

Transaction processing against relational databases may not be the focus of the datacenter, as it was when IBM created the first relational database and Oracle was founded to compete against it in the late 1970s. But transaction processing – counting the money that passes between customers and the companies that serve them – is still the backbone of the economy.
The funny thing is that IBM and Oracle are the two remaining companies that create co-designed hardware/software systems that accelerate the performance of databases while at the same time providing rock-solid reliability and the scalability that the Global 5000 require and that several hundred thousand smaller enterprise customers also value.
This week, Oracle has tweaked its Oracle Exadata database machines, providing them with more oomph and lower latency for database compute servers and flash storage servers that together run the eponymous Oracle database management systems. The Exadata X11M update, which is the thirteenth version of the Oracle engineered systems for running database workloads, comes pretty hot on the heels of the Exadata X10M machines that came out in the summer of 2023 and, significantly, represented a shift away from Intel Xeon processors in the database and storage servers and towards AMD Epyc processors.
Oracle has been engineering database systems for large-scale relational databases for a long time, and it is still interesting to take a look at how the architecture of these machines changes over time to meet increasing demands for speed and capacity. And with the Exadata X11M machines, it is also interesting to contemplate how AI is being woven into applications and embedded into the database compute and storage engines, and what it takes – and what it does not take – to add this functionality.
(Hint: It does not take a GPU to add AI functions, but it does take a healthy amount of vector processing.)
Larry Sings The NUMA NUMA Song
Just as the Great Recession was getting underway in 2007, Oracle started quietly shipping the custom designed, first generation Exadata X1 database appliances to selected customers who were looking for ways to cut their spending on big NUMA servers from Sun Microsystems, IBM, and Hewlett Packard Enterprise to run giant relational databases. These Exadata X1 machines were formally announced in partnership with HPE’s ProLiant X86 server division, and incorporate InfiniBand networks to link database compute engines to each other for scaling up a database as well as to flash-based storage servers that ran the underlying storage engine for the Oracle database. The Remote Direct Memory Access (RDMA) feature of InfiniBand, which gives this interconnect its low latency and which made InfiniBand a preferred network for HPC clusters, was a key component of the Exadata appliances.
A year later, Oracle launched its $7.4 billion bid to acquire Sun Microsystems, and in January 2010, that deal closed and Oracle co-founder and chief technology officer Larry Ellison (who was previously also its chief executive officer for decades) set about using Sun gear to create Exadata X86 database systems as well as variants based on Sun’s Sparc processors. (The last we saw of Exadata-like Sparc clusters, which still employed X86-based storage servers, was in the summer of 2016 with the Sparc S7 systems.) We covered the Exadata X6 machines in April 2016 during the early years of The Next Platform, and took a look at the Exadata X9 machines in October 2021.
Columnar data compression and processing was invented for the Exadata V1 appliances way back in 2007, which allows for data analytics to be run on relational databases orders of magnitude faster and for databases to be compressed into smaller and faster flash storage servers for accelerated scanning of data. Breaking the computational tasks of running a database management system from the SQL processing against data stored in the underlying database storage engine is what gives Exadata system both scale up (running larger databases) and scale out (running SQL queries faster).
The Exadata architecture looks obvious in hindsight, as all good technologies do, and it has been a boon for Oracle as it took on rival database makers and high-end system makers who have carved out their stakes in large scale enterprise computing. By 2016, Oracle had over 5,000 customers using its engineered systems, and while it no longer releases statistics on these systems, we have no trouble believing that it has many tens of thousands of customers using these machines, not only in on-premises datacenters but on the major clouds. Oracle not only has Exadata iron installed on its own Oracle Cloud Infrastructure cloud, but has convinced Amazon Web Services, Microsoft Azure, and Google Cloud to take its custom iron into their datacenters and rent time out on them as a service. These companies like to build their own iron, and it is a true exception when they are willing to invest in outside iron to try to capture workloads.
In a sense, the fact that big clouds will install and operate Exadata iron on behalf of customers is a testament to how these machines are built specifically to run Oracle databases and, even more accurately, how the most recent Oracle database releases are tweaked to make use of features in the Exadata systems and tuned for their very specific architecture.
