
If the original equipment manufacturers of the world had software massive software divisions – like many of them tried to do a two decades ago as they tried to emulate IBM and then changed their minds a decade ago when they sold off their software and services businesses and pared down to pushing tin and iron – then maybe they might have been on the front edge of AI software development and maybe they would have been closer to the front of the line for GPU allocations from Nvidia and AMD.
But they were not.
And that is why companies like Dell and Lenovo are still waiting to catch the generative AI wave as it washes into enterprise datacenters. Just like Hewlett Packard, which has some exceptions thank to the hybrid HPC/AI supercomputers it is selling to major HPC centers around the world based on AMD and Nvidia GPUs but which is really still waiting for GPU allocations so it can build more modest AI training and inference clusters for enterprises. We do know that AI/ML drove more than half of Supermicro sales in the most recent quarter for Supermicro, and we think that more than half of that came from one customer (Meta Platforms), but no one thinks for a second that even Supermicro has enough allocations of GPUs from Nvidia and AMD to start selling in volumes to large enterprises that are eager to build AI clusters.
In catch up mode after being on the road at the AMD MI300 GPU launch event last week in San Jose – we are putting together our deep dive on the architecture and competitive analysis for these devices – we having a look at the most recent financial results for Dell and Lenovo so we can understand their datacenter businesses and integrate them into a larger model to assess what is going on in the datacenters of the world and where the money is flowing – and not.
Let’s start with Dell.
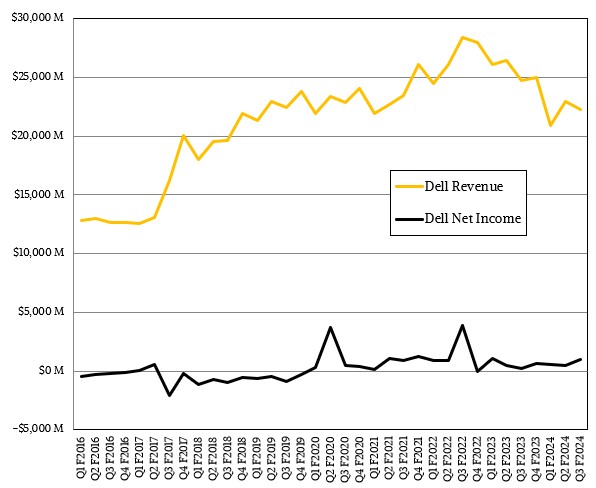
In the fiscal third quarter ended in October, Dell booked $22.25 billion in sales, down 10 percent, but net income was up by a factor of 4.1X to just a tad over $1 billion. Dell was able to boost its net income by paying off debts and reducing its interest costs by $1 billion and also cut costs to help compensate for lower gross margins as it absorbed higher parts and manufacturing costs.
Of that, $12.28 billion of that was for client devices, which we don’t care about except inasmuch it gives Dell a larger supply chain to leverage against its parts suppliers and should client devices contribute profits then it takes some of the heat off of the Dell datacenter business, which is definitely under a strain as companies large and small have sought to minimize server and storage spending as much as possible so they can invest in AI development and platforms this year.
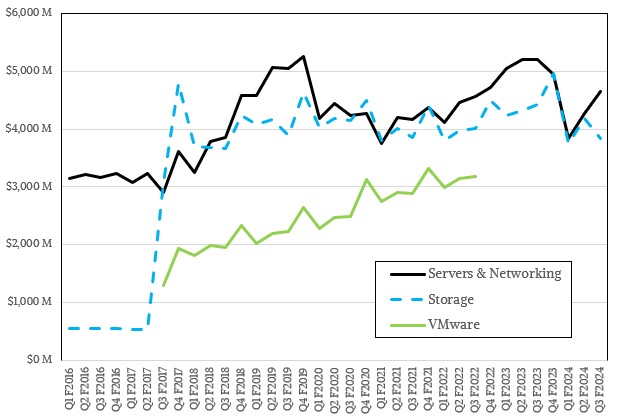
In the October quarter, Dell’s Infrastructure Solutions Group had $8.5 billion in revenues, down 11.7 percent year on year. This is the third straight quarter of decline for this business, and within ISG, both Servers & Networking (which is counted as a single unit) and the Storage (which includes the legacy Dell storage business plus EMC) divisions have been in recession for those three quarters. This is not the longest stretch of declines in the Servers & Networking division, however, which had declining quarters from Q1 F2020 through Q3 F2021, inclusive – a very bad stretch, indeed. Dell started hurting in servers thanks to Inspur and Lenovo way before COVID hit in early calendar 2020 and then COVID seemed to make things worse, not better.
