

The concrete has been poured and the first containers that will house the exascale-class “Jupiter” system at Forschungszentrum Jülich in Germany are being lifted into place for the modular datacenter that will be the home of the massive machine.
These days, given the complexities and densities of compute, power, and cooling, supercomputer centers are thinking outside of the box, so to speak, about the box that wraps around their most advanced machines, and such is the case with FZJ, which has been on the forefront of cooling technologies and now, because of speed, cost, and simplicity, is moving to modular datacenters rather than the more traditional computing halls that it has built for its supercomputers.
The exact configuration of the Jupiter system, which is expected to be the first machine in Europe to break the exascale barrier, was still largely unknown when the machine was revealed in June 2022 as the Joint Undertaking Pioneer for Innovative and Transformative Exascale Research, a follow-on to the “Juwels” and “Jureca” supercomputers that run simulations and train AI models. In October 2023, some more architectural details about the machine were unveiled, but we still did not have specifics of the machine configuration – we think because things were still in flux and technologies were being adopted at the last possible minute and based on their actual availability. In June of this year, the architectural components were revealed, but we still do not know the precise configuration that FJZ will have to produce a 1 exaflops performance rating on the machine, which will be manufactured by the Eviden HPC spinout of French server maker and IT services provider Atos.
We recently talked Thomas Lippert, head of the Jülich Supercomputing Centre and director at the Institute for Advanced Simulation at the FZJ, about the modular datacenter, and to understand how and why this approach is being taken, it is perhaps best to look at the machine, which we meant to do in June of this year but got sidetracked away from.
To Jupiter And Beyond
FZJ, which was established in 1987, has always been the trailblazer in European HPC, so it makes sense that the exascale barrier will be broken for the European Union in western Germany halfway between Cologne and the borders of Belgium and The Netherlands.
Like all European supercomputing centers, FZJ is much more concerned about power and cooling efficiency than most HPC centers in the United States and Asia, and that is because both space and electricity are considerably more expensive in continental Europe than they are in those other regions. Electricity is at least 2.5X as expensive in Germany as it is in the US, and so making sure a supercomputer is as efficient as is practical means more of the budget for electricity ends up doing compute instead of being wasted as heat. This is why FZJ moved to warm water cooling, where water comes in at 34 degrees Celsius and goes out at 43 degrees, in 2021 for its supercomputers.
The Jupiter system has a hybrid architecture, with different kinds of compute modules, like its predecessor machines at FZJ and the Lumi machine at CSC in Finland. While the latter Lumi system is based on a mix of AMD CPU and GPU compute engines, Jupiter will be based on compute engines from Nvidia, which we suspected it might be.
The Universal Cluster Module, which we would call a CPU cluster, is going to be based on the “Rhea 1” Arm CPU from SiPearl, as expected, but oddly enough, we think the Booster Module, which is a collection of CPU-GPU nodes, will no doubt come to market first. And as we expected, the Booster Module in Jupiter has some architectural similarities to the Juwels Booster Module, shown below:
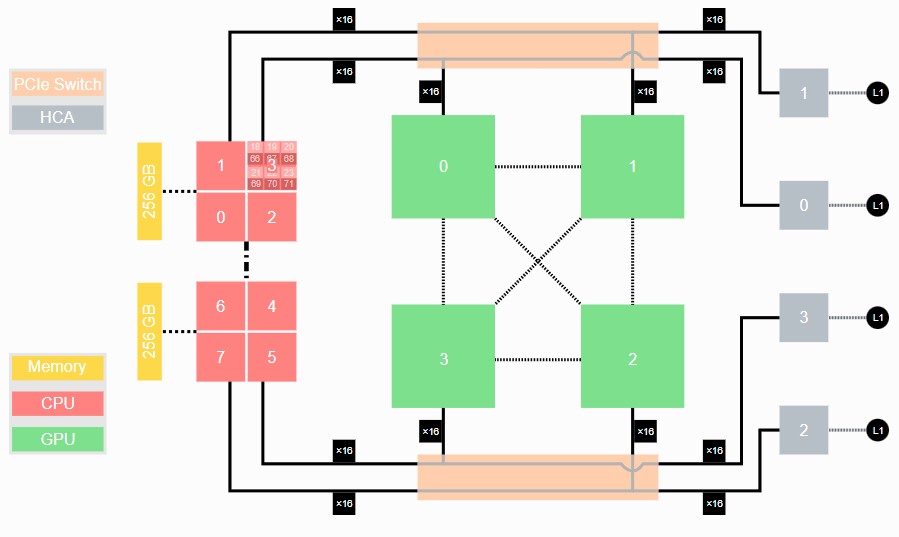
In the Juwels supercomputer, the Booster Module had a pair of AMD “Rome” Epyc 7402 processors that linked through a PCI-Express switch to a quad of Nvidia “Ampere” A100 GPUs with NVLink3 ports cross-coupled to each other without the need for NVSwitch interconnects.
With Jupiter, the Booster Module will have roughly 6,000 nodes, with each node being comprised of a quad of GH200 superchips from Nvidia, which tightly couple a “Grace” CG100 Arm server CPU and a “Hopper” GH100 GPU accelerator into a shared memory hybrid compute complex. As with the Jewels Booster Module, the CPUs are cross connected to each other and to the GPUs, but in this case, much more cleanly, using NVLink ports on the CPUs and the GPUs.

