

With the International Supercomputing 2016 conference fast approaching, the HPC community is champing at the bit to share insights on the latest technologies and techniques to make simulation and modeling applications scale further and run faster.
The hot topic of conversation is often hardware at such conferences, but hardware is easy. Software is the hard part, and techniques for exploiting the compute throughput of an increasingly diverse collection of engines – from multicore CPUs to GPUs to DSPs and to FPGAs – evolve more slowly than hardware. And they do so by necessity.
The OpenACC group is getting out ahead of the conference to talk about the work it has been doing to make a consistent paradigm for parallel programming work across many different types of devices, and will be showing off the work it has done to make OpenACC available on IBM’s Power processors as well as one hybrid machines that combine the Power CPUs with Nvidia’s Tesla GPU accelerators.
The OpenACC standards body is also talking about new organizations that are joining the effort and hackathons and workshops that are helping supercomputing centers and industry users figure out how to better parallelize their codes to not only boost performance on clusters built from multicore processors but also machines that are accelerated by GPUs.
The addition of support for OpenACC directives in code that runs on the Power processor or the combination of Power CPUs and Tesla GPUs is an important step for the OpenPower collective, which includes IBM and Nvidia as well as networking ally Mellanox Technologies. These three are working together to build the “Summit” and “Sierra” supercomputers for the US Department of Energy in 2017 using the future Power9 processors from IBM and the future “Volta” GPUs in Tesla accelerators from Nvidia. Getting the Power9 chips, the Volta GPUs, and 200 Gb/sec HDR InfiniBand into the field before 2017 comes to a close is going to be a challenge for all three vendors, to be sure, but all of this nifty and expansive hardware is academic if the development tools can’t take existing codes developed by the many users of the systems at Oak Ridge National Laboratory, where Summit will land, and at Lawrence Livermore National Laboratory, where Sierra will run, and move them from X86 iron or hybrid X86-GPU machines to hybrid Power-GPU iron.
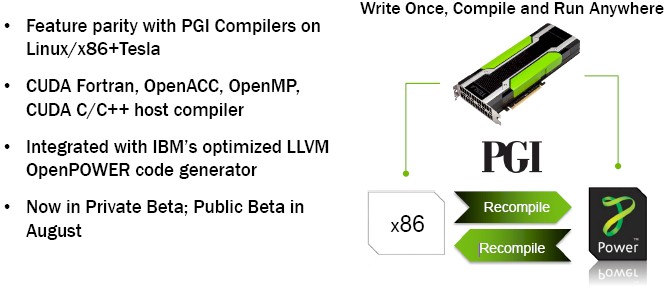
To that end, the OpenACC community, which is being driven by compiler maker The Portland Group, which Nvidia acquired three years ago and which it runs at arm’s length, as well as by Cray, Oak Ridge, and another 21 organizations, is announcing the first compiler stack that adheres to the OpenACC standard for parallelizing applications that can run on Power chips and Tesla GPUs, setting the stage for Summit and Sierra and, more importantly, other organization that will want to buy systems that are a chip of their blocks to run their own codes.
Michael Wolfe, technical chair for OpenACC and the technology lead at PGI, tells The Next Platform that the compilers have been in closed beta for the past couple of months and that an open beta for the tools will start in August. The version of the compilers and toolchain for Power and Power-Tesla combinations will have “feature parity” with the tools that PGI has delivered for X86 processors and Tesla GPU offload, including Fortran, C, and C++ compilers and support for CUDA Fortran and both OpenACC and OpenMP for parallelizing the host.
“The way that we have implemented this is we have a PGI front end and PGI optimization technologies with LLVM as a back-end code generator to do instruction selection and scheduling and register allocation,” Wolfe explains. This was a lot quicker and easier than developing its own code generators, as it did for X86 processors nearly two decades ago. “There are some issues with interfacing with LLVM, and frankly it does not understand Fortran very well, so there are some things we need to play around with. But it is good and we don’t have to deal with the details of the Power instruction set and this technology can be used to target other processors, like ARM in the future when we decide to go in that direction.”
The marketing pitch for the Power/Tesla toolchain from PGI is that programmers will be able to use the same command line and options and it will be “pretty much compile and run,” as Wolfe put it.
But Wolfe, and his peer Duncan Poole, president of OpenACC and partner alliances lead at Nvidia, can’t leave it at just that because they know that HPC shops will have to do better than compile and run as they move from X86 clusters to Power clusters. “The effort that you spend porting your code to an accelerator also pays off with a multicore host,” says Poole, but then he adds the caveat that “recompile and run is virtually dead now” and that HPC shops “have to refactor their codes.”
Wolfe and Poole have a sophisticated view on this, as you might imagine. To be more precise, recompile and run, as espoused by the tools that PGI delivers, will work, but programmers and the organizations that they work for should require more than that, just like hyperscalers, who are obsessed with efficiency and performance, do. Wolfe explains, in detail.