In the latest quarter, Dell’s Server & Networking division had sales of $4.66 billion, down 10.5 percent, and its Storage division had sales of $3.84 billion, down 13.2 percent. Add them together, take out operating costs, and ISC had an operating income of $1.07 billion, down 22.2 percent, and comprising 12.6 percent of revenues.
Jeff Clarke, Dell’s chief operating officer, said on a call with Wall Street going over the numbers that demand for traditional servers improved and that demand for AI servers “continues to be strong” but that sales of AI-optimized systems only contributed a little over $500 million in sales. These include its PowerEdge XE9680, XE9640, XE8640, R750, and R760xa servers. “Customer demand for these AI servers nearly doubled sequentially, and demand remains well ahead of supply,” Clarke said. But, again, demand is not the same thing as revenue, and the main bottleneck are the relatively low allocations of top-end GPUs from Nvidia and now AMD that the OEMs – Hewlett Packard Enterprise, Dell, and Lenovo are the important ones for North America and Europe – are getting compared to the hyperscalers, cloud builders, and a few notable customers like car maker Tesla. When it comes to “Hopper” H100 GPU accelerators from Nvidia, not one OEM is among the top twelve who were allocated Hopper GPUs this year, and Tesla was, according to market researcher Omdia, number twelve on the list with 15,000 devices.
This is why the server businesses at Dell and other OEMs are not growing. And don’t jump to the conclusion that there are huge profits in reselling Nvidia GPUs – that certainly has not looked to be the case with Supermicro or HPE thus far. Nvidia and AMD are not leaving much margin on the table for the OEMs, no more than Intel did when it had hegemony in datacenter CPUs.
Clarke said on the call that AI servers accounted for a third of orders (in terms of value, not shipment) in Dell fiscal Q3, and added that the PowerEdge XE9680 is the fastest ramping product in Dell’s history of selling iron. No surprises. It is also the most expensive system Dell has ever sold. (Dell is one of the suppliers of iron to GPU cloud provider CoreWeave, which had 40,000 GPUs allocated to it for shipment by Nvidia this year, according to Omdia. So that is helping Dell’s AI server business book some revenues, much as the US Department of Energy supercomputers are helping HPE push hybrid HPC/AI iron.) Clarke added that Dell’s orders for AI servers, which nearly doubled sequentially from fiscal Q2, stands at $1.6 billion, and the multi-billion pipeline of prospects for AI systems has tripled some fiscal Q2. (Wall Street pegs it at around $5 billion.) Demand is way ahead of supply, and lead times stand at 39 weeks for these AI systems.
Over at Lenovo, the story is similar as we have seen out of HPE and Dell, with some specific twists that are always unique to Lenovo, which has a sizable presence in HPC and AI in the United States, Europe, and China.
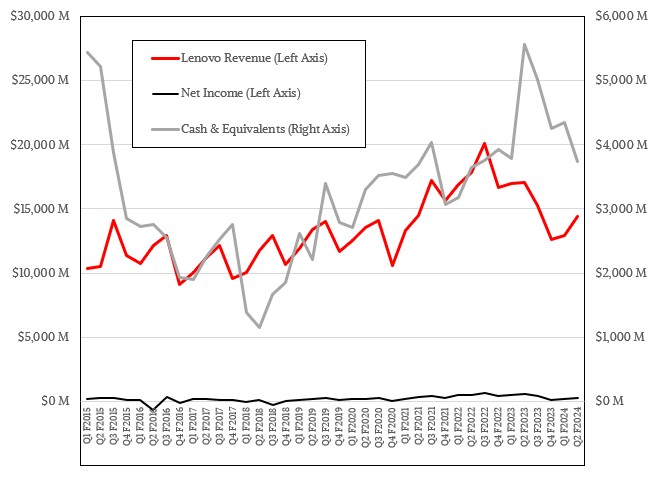
In the second quarter of fiscal 2024 ended in September, Lenovo had sales of $14.41 billion, down 15.7 percent year on year, and net income of $249 million, down 54 percent. Cash and equivalents stood at $3.74 billion. Lenovo, like HPE and Dell, are wrestling with digestion problems in both the PC and the server markets. We also think Lenovo has been impacted as companies are hoarding budget for AI projects.
