

The vibe around generative AI is still one of a land rush since OpenAI unleased ChatGPT into the public sphere in late November 2022, with investors dishing out millions of dollars, vendors big and small pumping out products and services, and organizations trying to integrate them into their back-office and user-facing operations.
But coalescing underneath all this is an understanding that enterprises need to be able to take advantage of what generative – and predictive – AI offer. Those needs include ways to incorporate proprietary information into the datasets used to train the large-language models (LLMs) and to customize those models to fit their businesses and industries, and just as importantly to do this in an affordable way.
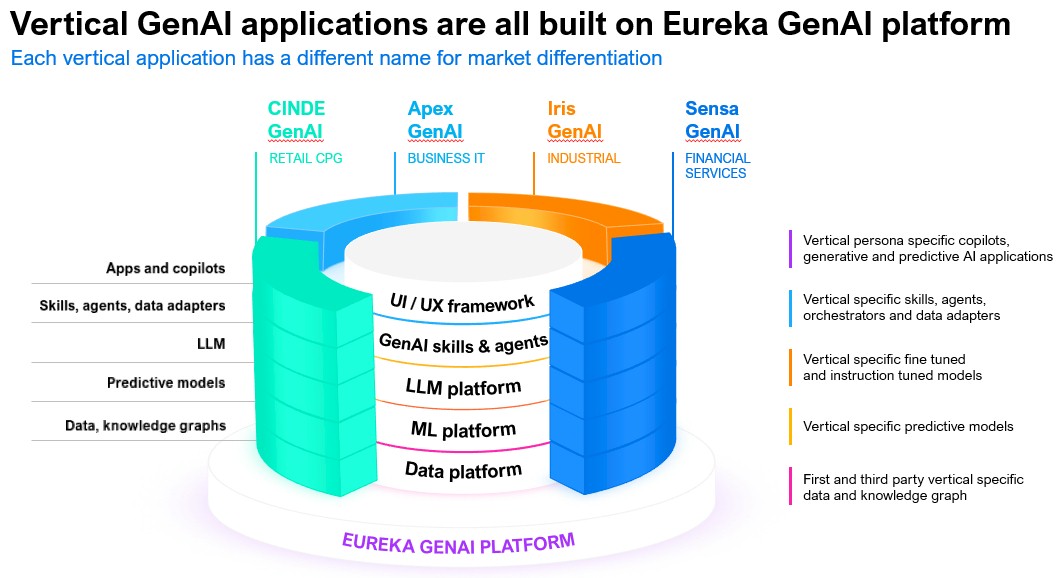
That’s the sweet spot that SymphonyAI is trying to hit with a combination of a common generative and predictive AI platform that supports industry-specific applications. SymphonyAI was founded in 2017 by Romesh Wadhwani – also board chairman – who spent $1 billion buying about ten companies that form the verticals the company used to create specific corporate divisions: retail, financial services, industrial, media, and business IT, according to Prateek Kathpal, president of SymphonyAI’s industrial division.
The company also built a predictive AI model in-house and over the past year, as generative AI gained steam, fine-tuned trained to give the platform its generative AI capabilities. Kathpal says SymphonyAI has a close partnership with Microsoft and OpenAI, which Microsoft has invested more than $10 billion in, and also uses Llama LLMs in on-premises and edge environments.
The result is Eureka, the common platform three years in the making that runs both generative AI and predictive AI training and inference workloads, creates task-specific and industry-specific LLMs, houses a datalake architecture, provides for natural language interactions, and provides a single home for machine learning data. It’s cloud-agnostic – it can run on Microsoft Azure or Amazon Web Services (as well as Google Cloud, though no customer has asked for it yet) – and also can run in enterprises’ own clouds or on-premises facilities.
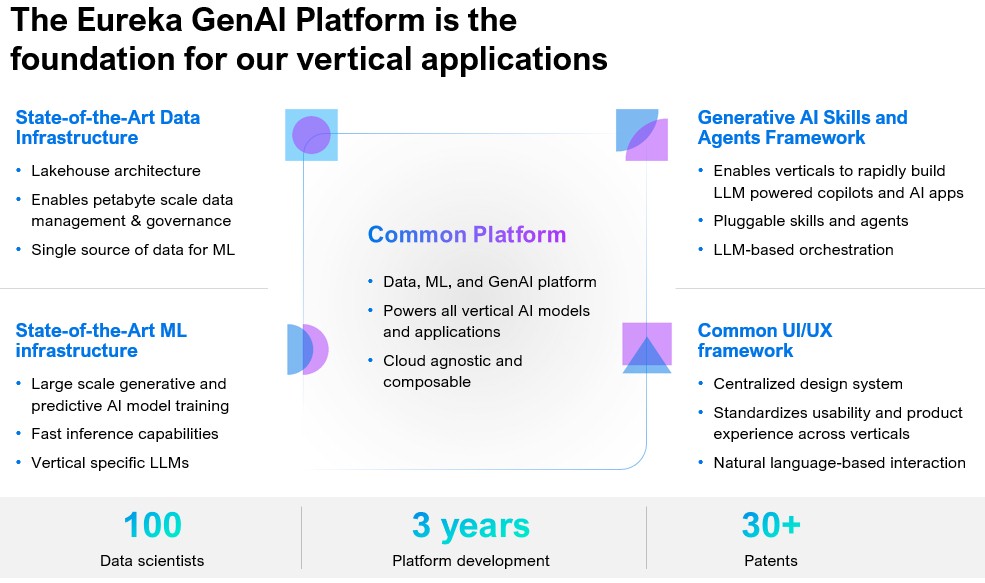
TensorFlow-based Eureka ties to applications in the verticals via connectors and delivers industry-specific generative AI capabilities through software copilots.
“It has a built-in predictive and generative AI as core components within that,” Kathpal tells The Next Platform. “It does both, predictive as well as reasoning and also has the capabilities of orchestration and device discovery. It also comes with integration connectors to both upstream and downstream systems, so whether you’re using a SAP or another enterprise resource planning application or whether you’re using certain retail data lakes or in the industrial, we have all those integrations based on different vertical already mapped out. We bring the data into this data transformation platform and what Eureka does is that, along with data ingestion and transformation, adds the AI applications capability, which is the layer of the predictive AI and generative AI on top.”
Organizations within each vertical can run SaaS applications that are specific to their businesses and industries while leveraging the underlying AI platform for jobs that are common to all of them.
“We can connect into your environment,” he says. “We can contextualize your data and then provide the analytics capability on top. Starting from your data contextualization to creating a knowledge fabric on top – which we do as our proprietary code – and then we add the pre-trained LLMs or the predictive models, which is our core IP, to provide you the insights.”
Seven years into it, SymphonyAI now has about 3,000 employees and more than 2,000 customers spread across the particular verticals, with some impressive names like Coca-Cola, Kraft Heinz, 3M, Siemens, Hearst, Toyota, and Metro Bank. The list includes the top 15 grocers, top 25 consumer product goods companies, and 200 of the largest financial institutions, global manufacturers, and entertainment companies, according to the company.
SymphonyAI has reached about $500 million annual recurring revenue (ARR) – and growing at about 30 percent a year – is EBITDA-positive, and is moving toward the “IPO stage,” he says.
Still, SymphonyAI is continuing to evolve not only what it offers but also what it uses, in part to drive down costs. The company has been running many of its AI workloads on systems powered by Nvidia GPUs, but Kathpal says it is beginning to work with Intel and its CPUs as well a system-on-a-chip (SoC) vendors – pointing to SambaNova as an example – to avoid the costs of the GPUs where they’re not needed.
