

While GPUs are commonly used to accelerate massively parallel compute jobs that are behind simulations, media rendering, or machine learning algorithms, the next wave of growth could come from databases, thereby upsetting the balance of power in get another part of the datacenter infrastructure.
While in-memory databases like Spark, SAP HANA, Oracle 12c, and DB2 BLU running on X86, Power, or Sparc architectures are all the rage in some circles, sometimes the database management system is not so much memory bound as it is compute bound, and in these cases, a powerful parallel processor with a relatively modest amount of main memory can be used to chew through data a lot faster than a monolithic database running on a big NUMA machine or spread out across a cluster of servers. This is not theory, but practice at MapD, which has created a database that runs atop GPU accelerators and that is offering as much as 100X speedups on database workloads compared to running the same applications on X86 clusters.
As The Next Platform detailed last June, MapD founder Todd Mostak and a team of programmers was in the middle of gutting and completely rewriting the company’s eponymous database. Mostak had some experience, thanks to his PhD thesis, with the open source PostgreSQL database with the PostGIS geospatial processing system, and because of the frustration with these tools in processing and visualizing data, he hacked together the MapD prototype. After showing it around, Mostak secured $2 million in seed funding from Google Ventures and Nvidia to rework the product and move it closer to compliance with ANSI SQL 92 standards, and today the company has raised $10 million its first round of venture funding from Vanedge Capital. These funds will be used to build out the MapD product further and start pushing it to enterprise, cloud, and hyperscale customers.
The updated MapD database is coming to market just ahead of a revamped “Broadwell” Xeon E5 processor lineup from Intel and what we presume will be the unveiling of the next-generation “Pascal” GPUs from Nvidia, sporting high bandwidth memory and NVLink interconnects to make GPU computing all that more compelling.
Mostak could not talk about all of that shiny new iron headed our way this year, but he did give us some insight into who is using the MapD database engine on top of GPUs and what kind of performance results the company is seeing in early tests. More formal benchmark tests that pit the MapD software against in-memory databases, more traditional relational databases, and parallel databases used in data warehouses will be coming later this year.
Having a relational database that runs on a GPU is a fairly new concept, and there are a few alternatives out there like the SqreamDB database from Sqream Technologies, which bears some resemblance to the MapD product. But MapD is a little bit different in that it not only uses the GPU to parallelize SQL queries and run them lightning fast across thousands of cores, but it can turn around and use the GPU to render visualizations of the dataset in question. This is akin to running simulation workloads and rendering them on the same devices, which is only recently possible in the more traditional HPC world.
“We have gotten to the point where we feel like we have a robust tool,” Mostak tells The Next Platform. “There are still more features coming, and we have a pretty extensive roadmap, but we have some customer validation now and we can launch this to the world. Customers are seeing 20X to 50X speedups over a comparatively priced cluster. Most of our customers are using it with the MapD Immerse integrated visualization platform, which has evolved quite a bit in the past year. While we can target database-only use cases, the focus now is on the integrated end-to-end visual analytics because this is a great use case for complex queries that can run against large datasets in milliseconds.”
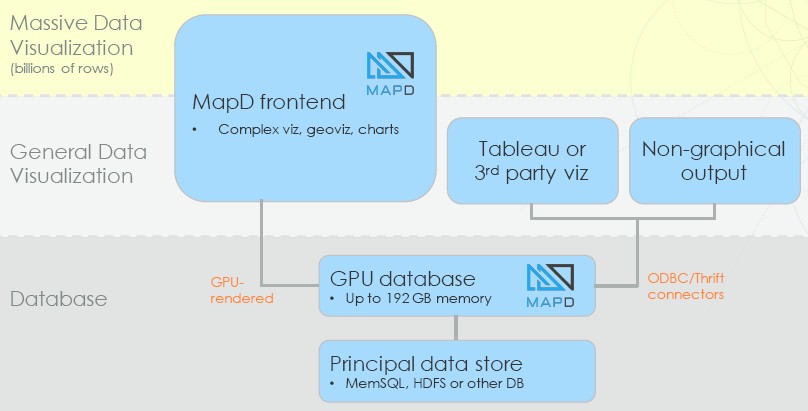
MapD is written in C++ and uses LLVM to compile SQL queries on the fly down to GPU code. The front-end of the database is written in Java and Apache Thrift (open sourced by Facebook some years ago) is used to glue the two halves of the database together.
For many in-memory databases or SQL layer add-ons for analytics platforms like Hadoop, it is not uncommon for queries to take tens of seconds to complete, and for many use cases, this cannot be considered interactive by any stretch of the imagination. Customers, says Mostak, want sub-second response time – and we would observe, just like they always have since computing moved from batch to online back in the late 1960s. Systems have been updated through the years to get that sub-second response time because that is how fast people can react to data. So of course we want that, and unless we are dealing with machine-to-machine interfaces, there is no need to move faster than that. (The GPU accelerated databases like MapD and SqreamDB can deliver fast enough response times to be used for such applications, mind you.) The twist these days is that real-time decision making based on streaming data requires fast responses to queries and visualization because once the stream have moved on to persistent storage, it is a pain in the neck to go query it in batch mode or with an SQL overlay. You want to write applications that can sift through data for anomalies and interesting bits as it is coming in and proactively do something or prevent something from going wrong rather than grab historical data to figure out what went wrong or see the opportunity you missed.
“Even the fastest CPU and memory technology usually can’t scale to large datasets – I won’t call it big data – on the order of numbers of terabytes and be able to query that in under one second,” Mostak declares. “It is just not in the realm of their capabilities, even on a decently sized cluster.”