To be more specific, the Grace CPUs are linked to each other over NVLink ports running at 200 GB/sec and the Hopper GPUs are linked to each other over 300 GB/sec NVLink ports without the need (or latency hop) of an NVSwitch. This is, once again as we said with Juwels, clever. The GH200 superchips have 96 GB of HBM3 memory, with 3.9 TB/sec of memory bandwidth. The Grace CPUs have 72 cores running at 3.1 GHz and 120 GB of LPDDR5 memory with 500 GB/sec of bandwidth. The Grace CPU is directly linked to its companion Hopper GPU with a 900 GB/sec NVLink 4 interconnect. The Grace GPUs have a PCI-Express 5.0 x16 slot for linking each superchip to a 200 Gb/sec NDR InfiniBand adapter. InfiniBand fabrics from Nvidia link the 6,000 nodes, which have 24,000 CPUs and 24,000 GPUs, into a cluster.
The Booster Module will deliver at least 1 exaflops of performance on the High Performance LINPACK test – which is our definition of exascale as well as Lippert’s – and will have a peak performance of around 70 exaflops at FP8 precision on the Hopper GPU’s tensor cores.
As you can see, you don’t really need to wait for the Rhea 1 chip at all to bring a lot of CPU compute based on the Arm architecture to bear. The Grace CPUs use Arm’s “Demeter” Neoverse V2 cores, which have four 128-but SVE2 vector units each. With 24,000 Grace CPUs, that’s 1.73 million cores and 6.91 million vector units of math oomph that spans from INT8 to FP64 processing formats.
The Cluster Module will have considerably more memory bandwidth against Arm server CPUs. Each Cluster Module node will have a pair of Rhea 1 CPUs from SiPearl, which will each have 64 GB of HBM memory paired with an 80-core chip based on the “Zeus” V1 cores from Arm. The Rhea 1 nodes will also sport 512 GB of DDR5 main memory, and some nodes will have 1 TB. The expectation is that the Cluster Module will have more than 1,300 nodes and will deliver at least 5 petaflops of performance on the HPL test. Based on the performance specs of the Isambard 3 supercomputer at the University of Bristol, we estimate that the 24,000 Grace CPUs in the Booster Module will deliver about 84 petaflops of peak FP64 performance and probably at least 56 petaflops on HPL. (We shall see.)
The idea, as Lippert has explained many times in the past several years, is to increase the scale of key applications running on the 50 petaflops Juwels Booster Module by a factor of 20X.
This Home Is Modular, But It Doesn’t Have Its Own Wheels
Getting all of that iron together would seem like the tough part of building the Jupiter system, especially considering the difficulties of getting GPU allocations and starting an Arm server CPU from scratch as SiPearl is doing. But the building housing a supercomputer and the way power and cooling is delivered – and how it can accommodate generations of machines over time – is not an afterthought. These days, you start with the power you have available and you try to maximize the performance within a budget for power, cooling, and compute.
“When we got into the realization of Jupiter, we had several principles to obey,” Lippert tells The Next Platform. “First of all, we scaled up. Secondly, our energy consumption has to be considered. Thirdly, our waste heat production has to be seen. All of these infrastructure elements are as challenging as the IT technology itself, and at a certain stage we came to the conclusion that we would not go for a specific building, but a modular approach. And we should know, we have lots of experience with buildings here.”
The datacenter that FJZ built in 2004 for air-cooled systems had to be refurbished in 2010 for its first water-cooled system. In 2018, in partnership with Bull, FZJ installed the Juwels supercomputer, which pioneered the use of warm water cooling, and once again the datacenter infrastructure had to be retrofitted for this new approach.
Starting with Jupiter, the idea is to stop thinking about a big building that has to be retrofitted every couple of years as some technology changes and to start thinking about modular buildings that reflect the modular nature of the supercomputers that HPC centers like FZJ are building.
“So the container is the next unit of integration, and it has, of course, a lot of challenges but also certain advantages of modularity,” explains Lippert. “Our design decision with Jupiter is to have an assembly of specialized containers with all the features that you need for each module, and on top of each container you can also have cooling equipment. We decided to have a one story container, which seems to be sufficient.”
Atos is responsible for the modular datacenter containers as well as the Jupiter system, but it is subcontracting the manufacturing of the containers themselves. The containers are slightly taller and considerably wider than standard shipping containers that companies were trying to build datacenters with a decade ago. These containers are not good for building large scale systems – they are just not wide enough. The Atos containers are wide enough that they can be transported on roads, which is a plus, and they can be installed empty or full of gear as need be.
“There is a lot of flexibility in this concept,” says Lippert.
The way the Jupiter modular datacenter is being built, two containers are next to each other lengthwise and the walls between them are removed to make a larger module as a basic building block, holding two rows of gear and plenty of space to move around. The plan earlier this year was to have 20 doublewide containers for the Jupiter system, but now FZJ says it will have around 50 containers, or 25 doublewides, and will be about half the size of a professional soccer field.
Here is the base pad for the Jupiter datacenter:

