
Hardware is always the star of Nvidia’s GPU Technology Conference, and this year we got previews of “Blackwell” datacenter GPUs, the cornerstone of a 2025 platform that includes “Grace” CPUs, the NVLink Switch 5 chip, the Bluefield-3 DPU, and other components, all of which Nvidia is talking about again this week at the Hot Chips 2024 conference.
Flying somewhat under the radar was Nvidia’s NIM strategy for making it easier and faster for developers to create AI applications. There have been some talk about Nvidia Inference Microservices, but when something like Blackwell hits the scene, it can be difficult to steal much of the spotlight.
That said, NIMs are important to Nvidia’s larger plans to use generative AI tools like chatbot to let users develop AI software. Nvidia said NIMs offer everything a software engineer needs housed in a container-like environment and delivered as prebuilt microservices that can be deployed in the cloud or datacenters and on systems like workstations. The NIM containers built atop Kubernetes include open source large language models, a cloud-native stack, Nvidia’s TensorRT and TensorRT-LLM, its Triton inference server, and standard APIs, and are part of Nvidia’s larger AI Enterprise strategy.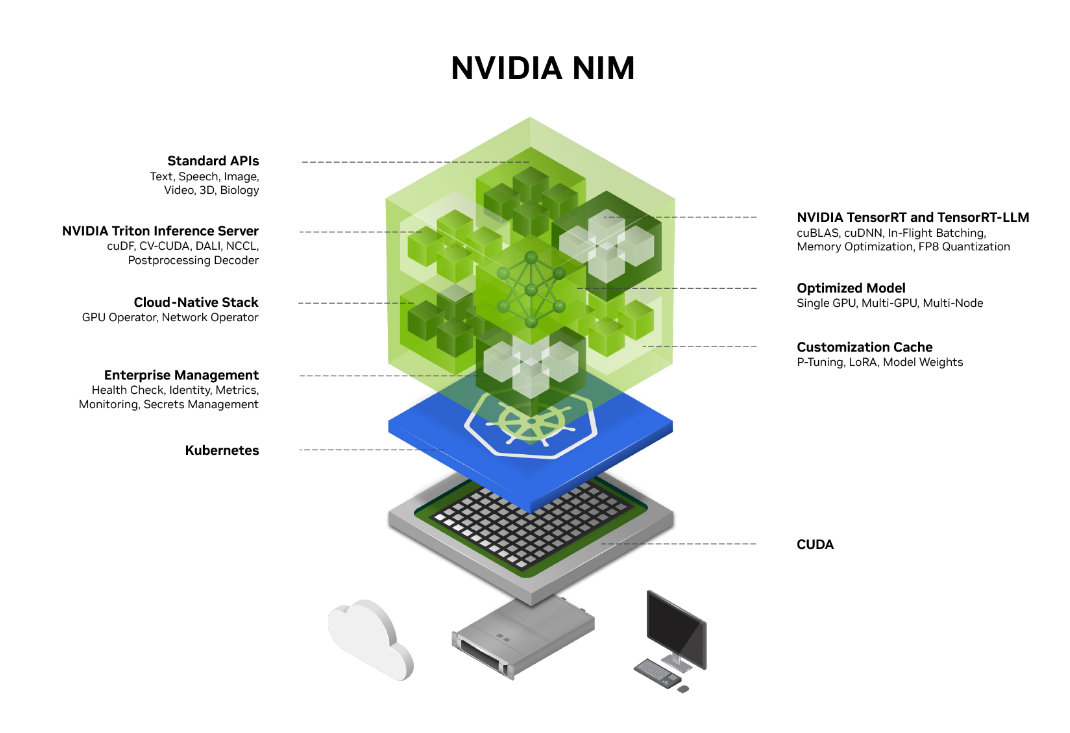
According to Justin Boitano, vice president of enterprise AI software products at Nvidia, NIMs are part of what he calls the second wave of generative AI, which will happen in enterprises and let them use their institutional knowledge for running their businesses, engaging with customers, and innovating much faster. The first wave, fueled by the enthusiasm after the launch of OpenAI’s ChatGPT in late November 2022, was driven by foundational model makers and involved infusing generative AI into internet services, improving individuals’ productivity by writing language and code.
In this new wave, “generative AI is going to help teams reason through complex business processes and supply chain dependencies to bring in new products and services to market at speeds no business has ever realized before,” Boitano told journalists and analysts in a briefing leading up to this week’s Hot Chips show in California. “The beginning of this was really the introduction of open models such as Meta Platforms’ Lama 3.1. These models represent an amazing advancement, bringing a new level of intelligence to enterprises that most couldn’t imagine running in datacenters just a few years ago.”
NIMs were created to make running such models at scale, in production, and securely, he said, adding that Nvidia is now working with a range of AI model builders to use NIMs to essentially make their models high-performing and efficient runtimes.
