

One of the frustrating facts about peddling any new technology is that the early adopters that discover a strategic advantage in that technology want to keep that secret all to themselves. Word of mouth and real-world use cases are big factors in the adoption of any new technology, and anything that hampers this actually causes the adoption to move slower than it otherwise might.
But eventually, despite all of the secrecy, there comes a time when the critical mass is reached and adoption proceeds apace. We have been waiting for that moment for a long time now for 64-bit ARM processors, and while many have written this sentence before, next year could be the year of the ARM server based on the ramping of existing ARM chips in servers and storage happening this year.
Networking chip maker Applied Micro started down the road of ARM server chip development back in 2009, when the global economy was suffering from the Great Recession and IT spending was taking a dive. Had the ARM collective caught the server bug a few years earlier and delivered a 64-bit server chip at that time that was capable of supporting server virtualization, IT history might have been radically different. But ARM was only starting to move down the server path and could not take advantage of the strong impetus to change that a recession brings, and as it turns out, Intel’s “Nehalem” Xeon platform and VMware’s ESXi hypervisor were the big beneficiaries of the Great Recession.
Should another recession hit in 2017 or 2018, then it could be the ARM collective that benefits this time around, particularly if the ARM server chips and the software running atop them mature as expected. Hopefully, it won’t take another global recession to bring some diversity to compute for serving and storage.
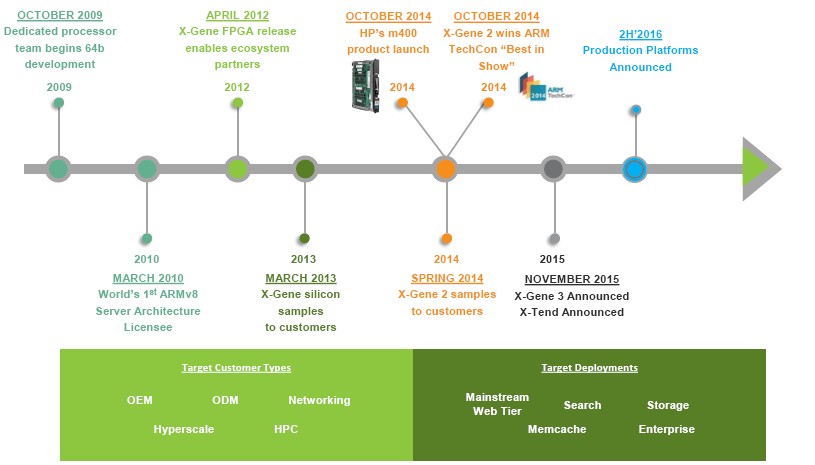
From the looks of things at Applied Micro, the uptake of its X-Gene processors for server and storage workloads is gathering some steam, and with next year’s “Skylark” X-Gene 3 chip, we could see broader adoption of the X-Gene family. We told you about the X-Gene 3 chips back in November last year, when they were unveiled, and Applied Micro reached out to The Next Platform to give us an update on the Skylark chip and its X-Tend NUMA clustering as well as to talk about some design wins it has had with the current X-Gene 1 and X-Gene 2 chips.
“It takes a long time for the market to adopt a new technology,” concedes Kumar Sankaran, who is associate vice president of software and platform engineering at Applied Micro. “To get a value proposition and TCO savings over X86 platforms that companies use today, it takes a good amount of time for that to happen. In 2016, we are seeing things starting to ramp.”

This includes a design win that has Hewlett Packard Enterprise, which is putting an X-Gene 1 processor inside of its StoreVirtual 3200 disk arrays, which are kicker devices to its existing Xeon-based Store Virtual 4330 appliances. These appliances are not particularly useful for large scale deployments, but anything that cranks up the volume on X-Gene chips makes the X-Gene family more credible as a processor and makes Applied Micro the money it needs to continue to invest in the product. Applied Micro is also showing off its “Mudan” scale-out object storage platform, which it developed in conjunction with Red Hat, and another system that was designed to host Redis key/value store and Memcached caching software that is actually in production at a large (unnamed) enterprise. Finally, Applied Micro has developed its own “SmartNIC” that can be used as a host bus adapter with integrated caching for storage, or a network adapter with embedded encryption and decryption or possibly other kinds of functions running on an X-Gene processor. This SmartNIC device is actually not a reference platform that someone else is putting together, but a product that Applied Micro is making and selling itself.