And here is the first module being hoisted onto its raised bed:

Fully loaded, a container will weigh about 50 tons, according to Lippert. So they are not going to blow away, no matter how much climate change Earth has – unlike doublewide homes in America, which unfortunately do blow away from tornados and hurricanes.
This is what the Jupiter datacenter looks like with the first two doublewides on the raised slab:

Obviously, there is an opportunity to start thinking in three dimensions when it comes to HPC and AI systems, and if everything was being done with copper interconnects, we would most definitely have to think in 3D. But with silicon photonics betting more mainstream, we can flatten out datacenters out and maybe space them out a whole lot more without sacrificing performance, and then in ten years we can talk to Lippert about machines that span tens of acres and a return to outside air cooling. . . .
But it probably will not happen. Space will still be too precious, and water cooling is probably here to stay because the devices will be considerably hotter than they are today as we drive performance.
When we asked Lippert if this modular approach was more or less costly than traditional datacenter construction, he quipped that this was a very good question and laughed. “It is a little bit more fun to have a new concept. This is just a challenge, and it lets us think outside of the box. It is new thinking, and it allows you to have a modular aspect to the system such that in the future, we can already plan what we will do. We also believe that replicating this will be very easy – much easier than constructing a new building and then having to refurbish it. This will never happen here again. If a technology needs to be replaced, we will buy new containers and leave this nuisance to other companies.”
Time saved is a big factor. It takes about two years to get permitted and to build a transformer in Germany, according to Lippert. It takes three or four months to lay down the slab flooring and the supports for the modular datacenter, and about eight months in total to build the datacenter itself including the floor. It could take anywhere from two years to four years to build a datacenter in the traditional way.
As for power, FZJ has two 80 megawatt transformers for its computing, with redundancy in case one fails. Lippert says the modular datacenter will have 25 megawatts allocated to it, and that its sustained power draw will be somewhere between 12 megawatts and 15 megawatts.


Accenture Melds Smarts And Wares With Nvidia For Agentic AI Push
Over the past two years, enterprises have tried to keep up with the staggering pace of the innovation with generative AI, mapping out ways to implement the emerging technology into their operations in hopes of saving time and money, increasing productivity, improving customer service and support, and driving efficiencies. However, …

Bringing AWS-Style DPU Offload To The VMware Base
Databases and datastores are by far the stickiest things in the datacenter. Companies make purchasing decisions that end up lasting for one, two, and sometimes many more decades because it is hard to move off a database or datastore once it is loaded up and feeling dozens to hundreds of …
The Buck Still Stops Here For GPU Compute
It has taken untold thousands of people to make machine learning, and specifically the deep learning variety, the most viable form of artificial intelligence. And this is so true today that people just say AI for all three because the distinction is academic. One of the key researchers who has …
Great article! It’s nice to see Jupiter going beyond Venado and Alps in the GH200 direction (though El Capitan’s MI300A is likely even better), but, my-oh-my, how “butt” ugly is this installation going to be (last photo)!
It’s an architectural coming of age (18 yo) of Sun Microsystem’s original Project Blackbox Modular Datacenter concept to be sure ( https://en.wikipedia.org/wiki/Sun_Modular_Datacenter ), but that was soon to be “jokingly” referred to as “White Trash systems” ( https://www.theregister.com/2006/10/18/sun_white_trash/ ), and indeed, where are the wheels? (yuck!)
I’m glad Lippert found it fit to reassure us the 50-ton loading of each unit prevents it from meeting its Wizard of Oz at each wind gust. But I sure hope Alice Recoque gets to be more aesthetically pleasing than this here plain jane Jupiter Nascar pleather overalls fashion mishap!
Aw come on! It’s a modular “plederhosen” supercomputer, right in time for Oktoberfest! Very fashionable … can’t wait to see Vera Rubin sporting one of those in 2026 (ahem, eh-eh-eh!).
But yes, hopefully they commission local artists or schoolchildren to paint something inspirational over this structure that is currently reminiscent of the transshipment facility at a container seaport terminal (very useful, but not so pretty …).