The Exadata V1 machine from September 2008 was really for data warehouses and for fast scanning of information. With the Exadata V2 machines, Oracle added flash-based storage servers to the architecture and offloaded portions of the SQL processing to these storage servers while at the same time having optimizations for handling random reads and writes to the Oracle database on a combination of database and storage servers that makes Exadata V2 suitable for online transaction processing as well as data warehousing.
A decade and a half ago, a rack of Exadata V2 iron had 64 X86 cores with 576 GB of main memory across eight database servers and fourteen storage servers; the CPU of choice was Intel’s “Nehalem” quad-core Xeon 5500. The Exadata V2 had 40 Gb/sec InfiniBand links hooking the database servers to each other and to storage servers, and the latter sported a combined 336 TB of raw storage for databases and 5.3 TB of flash for an acceleration tier. Such a rack ran $1.15 million, and that was minus the Oracle database server software but with a base Oracle Linux operating system.
This was big iron at the time. But the iron is ridiculously bigger today, and has grown a lot faster in capacity than the cost has.
Here in early 2025, a rack of Exadata X11M machinery can have from two to fifteen database servers per rack and from three to seventeen storage servers per rack, allowing flexibility in the configuration to address different levels of compute and storage for Oracle databases. An Exadata X11M rack can have up to 2,880 AMD “Turin” cores and up to 42 TB of memory for database processing or up to 1,088 Turin cores and 21.3 TB of RDMA-addressable memory in the storage servers for dedicated SQL processing. Oracle is using a pair of 96-core Turin Epyc 9J25 processors in the plain-vanilla database server and a single 32-core Epyc 9J15 processor in the Z variant aimed at lighter workloads. The plain vanilla storage server has a pair of these Epyc 9J15 processors, and a lightweight Z version has only one. All of these processors run at a base 2.95 GHz and are custom to Oracle.
Exadata X11M customers can have up to 462.4 TB of performance-optimized flash or up to 2 PB of capacity-optimized flash per rack, and up to 4.4 PB of disk capacity if latency is not an issue and capacity is. Obviously, customers can mix and match the levels of each of these compute and storage components within the database and storage tiers. No matter the configuration of database and storage nodes, they are all connected by a two-rail, active-active Ethernet RDMA fabric that runs at 100 Gb/sec. Up to fourteen racks of Exadata iron can be interlinked into a giant database cluster with the existing switch fabrics in the racks. If you want larger configurations, you can add another tier of Ethernet switching and push it further.
Each storage server in the Exadata X11M providers up to 8.5 TB/sec of I/O bandwidth per rack for SQL operations and up to 25.2 million 8 KB database read I/O operations per second (IOPS) and up to 13 million 8 KB write IOPS per rack.
Here are some of the feeds and speeds of the individual Exadata X11M servers:
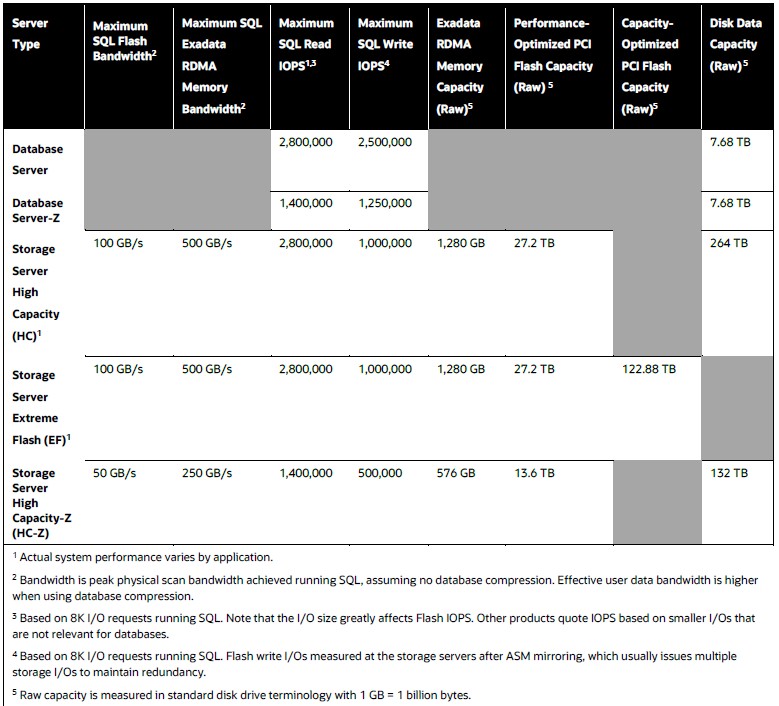
Now, let’s talk about money. With the same configuration of eight database servers (the plain vanilla ones, not the Z variants with low core counts), with 3 TB of capacity per database server, it is $1.78 million for that part of the Exadata cluster. Those eight database nodes have a combined 1,536 X86 cores (which are each probably 2X as fast as the Nehalem cores from 2009) and 24 TB of main memory.