The StoreVirtual win could be a significant boost to Applied Micro’s X-Gene shipments – how much is hard to say. The important thing is that it is a concrete example of a major IT supplier putting a 64-bit ARM server chip into a product that is aimed at millions of customers. The StoreVirtual 4330 appliance has two nodes in a 2U form factor, with each node using a Xeon E5-2600 processor and delivering about 60,000 I/O operations per second (IOPS) across mirrored 7.2 TB of disk storage. With dual controllers, the StoreVirtual 4330 costs $33,000. The newer StoreVirtual 3200 is a two-node machine as well, but the machines are not clustered for redundancy but are run in active-active mode delivering a full 14.4 TB of capacity in a 2U form factor. Both machines run the LeftHand (now called StoreVirtual) storage operating system, which provides snapshots, thin provisioning, and replication services for the storage – features that are not common in devices aimed at SMBs, and certainly not at the $6,000 to $14,000 price tag that HPE is targeting for the StoreVirtual 3200. The adoption of the X-Gene 1 chip is instrumental in bringing the price of a fully loaded array down to $14,000, and that is because RAID 5 and RAID 6 disk controller functionality and 10 Gb/sec Ethernet links are built into the X-Gene 1 system on chip and don’t have to be added to the system.
We think Intel could probably build a StoreVirtual 3200 using the Xeon-D system on a chip it created for Facebook microservers as well as for networking devices and storage arrays. But again, the important thing is that HPE did not do that.
The Mudan object storage platform was rolled out by Red Hat and Applied Micro back at the Red Hat Summit in June, and it is being made by Mitac, an original design manufacturer (ODM) based in Taiwan that owns the Tyan motherboard business. Interestingly, Mitac also sells a microserver using a sled design called Datun, which packs eight X-Gene 1 or X-Gene 2 processors onto a 1U sled, which allows for 384 of the X-Gene chips and up to 3,072 cores to be put into a non-standard 48U rack. To our eye, it looks like Mitac is using the same Datun platform by replacing some of the compute with disk and flash storage. The Mudan sled is based on the X-Gene 1 chip and puts a dozen 3.5-inch disk drives on each sled plus two SSDs for caching the disks and booting the operating system for the X-Gene 1 processors. Without naming customers, Sankaran says that a number of hyperscalers and financial services companies have deployed the Mudan platform for cold storage. One of those financial services companies is based in the US is all that Sankaran can say.
On the data store and caching front, Applied Micro is showing off a server design aimed at Redis key/value store and Memcached caching workloads, and pitting it against a single socket implementation of Intel’s “Haswell” Xeon E5-2620 v3 server. The Applied Micro node in this Redis/Memcached system is based on an eight-core X-Gene 2 processor running at 2.4 GHz with 64 GB of memory and two 480 GB SSDs from Intel. The 1U chassis has two of these nodes with four disk drives each, all running the CentOS 7.2 clone of Red Hat Enterprise Linux. Here is how these two systems stack up:

While Sankaran did not provide list prices for the two Redis/Memcached systems, he did provide relative performance, processor wattage, and costs of the two systems, and as you can see, Applied Micro says it can deliver the same performance at the board level with 60 percent lower power at the CPU level and at 40 percent lower cost. The Xeon E5-2620 v3 costs $417 each when bought in 1,000-unit trays from Intel, and that means the X-Gene 2 costs around $250 each. While the relative pricing on the processors is interesting, what really matters is how the price of the nodes stack up against each other.
This particular Redis/Memcached system is actually deployed at a Tier One cloud service provider, with the system comprising a few thousand nodes. This is real, and it is not a small cluster by any stretch of the imagination. (At 84 nodes in a rack, that is at least 25 racks for this cluster and perhaps more. A capability-class supercomputer is around 200 racks, just for reference.) This is a real benchmark from a real customer, and they are seeing a 30 percent to 35 percent TCO advantage at the rack level including equipment, power, cooling, and other costs.
That leaves the final design win, which is not really a design win at all since it is Applied Micro using its own processor in its own SmartNIC server card. What it is, however, is Applied Micro getting into the server adapter business in its own right when this card is available sometime in the first half of 2017.
