

If you have the entire corpus of the Internet scrubbed of nonsense plus whatever else you can scrounge up in whatever language all put into the right format so you can chew on that data one token at a time with trillions of parameters of interconnections between those tokens to build a large language model for generative AI applications, you have an enormous problem.
Finding $1 billion, of which maybe $800 million will end up going to Nvidia, is only one of those problems. Finding someone to sell you the 20,000 or so of Nvidia’s “Hopper” H100 GPUs is another problem, and if you can’t do that, then getting the budget together to pay even more to rent those GPUs on a public cloud and lining up the capacity is also a huge problem.
Luckily for the Global 2000, not a single one needs to train their own LLM from scratch. And what is true of these upper echelon companies is also true of what we would call all bust a handful of the Global 50,000, the list of organizations that include large enterprises, HPC centers, hyperscalers and cloud builders, national and regional governments, and large academic institutions on planet Earth. This is the audience that The Next Platform is written for, and ultimately, this is the same customer base that AI startup SambaNova Systems is going to cultivate, starting at the top and working its way down. What is true of SambaNova is true of its system peers such as Graphcore, Cerebras Systems, and Groq as well as those who are just making motors for AI training and inference such as Tenstorrent, Esperanto Technologies and the big clouds that are also making their own AI engines such as Google, Amazon Web Services, and Meta Platforms.
Rather than build huge models using this text corpus alongside the data that each organization will bring to bear, the consensus is that most of these organizations will take a pre-trained model and tweak and tune it so it can focus on and perform generative tasks upon their internal – and usually secretly guarded – proprietary data.
But SambaNova is taking this all one step further, and thinks that organizations will not just build one big model, like Microsoft and OpenAI are doing with GPT-4 and the impending GPT-5 or Google is doing with PaLM and the impending Gemini, but will rather build dozens to hundreds of more tightly constrained AI models based on subsets of their own data, ending up with maybe 150 unique models that perform very precise generative AI functions across an organization. These models will be strung together with a kind of software router or load balancer at the front end, deciding after a prompt which model to push a prompt at, and be driven by a relatively modest amount of compute and memory to perform their training and inference because it is only running a small model, not a huge wonking one. Rather than making AI one big problem, SambaNova wants to make it a lot of smaller problems, covering the same trillions of parameters in the aggregate as a single model driven by several tens of terabytes to a few hundred terabytes of cleaned raw data across the Internet+ augmented corpus.
This, in a nutshell, is the strategy that has driven the creation of SambaNova’s first generation of its “Cerulean” series of reconfigurable dataflow units, or RDUs, the first of which is called the SN40L. The 40 means it is the fourth generation of chips from SambaNova and the L means it is tuned specifically for large language models. (Cerulean means “deep blue,” which we found funny given the heritage that SambaNova people have at former IBM rival Sun Microsystems.) The SN40L was announced this week, and we sat down with Rodrigo Liang, co-founder and chief executive officer at SambaNova, to find out about this new compute engine and what was happening among the Global 2000 customers that SambaNova is chasing along with more than a few national labs and probably a bunch of government agencies that Liang can’t talk about.
“We’re just brute forcing our way through these models,” Liang tells The Next Platform. “Going from 1 billion to 10 billion to 100 billion, then a half trillion, now a trillion parameters or more with GPT and moving towards five trillion parameters. All of that in the span of the five years since we started SambaNova. You see this explosion on these models, and we’re brute forcing our way through it, but because the computational requirements are linear to the parameter count, we have chip shortages because everybody wants their own large language model to power their own business. This is where we say we have got to stop this. AI is a generational change, and we have to stop and rethink this.”
Liang says that we are running out of publicly available tokens out of which to train models, but the parameter counts – akin to the synapse connections in our brains in a crude way of thinking about it – just keep going. The difference in performance of the various large language models are a few percentages off of each other in this brute force game, but that is not the game we should be playing.
“The private data that enterprises have is more important because it actually understands their business better,” Liang continues. “We’re arguing a couple of percentage points on the linguistics, and that’s only useful on the interface of the language. If I want to know my customers, my products, my services, my people, I have to understand the private data and then the accuracy of the generative AI jumps a step function.”
And to that end, SambaNova is advocating for enterprises to create a “composition of experts,” which means running a complete yet specifically tuned foundation model on each node in a system and then putting together an array of models on each dataset that an enterprise has: a legal corpus, a manufacturing corpus, risk management corpus, a wealth management corpus, a customer sales corpus, a customer support corpus, a medical corpus – whatever. These foundation models used by enterprises might be GPT-3.5 from OpenAI, but increasingly companies are looking hard at the LLaMA 2 model from Meta Platforms, which is open source with no restrictions finally and which is particularly popular and useful with 7 billion and 70 billion parameters for these use cases. A typical enterprise, reckons Liang, will have around 150 independent models, which gets them up in the area of more than 1 trillion aggregate parameters.
This strategy stands in stark contrast with what, for instance, Google is doing with its PaLM and Gemini LLMs, which we covered in-depth a few weeks ago. Google wants to create one giant model and then carve a path through it to only activate the sections it needs for any particular set of expertise for a prompt. Google does not want to create separate models for different tasks, as Jeff Dean, chief scientist at the company, explained at Hot Chips, but rather a single giant model that can generalize across millions of tasks.
Google might be right technically, but what SambaNova is proposing might be a lot more practical for the enterprise use case. And it has the benefit of not allowing access to the complete set of corporate data to anyone, but restricting access to data by restricting access to any particular expert within the composition of experts.