If you use seven Extreme Flash storage nodes (with the skinny flash cards) and add eight High Capacity storage nodes (with a mix of disk and flash), that gives you 2.1 PB of disk and 408 TB of flash storage for an additional $1.18 million.
Add it all up, and that is a total of $2.96 million for a balanced Exadata X11M rack.
So, compared to the Exadata V2 from 2009, a rack of Exadata X11M has 24X the number of cores in the database servers and probably on the order of 48X more performance, with 76.8X the total main memory capacity across the database and storage servers, somewhere on the order of 7.5X the disk and flash capacity, for 2.6X the cost.
The lesson here is that adding compute is cheaper than adding storage, and that is convenient when the amount of vector math is going up thanks to AI for database operations and their applications. Vector search, which is running on the vector units in the Turin processors, can be offloaded to the storage servers and automatically parallelized across them. Like this:
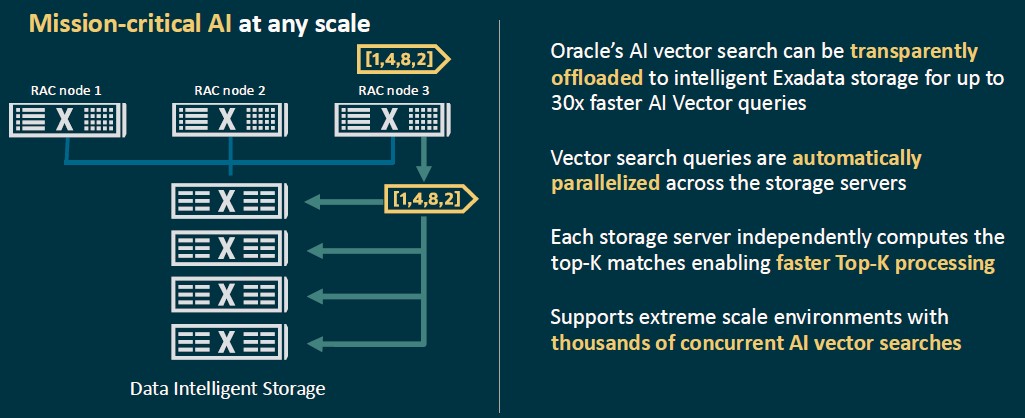
Thanks to that extra Turin vector oomph compared to the 96-core “Genoa” Epyc processors used in the prior Exadata X10M, vector search on the database servers in the Exadata X11M are 43 percent faster for in-memory vector index queries and on the storage servers are 55 percent faster for persistent vector index queries. The X11M machines can push 25 percent more transactions and thanks to faster 6.4 GHz DDR5 memory can deliver 43 percent faster data reads out of the flash for OLTP workloads.
Interestingly, according to Ashish Ray, vice president of products for Exadata, database cloud services, and multicloud at Oracle, pricing on the Exadata X11M machines is the same as on the prior generation of X10M machines that debuted in June 2023.
The two things you do not see in the Exadata X11M machines are faster Ethernet RDMA networks or GPUs from Nvidia or AMD.