The multi-function accelerator card is based on an eight-core X-Gene 2 running at 2.4 GHz, and it has up to 32 GB of memory for its two SODIMM slots, two 10 Gb/sec ports, and six SATA ports. Customers can dial the watts of the card to between 25 watts and 45 watts, depending on the number of cores activated and the clock speeds they set. The card uses a standard open source Linux driver with security acceleration libraries embedded in it. Here is how the performance stacks up when it is used as a SmartNIC with encryption acceleration:
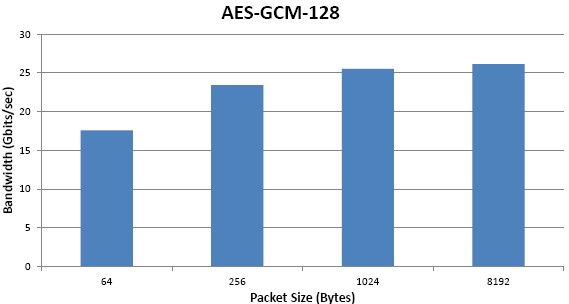
This SmartNIC will plug into any server, including Xeon machines, ironically. The target price for this device is somewhere between $900 and $1,100, says Sankaran.
The Update On X-Gene 3
While the eight-core “Storm” X-Gene 1 and “Shadowcat” X-Gene 2 processors are interesting for relatively lightweight workloads, the X-Gene 3 chip, as we have pointed out, will be aimed at heavier duty jobs in the datacenter made possible by the much brawnier design of the SoC and the much larger number of cores on the device.
The Skylark X-Gene 3 is set to sample by March 2017, which is the end of Applied Micro’s fiscal year and just in time for the Open Compute Summit next year. Production shipments through ODM and OEM customers are expected to follow about a year later, according to Sankaran.
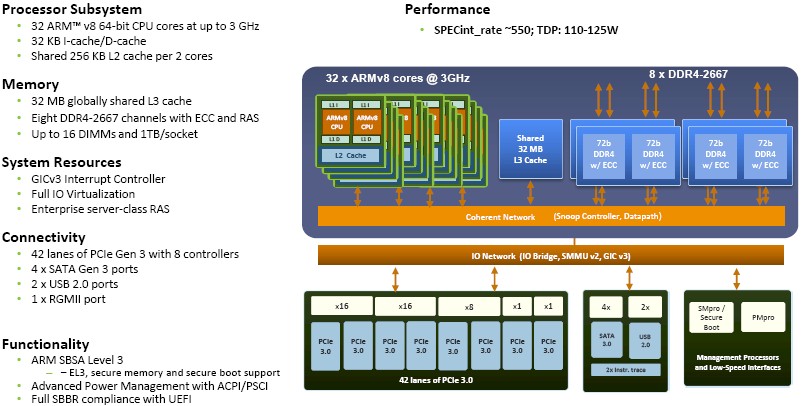
Last fall, we went over the X-Gene roadmap in detail and how the X-Gene 3 fit in, so we are not going to repeat all of that here. The X-Gene 3 is making a big jump to 16 nanometer FinFET processes from Taiwan Semiconductor Manufacturing Corp, and that is allowing for the core count to be pumped up to 32 on the device. The news is that with early test chips back, Applied Micro feels confident enough to provide an estimated integer performance based on the SPECint_rate_2006 CPU test, and that number is around 550 as you can see in the chart. Applied Micro is also now saying that this chip will run at between 110 watts and 125 watts – lower than a typical Xeon does today, but not incredibly lower.
By the way, that SPEC integer rating on a 32-core X-Gene 3 running at 3 GHz is about six times higher than for the X-Gene 2 with eight cores running at 2.4 GHz. Given the core counts and the clock speeds, you would expect about 5X more performance, so that extra performance is coming from tweaks to the core design and other factors like more memory channels and bigger caches. Applied Micro is not providing SPECfp_rate_2006 floating point performance estimates for the X-Gene 3 at this time, but Sankaran says that it should be 6X higher than X-Gene 2.
Here’s the thing: this X-Gene 3 chip should be able to stand toe-to-toe with Intel’s “Skylake” Xeon E5 v5 processors, which will have 28 cores, and the future Power9 from IBM, which will have 24 cores and probably run at slightly lower clock speeds.

Those current and future Intel Xeon and IBM Power chips implement NUMA functionality in their transistors, but for its first pass, Applied Micro is gluing together systems in NUMA setups over the PCI-Express bus. It can do glueless NUMA on two-sockets and for four sockets (available next year) and eight-sockets (on the roadmap) it requires a PCI-Express switch. The X-Tend setup imposes a 10 percent to 20 percent overhead on the NUMA cluster, getting higher as the socket count rises as it does on all NUMA machines, and if it works, it will allow Applied Micro’s partners to build systems with 2 TB, 4 TB, and 8 TB memory footprints.