“These NIMs deliver performance optimization that results in token throughput efficiency that’s two to five times faster than other solutions, delivering the best total cost of ownership when companies run generative AI on Nvidia systems,” Boitano said. “By working with the ecosystem of community model builders, proprietary model builders, and with our own models, we ensure that any modality for any business can work seamlessly to get the best token efficiency for customers using Nvidia AI Enterprise.”
At Hot Chips, Nvidia is taking another step with NIMs, introducing NIM Agent Blueprints for developers who want to create custom generative AI applications. They’re reference AI workflows that include sample applications based on NIM and partner microservices, reference code, a document outlining customization and a Helm chart – files that detail and package a Kubernetes cluster’s resources as an application – for deploying the apps. Developers can modify the blueprints.
“This is an ever-growing catalog of reference applications built for common use cases that encode the best practices from Nvidia’s experiences with early adopters,” Boitano said. “Nvidia NIM Agent Blueprints are runnable AI workflows pre-trained for specific use cases that can be modified by any developer. They’re a starting point for performing what we see as some of the most important business tasks in enterprises.”
The NIM Agent Blueprints are part of what Nvidia describes as a “data flywheel” that go beyond accelerating the model. The models need to be enhanced and customized to address needs specific to organizations and their use cases. Under the flywheel idea, the as the AI applications runs and interacts with users, they generate data that can be fed back into the process and used to improve the models in a continuous learning cycle, he said.
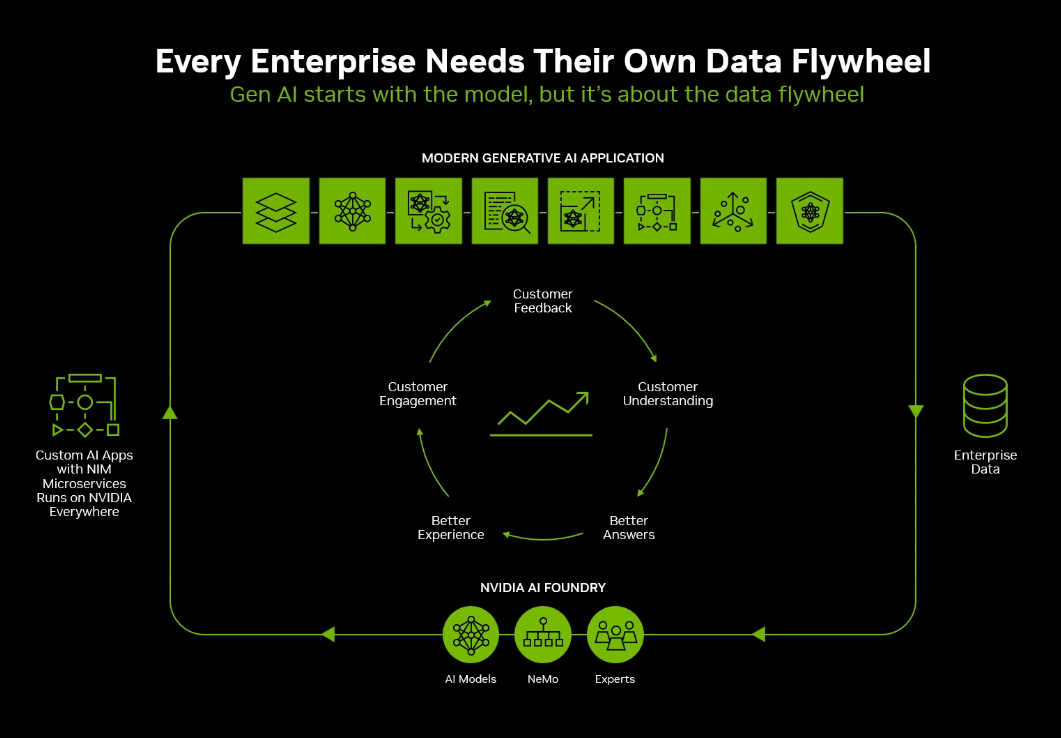
“Nvidia NeMo is the engine for running this flywheel,” Boitano said, adding that “Nvidia AI Foundry is the factory for running the flywheel of NeMo, and these customized generative AI applications allow enterprises to engage customers and employees with better and higher quality experiences.”