“You get into a meta-discussion about how much refactoring and code optimization you need to do when you go from one type of system to another,” says Wolfe. “There was a long period when with most parallel programs, we pretty much settled on MPI. You have your node program and you had your MPI communication and that could port reasonably well across a wide range of systems. MPI virtualized the network and the compilers virtualized the instruction set and that worked well for a length of time. But some people were leaving performance on the table, and a lot of applications essentially ignored the SIMD instruction set that was in the X86 and is now available in Power and ARM. They left that performance on the table because it was good enough and scale was always getting better next year and it never even entered their mind that maybe they could pick up another factor of two boost. But a factor of two means you can delay your upgrade by a year or two. That is the most damning thing, because SIMD or vector parallelism is just too damned easy. Ignoring that is irresponsible.”
Wolfe says that once organizations have put in SIMD or vector parallelism into their code, this can port pretty well across architectures, and it is just like porting using MPI as an abstraction layer. The problem is that with multicore processors, which have dozens of cores and many dozens of threads these days, organizations are using flat MPI to virtualize the compute and parallelize across those threads. This is fine until you hit some of the upper limits of MPI.
“MPI has a problem in that it doesn’t really scale when you get up into hundreds of thousands of ranks,” says Wolfe. “You have data that has to be replicated for each rank within the same node even if it is read-only. You have tables in the runtime where these ranks go to, and those tables are replicated with each rank even though it is read only data and it is not taking advantage of the shared memory of the node. Some people say that is an advantage, because you don’t have cache conflicts, for instance. But you do lose some behavior.”
Not to pick on anyone in particular, but just to illustrate with an example, Wolfe explained the evolution of the S3D turbulent combustion simulation code created at Sandia National Laboratories using Fortran and MPI. Several years ago, working with Cray, the S3D code was moved to a hybrid programming model that mixed MPI and OpenMP that allowed for the code to run twice as fast. Then, switching from OpenMP to OpenACC to parallelize the nodes boosted the performance by another factor of 3.5X.
“Some people would say S3D was running 7X faster, but it was only 3.5X faster than the code they should have already been running,” Wolfe adamantly proclaims. “The point is, you need to factor your code for the right style of parallelism. But once you have done that, the code is fungible. You can reuse it between X86 and OpenPower–they both have multicore, they both have coherence, they both have many nodes, and they are both going to have accelerators. So once you have identified and expressed your program to have the right kind of parallelism, that will move across a wide range of systems.”
Considering that Nvidia and PGI are big believers in OpenACC, it is not surprising that Wolfe picks this example, and we have discussed the co-opetition relationship between these two related but different methods of introducing parallelism in applications at length in the past.
As we look ahead to the future of capability-class supercomputers, the obvious question is how to make code portable across a machine like Summit, which will have multiple Power chips and some number of Tesla GPUs in each node – and a relatively small number of nodes at around 3,400 – and a machine like Aurora, which is going to have one “Knights Hill” with an unknown number of cores in over 50,000 nodes. At first blush, these would seem to be very different animals.
“I would claim that they are not,” Wolfe says. “The way we have abstracted the parallelism in a device, like a GPU, is more or less the same way we would abstract parallelism on a many-core chip like a Knights Landing or Knights Hill. You have got some sort of SIMD parallelism, and the CUDA folks will tell you it is not SIMD but SIMT, but whatever it is, you have to program it more or less like a SIMD engine to get performance. And it has got multiple cores – I am not talking CUDA cores here, but real compute engines [the SMX units] – and it has got a lot of multithreading. OpenPower has pretty much the same thing. It has got SIMD operations, even if they are much smaller. It has got multiple cores, and there are much fewer. The X86 architecture has got multithreading, and Knights Landing and Knights Hill have the same thing, and moving data from the system memory to the high bandwidth memory is similar. So from my perspective, there is a lot of correspondence between these two things, but you do need a lot of parallelism that can be mapped in different ways to the different targets.”
This, says Wolfe, is where it starts getting into religion. Five years ago, when OpenACC came out as a follow-on to the PGI accelerator model mixed with some work that Cray and Oak Ridge were doing with directives, the OpenACC founders had GPUs in mind, from both AMD and Nvidia, and they also were looking at ClearSpeed floating point accelerators and IBM Cell processors and Intel Larrabee coprocessors, too, and the directives were designed so they would map well to all of those targets. “We are not thinking about DSPs but we could have, and we were not thinking about FPGAs and we still aren’t, although there is some research in that area,” Wolfe adds.
The OpenACC committee meets every week, trying to hammer out issues big and small relating to parallelizing applications, and there are two big issues on the table right now, according to Wolfe.
The first has to do with systems with multiple devices, like the Xeon-Tesla and Power-Tesla hybrids mentioned above.