There are a lot of other possibilities, of course. Sankaran says that Applied Micro is in discussions with customers to possibly add NVLink ports, important for HPC workloads where GPUs accelerate the compute, to future X-Gene chips. It all depends on the case that customers make and the volume of sales. (We would say that any advantage over Intel is a good one, as IBM clearly believes.) Applied Micro is also planning to support the CCIX standard that will come out of the consortium, headed up by Xilinx, that seeks to provide a coherent means of adding coherence between various processing elements. This CCIX support will come in a future version of the X-Gene chip. Applied Micro will also be adding HBM2 memory in a future X-Gene chip. Our guess is that the X-Gene 4 will probably look a bit like Intel’s original plan with the “Knights Landing” many core processor in that it will support close memory (in this case HBM2) and far memory (in this case DDR4 or DDR5) and let customers operating in modes that include one, the other, or both.

550 is a decent Spec2006 int performance, am Intel Xeon E5-2680 v4 gets (14core, 2.4 GHz) about 620 burning 125W so it is in a similar ballpark but not mind blowing.
Are those ARMv8 cores that probably will be running the ARMv8A ISA custom cores or are they of the Arm Holdings reference design? I wish someone would go into MORE Detail on any specifications of the custom designed micro-architectures that are engineered to run the ARMv8A ISA as they are quite different from the Bog Standard Arm Holdings Reference design cores.
What is with the makers of custom ARM cores and Why are they afraid to provide the same amount of information that both AMD and Intel provide for their x86 ISA running cores! What is so special about any custom micro-architectures that run the ARMv8A ISA. I’m waiting for information on AMD’s K12 custom ARM cores with K12’s design Team lead by non other than Jim Keller. I do hope that AMD will be more forthcoming on its K12 core specifications, but really what is it about any of the custom ARM cores that rates such secrecy. Even IBM offers up Deep Dives into its Power8/Power9 CPU core designs! So what gives custom ARM core designers/makers! Why the lack of information on any of your custom CPU micro-architectures engineered to run the ARMv8A ISA. If the x86 CPU makers can provide good information, and even IBM can for its CPU cores, Then why can’t the custom ARMV8A ISA running Core micro-architecture makers do the same, what are you hiding!
Here is some of the Apple A7(cyclone) specifications(1), but there are no good specifications for the A8/A8X A9/A9X, or newer CPU cores!I’ll bet AMD does better with their K12’s CPU core specifications. But there needs to be some more investigative work done or the custom ARM cores are all going to be considered some form of magical black boxes with no relevant information provided about their CPU cores’ real makeup. It’s shameful the state of reporting on the custom ARM based micro-architectures really shameful!
(1)
CPU Codename—————-Cyclone,
ARM ISA———————ARMv8-A(32/64),
Issue Width—————–6 micro-ops,
Reorder Buffer Size———192 micro-ops,
Branch Mispredict Penalty—16 cycles (14 – 19),
Integer ALUs—————-4,
Load/Store Units————2,
Load Latency—————-4 Cycles,
Branch Units—————-2,
Indirect Branch Units——-1,
FP/NEON ALUs—————-3,
L1 Cache-–——————64KB I$ + 64KB D$,
L2 Cache——————–1MB,
L3 Cache——————–4MB,
This Cyclone information provided thanks to Anand Lal Shimpi’s fine reporting when he still was the owner of Anandtech! The good reporting is now gone so who will pick up the stick!
K12 is dead. BTW, it’s Zen that was led by Jim Keller.
Apple’s secrecy is easy to understand:
They’ve concluded that IP law is not a great way to protect their investment in R&D (even if you do eventually win your lawsuit after years, and multiple retrials, you still lose in the eyes of the public as the bully who is beating up some other company.) So trade secrets are a better solution.
Hence zero useful information about any technical details of the A# series. “Is value prediction a good idea for mobile chips?” Run your own damn simulations. “Does it make sense to use a hardware governor to swap between a fast and a slow core?” Wouldn’t you love to know. etc etc.
This likewise extends to sales info. How many mid-range vs high-end watches sell vs low end? How many people buy additional bands? How many people are buying the Series 2 vs Series 1? All useful info that Apple is using as a barrier to competition that (hopefully) works better than patent and copyright law.