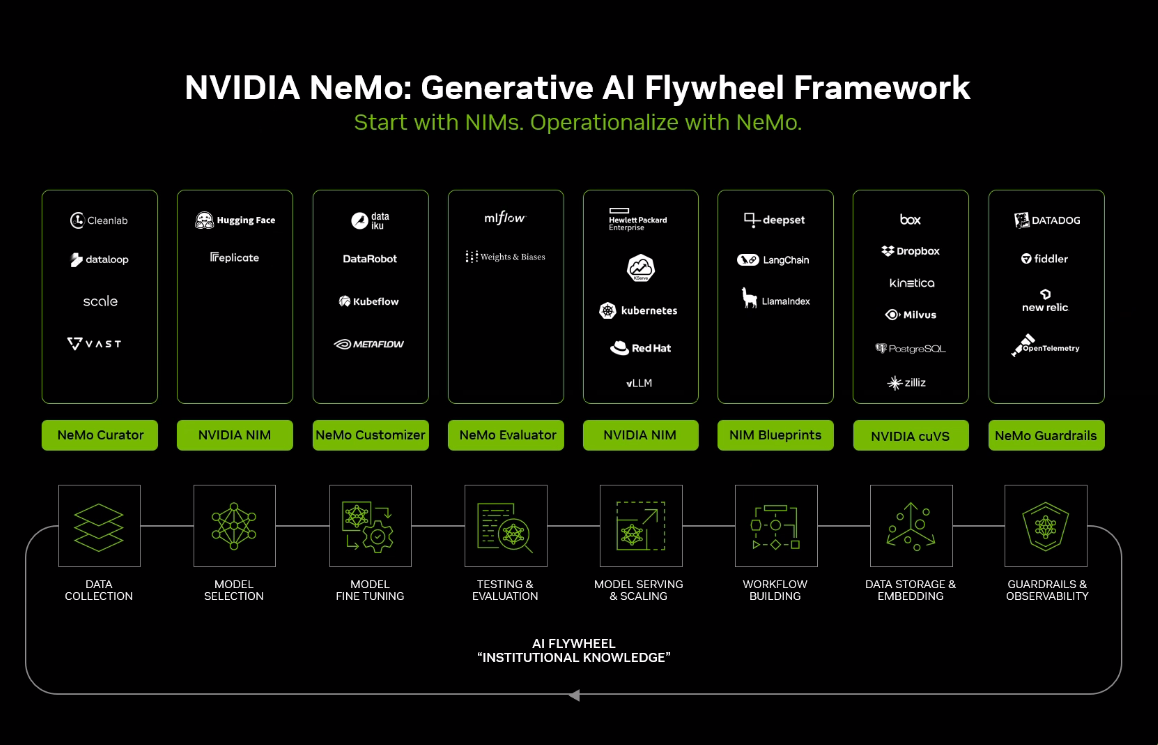
He added that the “application building process actually starts with a NIM, but in order to build the data flywheel, the Nvidia NeMo framework is used for data curation, model customization, evaluation, and is used to enhance the application to put it back in production. NeMo accelerates all the compute-intensive stages of the generative AI app development lifecycle, and we have a broad ecosystem of partners who build on NeMo and NIMs to make it easy for enterprises to develop their own generative AI applications.”
Organizations since the initial generative AI rush have talked about the need for organizations to be able to customize their AI efforts by incorporating their corporate data into the training and inference mix, a push that brought along retrieval-augmented generation (RAG).
Nvidia is initially release blueprints for three scenarios, including a digital human for the customer experience – for creating 3D digital humans that can interact with users – that enables multi-channel communication and connects to RAG systems. Another is for multimodal PDF data extraction for enterprise RAG.
“There are trillions of PDFs generated every year across enterprises and these PDFs include multiple data types, including text, images, charts, and tables,” he said. “The multi-modal PDF Data Extraction Blueprint helps organizations to accurately extract knowledge contained in their massive volume of enterprise data, effectively allowing users to access this data through a chat interface or quickly turn a digital human into an expert on any topic, and enabling your employees to make smarter and faster decisions.”
