send back data on various the systems and software has been put in place to crunch the data to create useful information.
According to a group of researchers from Turkey, the oil and gas industry is well suited to embrace all the new technologies necessary for transforming the way it does business, creating a more digital environment and smart operations. At the same time, as the industry continues its transformation, it also faces all the key hurdles that challenge any sector looking to adopt and scale big data practices – the volume and variety of the data, the speed at which it’s collected and the need to verify its validity.
“Fortunately, the industry is ready to make this transformation, but it is looking for quick and effective ways to complete the task,” the researchers wrote in a recent study. “Due to mission–criticality of their processes, oil & gas businesses have already implanted thousands of sensors inside and around their physical systems. Raw sensor data continuously streams via DCS [distributed control systems] and SCADA [supervisory control and data acquisition] systems measuring temperature, pressure, flow rate, vibration, and depth etc. of drills, turbines, boilers, pumps, compressors, and injectors. A right quantity of data should be extracted, transformed and passed from data quality tests before loading (i.e. ETL process). To achieve success in these steps, one also needs to understand the nature of processes, devices and data to support real–time decision making.”
A recent effort from researchers from Turkish oil refinery Tuprs proposes a Lambda architecture that is designed to help the oil and gas industry unify and analyze the data coming in from all the sensors and other systems. In addition, the researchers tackle cloud integration challenges and highlight the use of sensor fault-detection and classification modules that are found in their proposed architecture.
“We focus on the veracity, i.e. correctness, property of oil & gas big data,” they wrote. “For this purpose, data has to be cleaned and reconciled before it can be used to train stream mining algorithms to generate real–time models and results.”
The oil and gas industry has adopted a range of open-source distributed frameworks in an effort to manage the storage, processing and analyzing of the data the companies are collecting. Those includes Apache Hadoop – which includes such modules as the Hadoop Distributed File System, MapReduce, HBase ad Hive – as well as Apache Spark, which the study’s authors said addresses some online processing problems inherent in Hadoop by using MapReduce in-memory. However, a problem is that Spark’s resilient distributed datasets (RDDs) can’t be changed over time. Apache Ignite addresses that issue, with mutable RDDs that can be used for distributed caching or as complements to Spark. However, along with these frameworks, there is a rash of other open-source data projects and no unified view for taking advantage of them. The problem is that the oil and gas industry has yet to come up with a comprehensive data architecture, the researchers said. In addition, there has been no good discussion about how to integrate them with private and public clouds.
This is where the researchers come in with their proposed Lambda architecture to give the industry a unified data and analytics architecture. Lambda architectures come with three primary components: a batch processing layer for managing offline data, a serving layer for indexing batch views for querying, and a speed layer for real-time processing. They are proposing alternative Lambda architectures in private and public clouds.
In their proposed Lambda architecture for private clouds, the authors leverage the Apache Kafka distributed streaming platform that brings in data streams from such sources as sensors, log files and IoT devices. The applications in the batch and stream layers use Kafka to pull in the data and process them in real time, while Spark Streaming divides live data streams and divides them into smaller batches. The architecture takes advantage of Apache Cassandra or other distributed data management systems that replicate it to several nodes, and distributed algorithms can access the replicas through MapReduce within the Spark API. Analytics like pattern recognition, fault detection and classification are done in the serving layer and the open-source MILib library – which can run atop Spark or Cassandra – is used for machine learning.
“The resulting real–time (online) models in speed layer and precomputed (offline) models in batch layer are merged for visualization and prediction purposes,” they wrote.
Each open-source technology that is used in the private cloud version has a comparable project for public clouds, enabling integration with public cloud services like Amazon Web Service. For example, AWS Kinesis is a cloud version of Kafka, while AWS EMR (Elastic MapReduce) is the data processing framework for MapReduce. AWS uses S3 (Simple Storage Service) in a fashion similar to Cassandra for storage batches and log files.
For fault detection – including finding random and gross errors – the group used a number of statistical pattern recognition techniques, including Least Square Estimation (LSE), Auto-Regressive Moving Average (ARMA) and Kalman Filters (KF) to extract system properties and create models and tested them with real and synthetically-generated refinery data. The block diagram looks like this:
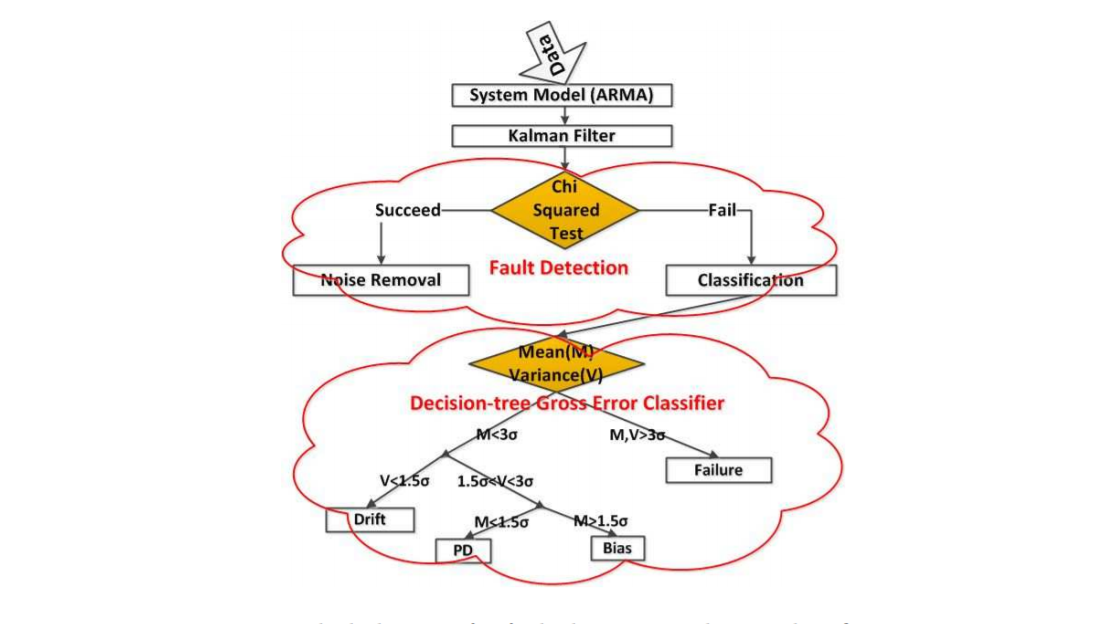
“Locating which sensor makes what type of error improves overall system reliability for the refinery and improves predictive maintenance performance,” the researchers wrote. “Modeling the time–varying refinery plants, the anomalies can be detected with statistical hypothesis tests (chi–squared test) for fault detection and noise removal. If the hypothesis fails, then a gross error is detected.”
They used a complex processing engine called ESPER to run the private cloud model and test data streams, using synthetically-generated data to train the model for validated real data. The researchers would not give details about the accuracy of error detection, but said that the model was able to accurately detect gross errors in both the synthetic and real data streams and classify them correctly. What they developed and the results of their tests lay the foundation for future research into other stream-mining machine- and deep-learning algorithms and the development of refinery-as-a-service capabilities.

Be the first to comment