Now, what about the other ARM vendors? Some of the information you seek is available in rough form in LLVM source code, if you bother to look through the details. (That’s where AnandTech got the A7 info, but after the A7, Apple keeps the specific LLVM machine model code in-house so it’s not part of the general LLVM source.) Some is occasionally released at Hot Chips.
More generally, I think the issue is a combination of
– not enough engineering resources to spend time on this (eg create the sort of detailed papers that IBM writes, or the optimization guides that Intel writes)
– no obvious upside to the company and possibly a downside (eg the same sorts of answers to the same sorts of questions I gave for Apple): it’s easier to know something about a good prefetch design for mobile if you can start with detailed info from one of your competitors…
The true competitor to Applied Micro’s X-Gene 2 with 8 cores is not Intel’s Xeon E5-2620 v3 but it is Intel’s Xeon D chips such as Xeon D-1541 with 8 cores also. Intel Xeon D-1541 performs a little better than single socket Intel Xeon E5-2620 v3. Since Intel’s Xeon D-1541 costs (39%) more than the Xeon E5-2620 v3, cost per performance is different. As shown in the marketing slides, the only avenue left for Applied Micro in this “microserver” segment is to compete with lower prices. But at around $250, there are also competition in the form of Intel Xeon E3-1230 v5 and a little higher at $294 there is Intel Xeon E3-1260L v5 which is 45W only. Competition is quite tough in this segment for non-x86 chips.
Regarding Applied Micro’s X-Gene 3 with 32 cores and SPECint_rate2006 of “550”, that’s almost double per core performance of Phytium’s Mars with 64 cores and SPECint_rate2006 of 570 (reference https://www.nextplatform.com/2016/09/01/details-emerge-chinas-64-core-arm-chip/ ). And per single core/thread, this is also better than Intel’s Xeon Phi 7250 (reference https://www.spec.org/cpu2006/results/res2016q2/cpu2006-20160613-41873.html ). However this “550” figure is estimated only (as in Phytium’s Mars case). Actual performance will only be known when the finished silicon is finally tested.
Applied Micro considering the process of innovative adaptation has pretty much done everything right determining where are the unique product opportunities into future.
Applied experiments considering categories of adoption is broader than any other ARM licensee I am aware in this space.
Unfortunately, Intel has pretty much laid the category of ARM V8 applied science to waste on v2, v3, v4 production weight.
The primary misconception to address in Mr. Morgan’s report concerns this price statement;
“The Xeon E5-2620 v3 costs $417 each when bought in 1,000-unit trays from Intel, and that means the X-Gene 2 costs around $250 each.” In reality, Intel pricing in the cloud space for
E5 2620 v3 is $271 and may currently by as low as $208.
2620 v3 broker market 1 piece mean is $400.
I piece range low $139, $325 to $375 mid range, $411+ on IDM specific system qualified which of course everyone knows is a is rip off.
What has to happen with these ARM v Intel Xeon reports is to address the added system functionality ARM parts provide for component price functionality v who ever are the competitive platform providers. And this is attempted in the HP storage server example.
When evaluating an ARM based solution what economies of functional integration are provided to offset the design production cost : price v Intel. In other words if you want to produce a similar Intel based solution what is the whole bill of materials difference v ARM; which would be less?
And then what of the performance and total cost of ownership?
Mike Bruzzone, Camp Marketing
Good for Applied Micro to find a buyer following the push and pull, since 2012, that is selling the enterprise.
PAM 4 push is relatively wide accepted then by the stakeholders.
I for one am ready, to join all those who continue to pursue stripping massive chucks of revenue off of Intel Corp. on the within 100 day purchase of AMCC Data Center Processing Group, by AMD,(?) Marvell(?), QCOM(?), TI (?). Alibaba (?), Baidu (?), Nvidia(?) nay, Oracle/Sun, Xilinx.
Some internation development consortium . . . who . . .
Intel?
Maybe Softbank will purchase Applied Micro compute / data center group on that very old licensee grip that ARM Holdings plc / ARM Inc. had a stated plan limiting by product segment; high, medium, low.
There’s nothing wrong legally, with that type of entry strategy, going up against Intel Cartel: high, medium and low.
Then somehting happen and ARM Holdings plc / ARM Inc. over licensed.
I am a stated witness to this for a very long time.
Mike Bruzzone, Camp Marketing
Mike Bruzzone, Camp Marketing