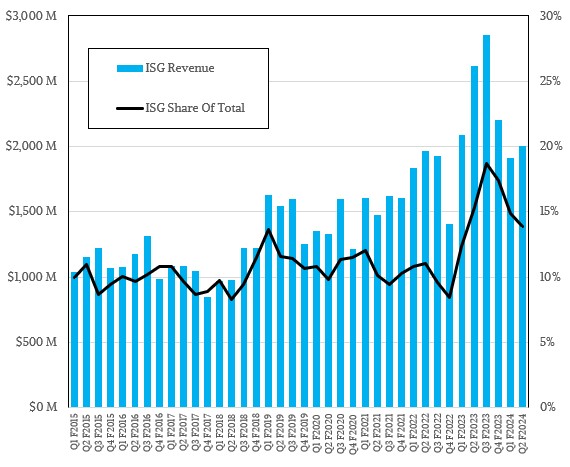
The Infrastructure Solutions Group at Lenovo, which comprises its server, storage, and networking businesses in the datacenter, had its second straight quarter of revenue decline, with revenues of just a tad over $2 billion, down 23.4 percent year on year but up 4.6 percent sequentially. ISG had an operating loss of $53 million, following an operating loss of $60 million in the first quarter of fiscal 2024, neither of which must be making Lenovo happy. Prior to this, Lenovo had seven straight quarters of operating gains in its datacenter business.
Lenovo does not provide a detailed breakdown of its datacenter business, but did say that its traditional HPC business grew in the double digits year on year and that it was the fifth straight quarter of consecutive growth for this unit. Storage revenue set an all-time high record and Lenovo is now the number three storage vendor in the world, and is number one in low-end storage devices that cost $25,000 or less.
Lenovo did not talk about its AI server pipeline, but Kirk Skaugen, who is president of ISG and who formerly ran the Intel Data Center Group at Intel, did say that Lenovo had spent $1.2 billion on HPC and AI systems – the line is a fuzzy one between the two – and had just decided to add another $1 billion for research and development to push the AI envelope over the next three years for datacenter, edge, and cloud customers.


AMD Hits Intel Below The Belt In The Datacenter Wallet
What Intel calls “cloud digestion” as the cause of the massive pullback in spending in its Data Center Group is looking more and more like a case of “Epyc indigestion” for Intel, not for the hyperscalers and cloud builders. And the top brass at Intel should be thanking the heavens …

GenAI Boom: Datacenter Spending Forecast Raised Again
Economic and technical forces have a kind of momentum that keeps them growing even as any new technology goes through its inevitable hype cycle from innovation to inflated expectations to disillusionment to deployment into productivity. As far as Gartner chief forecaster, John Lovelock, is concerned, we hit the peak GenAI …

Pushing The Limits Of HPC And AI Is Becoming A Sustainability Headache
As Moore’s law continues to slow, delivering more powerful HPC and AI clusters means building larger, more power hungry facilities. “If you want more performance, you need to buy more hardware, and that means a bigger system; that means more energy dissipation and more cooling demand,” University of Utah professor …
The CoWos-HBM packaging supply chain could probably have exercised more foresight in preparing itself for this tsunami wave of demand, but at least we see the major OEMs navigating in similar boats which is fair. The 9 month gestation period could also be a good thing in some way, seeing how AI/ML is still in a state of flux where models seem to not always be fully baked, and somewhat brittle and unreliable for now.
Yann LeCun (at Meta) recently suggested, for example, that improvements may come from replacing (or combining?) auto-regressive token prediction with planning (classical AI methods of tree- and graph-based searches, with heuristics and backtracking) as shown by Noam Brown’s (now at OpenAI) success at multiplayer Texas hold’em poker, and Diplomacy (Pluribus, and Cicero). Google’s DeepMind Gemini seems to also be moving in this direction if I understand well. This suggests (to me) that CPU oomph may become important again, beyond shoveling data into GPUs, and this could affect the architecture of future AI servers (I think).
I agree! In between French News reporting that Maroilles Lesire (AOP Gros de 750 grammes) has won “meilleur fromage du monde 2024” in Lyon, and similarly for “la bière Vandale brune” (named world’s best beer), both from Picardie, we did get a tiny news item here on Mistral AI’s new Mixtral high quality Sparse Mixture-of-Experts (MoE) LLM ( https://mistral.ai/news/mixtral-of-experts/ ).
Apparently, the MoE approach used by Mistral makes it possible to run the equivalent of Llama-2 and GPT-3.5 locally (eg. WinoGrande BBQ), on last-generation Macs for example, with openly available weights (reminds me a bit of Google’s SparseCores splitting of a large ANN into problem-specific sub-components). Advances of this type have the potential to shift part of the AI/ML computations back towards CPUs, including those for “composition” of the underlying experts, in gastronomic fashion (eh-eh-eh!).