No one is suggesting that all cores are created equal, of course, but with traditional database processing on a two-socket Xeon E5 server with ten cores each, Mostak says you can process maybe 850 million rows per second. But on that same two-socket server equipped with eight of Nvidia’s Tesla K80 dual-GPU coprocessor cards running the MapD database, you have a total of 39,936 cores (much smaller ones, mind you) and 192 GB of frame buffer capacity to store data and you can process 260 billion rows per second. The performance speedup that MapD has seen is impressive, and is akin to some of the boost that other parallel workloads in modeling, simulation, and machine learning have seen:
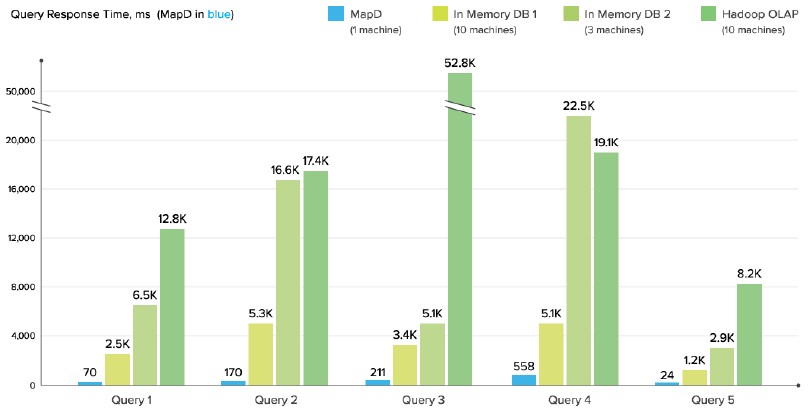
In the above chart, a single MapD database with eight Tesla K80s was pitted against two in-memory databases (which were not named, which is annoying) with ten or three clusters. The Hadoop OLAP setup is a Hadoop distribution running the Impala SQL overlay, also on ten nodes. As you can see, these SQL layers are easy, but no one would call them fast – at least not compared to in-memory databases or this GPU-accelerated database. (It would be nice to know what these queries are, and what the products are, but the important lesson is to always do your own testing. Such benchmarks are just the gatekeepers to try to figure out what the options might be.)
Mostak can’t talk about all of the customers who are kicking the tires on MapD, but he did provide some interesting teasers. Telecom giant Verizon is using MapD to correlate performance and error logs on the systems that run its network and to correlate it with call records for customers to detect errors on network updates or for SIM cards before customers report outages so it can be proactive. The prior system was based on a popular relational database (unnamed, of course), and it took hours to process billions of records, and now it is sub-second with MapD. Social media giant Facebook, which prides itself on creating its own software technology and has built a number of databases and datastores, has its Instagram unit is doing real-time analytics, but the use case is evolving. Simulmedia, a retail and adtech firm, is doing real-time analysis on ad impression datasets.
Scaling Up And Scaling Out
That is not the end of scalability for MapD. Some servers being built today can have as many as sixteen Tesla K80 cards in a single system, and the MapD database can partition the datasets and run them across all of the Tesla units. And when the Pascal GPUs come out in Tesla cards, they are anticipated to have more cores per GPU as well as more performance and more and faster memory, so MapD scalability will increase even more inside a single node.
But that will not be the end of it. With Pascal there comes NVLink interconnects for the GPUs, which will help them share data better, and Mostak says that MapD is looking at other ways to interconnect multiple CPU-GPU hybrid nodes together to scale out the MapD database and its Immerse visualization system even further.
“We do have plans on our roadmap to go distributed, and as you can imagine, some of our biggest customers want to scale up and out more,” says Mostak. “We will scale like a standard massively parallel database, and we will probably target InfiniBand. We can do this fast interchange between GPUs on a single box, and we already partition the data and act like a distributed database inside the box. We do something like MapReduce to reduce the queries off of each GPU. Using the same approach, we can scale across multiple boxes. Ideally, we would use InfiniBand and GPUDirect to link different servers.”
Given the scale of the problems that initial MapD customers are solving – remember this is not so much about big data as it is fast data, maybe the hottest 5 billion to 10 billion rows of data – Mostak doesn’t envision needing to scale much beyond a rack of hybrid server nodes with maybe 80 GPUs all lashed together running MapD. The basic distributed, clustered version of MapD is targeted for release sometime in the third quarter or the fourth quarter of this year.
MapD started out selling appliances with its initial software, but with the production-grade code, the company is shifting toward a software-only sale on certified system configurations. The appliance is based on a Supermicro system with four, six, or eight Tesla K80s, if you still want to go that route, and the software is also available on IBM’s SoftLayer cloud which has bare metal instances with a pair of Tesla K80s. The software-only license to MapD is available through a license based on the number of GPU cores in the box, and Mostak is not disclosing the official pricing because he is still working it out with customers.
But having said that, Mostak was willing to put some error bars on the top-end price. On a system with eight Tesla K80s, which might cost somewhere between $60,000 to $70,000, the license for the MapD stack would be “a small multiple” of this hardware cost. That is about what a relational database on a similar server with lots of CPUs would cost, so this is not unreasonable given the performance boost. MapD highly recommends the Tesla K80s for their memory capacity, bandwidth, and double precision performance, but for those who want to experiment, you can build a workstation with four Titan X graphics cards for under $10,000 to play.




Be the first to comment