The SN40L, says Liang, is architected specifically to run a modest-sized model on a single device and to have lots of models running side-by-side. As you can see in the feature imaged at the top of this story and like the SN30 compute engine announced this time last year, the SN40L is a dual-chip device. It has a three-tiered memory architecture, the first time SambaNova has put that many tiers of memory on a device.
Like the prior three “Cardinal” generations of SN series RDUs from SambaNova (that’s the color and nickname of Stanford University), the Cerulean device has a fairly large capacity of SRAM distributed around its matrix math units and then it has a fairly hefty chunk of DRAM off chip to store model weights and parameters.
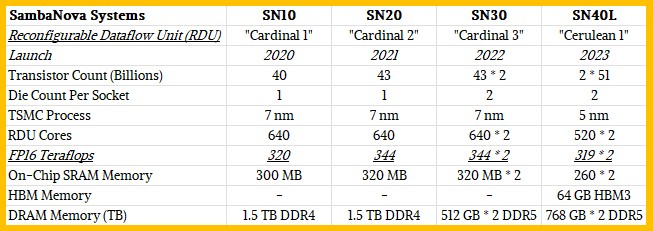
With the SN40L, SambaNova is also adding 64 GB of HBM3 high bandwidth memory, just like what AMD and Nvidia are using in their GPU accelerators. The HBM3 memory acts like a big, fat L3 cache for the on-chip SRAM, and the DRAM feeds into it from behind as a kind of L3 cache for the HBM3. At any given time, across 150 experts, a given prompt might only have to load one or two experts into HBM3 memory off of the DRAM and then it will run a lot faster than if it was coming in from DRAM.
The SN40L complex has 18.6 percent more transistors than the prior SN40L, which is less than you might expect given a shrink from 7 nanometers to 5 nanometers. The SN40L, at an aggregate of 1,040, has 18.8 percent fewer RDU cores than the SN30, but thanks to the 5 nanometer shrink must be running at somewhere around a 12 percent higher clock speed because the SN40L has only 7.3 percent lower FP16 throughput than the SN40L. We think that the move to faster DDR5 memory and the addition of the HBM3 memory will boost the effective performance of the SN40L above the SN30, even though the raw feeds and speeds are lower for the RDUs. It might even burn less juice, but it may not.
In the aggregate, a cluster of eight SN40L sockets can handle more than 5 trillion parameters, says Liang. And that would represent 71 models running at 70 billion parameter resolution. So two clusters of eight machines will give you all the models you might need for a Global 2000 enterprise given the logic that SambaNova is using.
The SN40L AI engine is available now. Pricing for SambaNova iron is not made publicly available, which is a shame. It makes it hard to compare to the alternatives, which all seem pretty pricey.


Pushing The Limits Of HPC And AI Is Becoming A Sustainability Headache
As Moore’s law continues to slow, delivering more powerful HPC and AI clusters means building larger, more power hungry facilities. “If you want more performance, you need to buy more hardware, and that means a bigger system; that means more energy dissipation and more cooling demand,” University of Utah professor …
The Battle Begins For AI Inference Compute In The Datacenter
The major cloud builders and their hyperscaler brethren – in many cases, one company acts like both a cloud and a hyperscaler – have made their technology choices when it comes to deploying AI training platforms. They all use Nvidia datacenter GPUs and, if they have them, their own homegrown …

HPE Throws Everything At AI – And AI At Everything
Hewlett Packard Enterprise has kept a steady drumbeat for much of the year as it looks to position itself as the go-to IT hardware and software vendor for the rapidly expanding AI market, which has grown from chatbots to AI agents in under three years. To that end, HPE is …
Google’s probably looking at massive heartburns with its super extra-large all-dressed stuffed-crust pizza approach to LLM development, with extra cheese. The healthy brain is much more of a cauliflower (2 grams of fiber per cup) where specific zones light-up to tackle different tasks. I expect that when they prune and cull their congestive coronary heart-disease-inducing and artery-blocking Gemini monster of computational cholesterol and diabetes, at autopsy, they will find (“oh Surprise!”) that it’s either tried unsuccesfully to split itself up into smaller task-specific functional sub-units, or just went up-in-smoke into a bliss of computational oblivion, with no moat to stop it, or both! Then again, SparseCores’ omega-3 and B12 superpowers, could make everything right again … hopefully (secret sauce).
Still, concerned parents and CTOs might prefer SambaNova’s approach of taking modest-sized bytes, of a healthy vegetable, and fully chewing through them side-by-side, with dual rows of teeth, so as to better match lots of cardiovascular and digestive AI systems, as well as reconfigurable dataflow units (RDUs). Plenty of fiber and HBM3 makes all of this much more regular too! q^8
You could be on to something here: https://citydance.org/why-you-should-try-both-samba-and-salsa-dancing/
Samba (Nova) is known to promote cardiovascular fitness, coordination and balance.
Salsa (SparseCores) is great for stress relief and improved flexibility.
Cha Cha Cha, Paso Doble, and Rumba remain available for future products … (eh-eh-eh!)