“If you have a system with two Haswell Xeons and eight dual-GPU Tesla K80s in each node, how do you manage multiple devices in a directives-based model on these devices in an OpenACC environment?” Wolfe asks rhetorically. “Do you get into data distribution like High Performance Fortran (HPF), which we all know was not all that successful? We don’t have any immediately obvious things to do with multiple devices. When we have true unified memory like we will have with Nvidia’s Pascal and Volta GPUs in particular, then maybe the data management can be done by the hardware in the system and the compute distribution will get easier when the hardware will get more complex. But right now, that’s a challenge and we are not sure what to do there.”
The other big area is memory management across the plethora of devices that might go into a cluster node in the future. “If you look at device memory and system memory in a hybrid, that is the same thing that you have on a Knights Landing chip,” says Wolfe. “How do we manage either data allocation to the right place or data movement so we optimize that movement do data is in the best place for the time when it is to be accessed? We have some ideas and that is the biggest item we are working on most actively right now.”
The other thing the OpenACC community is focused on is increasing the base of organizations that are using the programming toolchains that make use of this methodology of providing parallelism for applications. This includes formal support from university and government labs as well as from organizations that are participating in an increasing number of hackathons and workshops to gain experience from experts in OpenACC.
Brookhaven National Laboratory has joined up after participating in a hackathon at the University of Delaware and is working on adapting its GridQCD quantum chromodynamics applications for OpenACC. Sony Brook University, part of the State University of New York system and just down Route 495 from Brookhaven, has also joined up, and the University of Illinois at Urbana-Champaign has, too, and is doing similar code modifications on its molecular dynamics applications.
The workshops are less intense than the hackathons, but both are proliferating skills with OpenACC and, as Poole puts it, helps developers sort out which issues are ones with their code and ones that are just a matter of a lack of experience with OpenACC. It gives them the much needed “aha moment” to build confidence and tweak their codes to better parallelize them. The hackathons tend to run five days and have from five to ten teams of developers with between three and six members each, plus the OpenACC experts that volunteer their time. Pizza and coffee are supplied, of course, and anything that programmers learn about offloading code to GPU accelerators applies to multicore processors as well. These are not a place to start learning about parallel programming, and attendees are expected to show up with code that can be compiled for the target systems and work. The hackathons are really about optimizing performance, and OpenACC wants as much variety in the systems and applications as it can get to help the toolchain spread in the HPC community. The average speedup for the 36 teams that have attended hackathons in the past 14 months 79 percent, which is not too shabby. The Swiss National Supercomputing Center is hosting a hackathon between July 4 and 8, and Oak Ridge has one from October 17 through 21.
The number of applications that are seeing acceleration from OpenACC continues to grow, and this week the Nekton for Computational Electromagnetics (NekCEM) tool, which models physical systems using electromagnetics, photonics, electronics, quantum mechanics, has been accelerated by a factor of 2.5X on the Titan hybrid CPU-GPU supercomputer at Oak Ridge. The work was performed by Argonne National Laboratory, which has run NekCEM on its various BlueGene parallel systems and previous machines for decades. Argonne wants for NekCEM to be portable across architectures and not tweaked and tuned for a new system each time it changes architecture. (Argonne is shifting from IBM BlueGene to Intel Knights Landing systems with Aurora in 2018.) The NekCEM code was ported to OpenACC and run across 262,144 CPU cores for 6.9 billion grid points in the simulation, and then it was tested on 16,384 Tesla GPUs and ran 2.5X faster. Significantly, those GPUs took only 39 percent as much energy to do the same workload as the CPUs. The good news is that this parallelization work lays the foundation for the move of NekCEM to Aurora, which will cram lots of cores and nodes into a system and which will have local and remote memory, much as a CPU-GPU hybrid.

Strong-Armed Into HPC, Like It Or Not
If you are an HPC center in Europe, and particularly one that is funded by public funds, you are thinking about Arm-based CPUs in your supercomputers. And that is despite Arm Holdings being a British company and all of the issues with the United Kingdom and its Brexit separation from …

The $1 Billion And Higher Ante To Play The AI Game
If you want to get the attention of server makers and compute engine providers and especially if you are going to be building GPU-laden clusters with shiny new gear to drive AI training and possibly AI inference for large language models and recommendation engines, the first thing you need is …
Nvidia Hints At Upcoming AI-Focused Spectrum-4 Ethernet
It is no surprise at all that Nvidia’s datacenter business is making money hang over fist right now as generative AI makes machine learning a household word and is giving us something akin to a Dot Com Boom in the glass houses of the world. It is also no surprise …
When it comes to exploiting SIMD parallelism in a cross-platform/cross-architecture manner using vector-length-agnostic (VLA) techniques, there is a framework in development that integrates well with existing C/C++ code-bases while not requiring any extra build-steps or dependencies.
Here is a github page: https://github.com/VectorChief
UniSIMD – is a macro-assembler framework with an SPMD-driven vertical SIMD-ISA currently mapped to 4 major architectures (x86, ARM, MIPS, Power).
QuadRay- is the most prominent example of its use, a simple real-time ray-tracer, providing extra validation for the SIMD-abstraction-layer above.