Ray says that getting lower latency in the Ethernet network is much more important for a distributed database/storage server architecture than pushing up the bandwidth to 200 Gb/sec, 400 Gb/sec, or 800 Gb/sec on the ports in the interconnect. Here is a good example.
The Exadata X8M and X9M platforms used Intel’s Optane 3D XPoint memory as a fast cache tier in the storage servers, but with Intel spiking that product a few years back, Oracle created XRMEM memory cache, which takes a partition of main memory in the storage servers and links it to the database servers over RDMA links. On the X10M machines, the link from the database server to this XRMEM on the storage server had a 17 microsecond hop. By tweaking the microcode and network stack in the X11M stack, Oracle has been able to get that down to 14 microseconds, which is a 21 percent improvement in 8 KB I/O into the database server and which will boost overall throughput. All without requiring more expensive networking.
Despite the many ways that GPUs have been used to accelerate processing on columnar data – think Heavy.AI (formerly MapD and OmniSci), Kinetica, and SQream – Ray says that thus far this has been unnecessary to boost the performance of the OLTP and analytics workloads that Oracle customers run on their databases.
“A lot of the AI processing that happens in that Exadata platform and its Oracle database is related to AI vector processing,” explains Ray. “In other words, doing vector search, creating multiple dimensions of the vectors or vector indexing, and shortest distance Top K algorithms. Exadata is not in the LLM training business, where GPUs are particularly relevant. That’s why you see GPUs in our cloud in our GenAI service. With regards to Exadata, because it is largely used for structured, private business data, that’s where the vector processing happens, in this case on the super-fast AMD processors that we use for database servers and the storage servers.”
And when and if AMD adds tensor cores to its Epyc processors, you can bet Oracle engineers will be tweaking algorithms to make use of them. But we do not expect for GPUs or other kinds of accelerators to be added to Exadata database machines unless there is a compelling computational reason to do so. That could happen, particularly as AI functions themselves get added to the Oracle database management system.

AMD’s Instinct GPU Business Is Coiled To Spring
Timing is a funny thing. The summer of 2006 when AMD bought GPU maker ATI Technologies for $5.6 billion and took on both Intel in CPUs and Nvidia in GPUs was the same summer when researchers first started figuring out how to offload single-precision floating point math operations from CPUs …

AMD’s Top Brass Take Another Swing At Intel With Milan Epycs
It has been a long time – more than 15 years – since AMD has been in a position to pressure larger rival Intel in supplying processors to server OEMs and ODMs for the datacenter. In 2003, the company was able to surprise an Intel that was looking to force …

With ROCm Software And Instinct MI200 GPUs, AMD Has Ecosystem Critical Mass
Paid Feature Great hardware is the foundation of any compute platform. But hardware, in and of itself, is never sufficient to create a platform. And in fact, it takes two other important things for any platform to be realized. After the hardware, a platform requires a complete stack of software …
Great points about GPU-accelerated vector searches (and analytics; viz Heavy.AI, Kinetica, SQream)! Maybe, in-between the 96-core 9J25 and 32-core 9J15, the Exadata X11M line (or the next version) could consider a 48-core MI3J0A that would resemble an MI300A, but with 6 CPU-chiplets and 4 GPU-chiplets (instead of 3 and 6 in the 300A) … it might be the perfect chip to balance performance between those workloads that benefit nicely from GPU acceleration and those that don’t. And they could name it the H variant, for Hybrid (or Hubert – eh-eh-eh!).
I like the way you think, Hubert.
They call the database 23ai and include OLLAMA support but the exadata or DBA is unable to leverage it. 🙂
Secondly, the HW cost of exadata must be minuscule compared to the Oracle DB license cost of 2880 cores.
Example:
1440*35000USD (EE street price with a few modules after discount)=50M USD!
Oh yeah. That Oracle license is crazy town.
How much more expensive would you say an X11M is compared to an X10M? If they had similar motherboard ram, similar storage, etc., but if you essentially just changed from a “10” to and “11”?
The incremental cost is probably nominal, and the charge is zero. They have the same price.