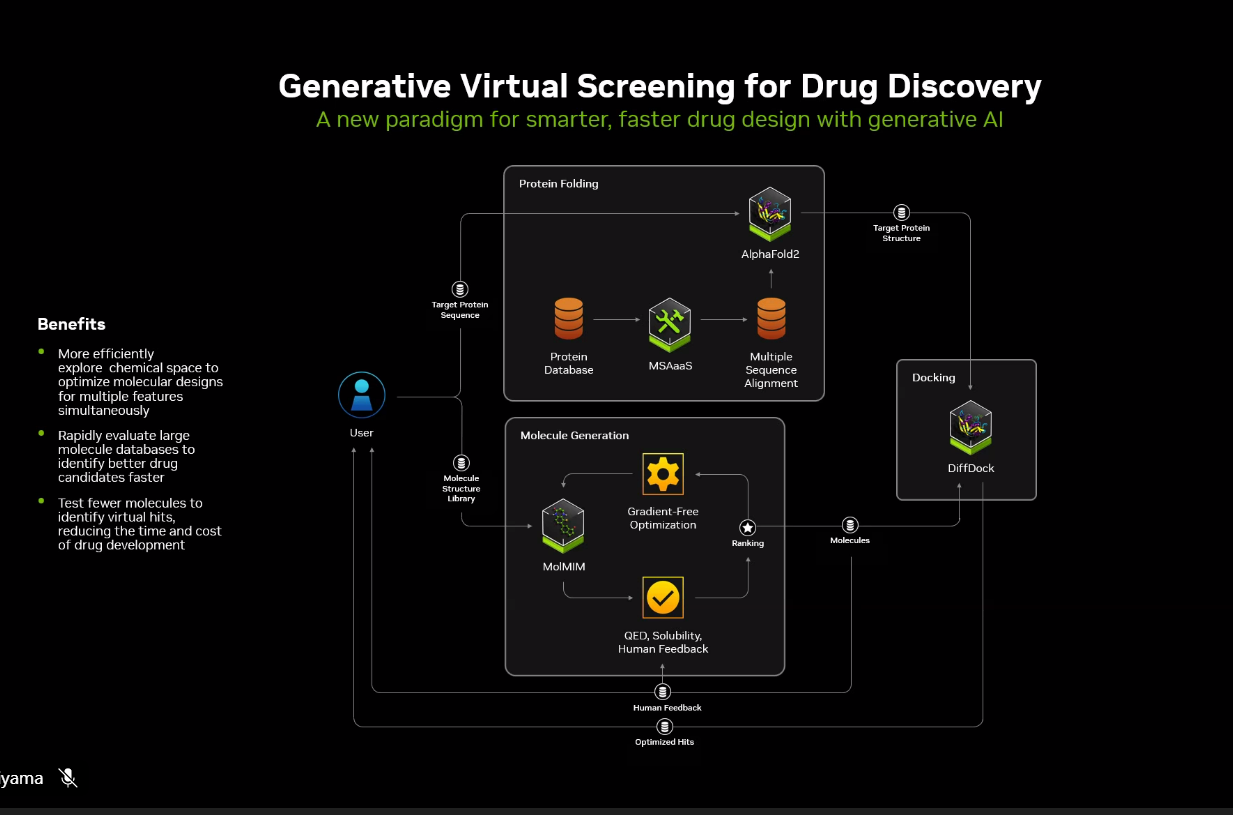
The last is accelerated drug discovery, using generative AI to simulate molecules that can target and bind with proteins.
Nvidia is bringing in Accenture, Deloitte, SoftServe, Quantiphi, and World Wide Technology to deliver NIM Agent Blueprints, Dataiku, and DataRobot for fine-turning models and monitoring LlamaIndex and Langchain for building workflows, Weights and Biases for evaluating applications, and CrowdStrike, Datadog, Fiddler AI, New Relic, and Trend Micro for cybersecurity. Enterprise portfolios from Nutanix, Red Hat, and Broadcom will support the blueprints.
They will also run on systems from OEMs like Cisco, Dell Technologies, Hewlett Packard Enterprise, and Lenovo, as well as hyperscale systems from Amazon Web Services, Google Cloud, Azure, and Oracle Cloud Infrastructure.


Intel’s “Ponte Vecchio” GPU Better Not Be A Bridge Too Far
It is pretty obvious to everyone who watches the IT market that Intel needs an architectural win that leads to a product win in datacenter compute. And it is pretty clear that the top brass at Intel are putting a lot of chips down on the felt table that the …
Nvidia Says It Will Be An Accelerator Of Quantum Computing
The way that Nvidia co-founder and chief executive officer Jensen Huang sees it, his company’s role in the ever-emerging quantum computing field is no different than that in other industries where AI and accelerated computing play roles. Nvidia is an enabler and facilitator. It makes things happen. “Nvidia doesn’t make …

Hot On The Heels Of Mellanox, Nvidia Snaps Up Cumulus Networks
Last week, when we talked to Nvidia co-founder and chief executive officer, Jensen Huang, about how the datacenter was becoming the unit of compute and in such a world networking was critical, it was obvious that acquiring Mellanox Technologies for $6.9 billion was just the beginning of the strategy that …
A flywheel for drug discovery? They must be shooting to spliffer HQ on over to mile-high Denver, CO, first-up in the cloud-native stack of funny smoke … (or not, ahem! maybe?)! “Inquisition minds” … 8^b
Well, that’s one pretty fly interpretation, high as a tethered heavier-than-air rectangular-ish craft IMHO.
I’m partial instead to the more grounded functional analogy between the mechanical flywheel and the electrical inductor, or in-doctor, as we commonly say here in Appalachia. If the doctor’s in, indeed, then he/she must necessarily investigate the development of new drugs, and if NIM can help with that, then so much the better!
Denver’s nice, for a Rockies town, but do beware of mixing the thin air of high altitudes, with the thick air of the magic smoke, as you’ll need to breathe simultaneously faster, and slower. I think it’s easier here in Appalachia, where the grass is green and doctors are pretty!