For example, an LLM that is used in an edge scenario doesn’t need to run the full 7 billion parameter Llama model.
“We could train the LLM from ground up – which we did on a very specific use case – and then just run it on a CPU with large memory,” he says. “That’s another way what we have been doing recently to reduce the edge cost.”
There also are organizations running SymphonyAI models locally in both edge and hybrid configurations, part of the company’s move toward LLMs that run in both the cloud and on-prem and draw data from both to solve a question.
It falls in line with a direction the company is taking beyond just training and fine-tuning LLMs and toward special-purpose, extremely use case-specific data and leaving more general-purpose data out.
“They’re much smaller in size,” Kathpal says. “You aren’t required to run the full 7 billion [parameters] because nobody in the industrial application or retail or financial services is going to ask, ‘What is the height of the Eiffel Tower?’ There’s no point in having all that data training on the model, as long as it has the grammatical context. It should be able to answer the question, but you then train it on your use-case specific data, and that’s a special-purpose LLM approach that we’re taking.”
It’s part of SymphonyAI’s push to reduce the cost of training and running LLMs, with the being “to have them run on a CPU and remove the whole GPU cost, and have it enough of a mini size. That’s where training a model from a larger model is the is the new concept now. You use the larger model as a teacher to train your general-purpose LLM.”
The compute capacity Symphony uses depends on the industrial segment and the customer’s need. SymphonyAI may be seven years old, but the companies Wadhwani bought at the beginning were as old as 20 years and brought their legacy data to the LLMs, he says. In the industrial segment, SymphonyAI has 10 trillion data points in the repository.
The first algorithm written for the segment was trained on about 3 trillion data points and was taken to market. In financial services, SymphonyAI is collecting petabytes of data to train its models.
“We’re spending a considerable amount of dollars on just training our models … so even though we had 10 trillion data points, we stopped at 3 trillion in training, not because we didn’t want to go all the way but just because of the cost and the implications around that,” Kathpal says. “What is the right point between training as well as the quality of the output that you can get? What’s that fine point between the two where you should say, ‘This should be enough to get to the 99.9 percent accuracy that you need,’ or the qualitative and quantitative information that that needs to be derived from that model?”
The company also can use the anonymized data from customers to further train the models and 99 percent of customers are ok doing that, he says. For some in such verticals as financial services, they can’t allow that, but most can. And it’s good for them, because it improves the models that they then use for their businesses.
Pricing is based on either the amount of data that the SymphonyAI platform is taking in or via a per-seat license. The company doesn’t charge for the Eureka AI platform, but it does for the applications on top of the platform. Each of the verticals have different users and use case-specific applications that customers pay for.
And it’s a deal for organizations, he says, many of which don’t have data scientists or any other AI experts on staff. It makes more sense to use an out-of-the-box platform that comes with connectors that pull in their downstream systems and move on from there.

Datacenter Infrastructure Spending Is Up, And Forecasts Are Even Higher
The AI boom is going sonic, and it looks like we had all better cover our ears if we want to be able to hear by the end of the holiday season if the prognostications of the box counters at IDC are correct. IDC has juts tallied up datacenter spending …
IBM’s Red Hat Acquisition Will Pay For Itself By Early Next Year
Big Blue has reported its financial results for the third quarter of 2024, and the thing that stands out most is not the System z16 mainframes and Power10 midrange and big iron are getting a little long in the tooth ahead of new product cycles expected to start in 2025. …

A Second Opinion On Future GenAI Spending
Two weeks ago, before we began our nightmare travels to get to the 2025 edition of Nvidia’s GPU Technology Conference in San Jose, we put together an analysis of the AI server and storage spending forecasts put out by the good folks at IDC. Now, we have a similar, and …
Be the first to comment