

For most companies in most industries, riding down the Moore’s Law curve to get more compute power for the same money is good enough. But for the few dozen hyperscalers in the world, who run into a slew of scale and economic problems a decade or more ahead of the largest enterprises, services providers, and cloud builders, Moore’s Law is not good enough. Their datacenter designers and hardware and software engineers have to do better than doubling compute capacity every two years or so.
The Next Platform dropped by the Googleplex campus in Mountain View earlier this week, and Urs Hölzle, senior vice president of the Technical Infrastructure team at the company, gave some insight into the immense pressures on Google as it tries to scale out its infrastructure while at the same time doing so affordably and within a power envelope that is sustainable. And we got the distinct impression that Google would try just about anything if it thought it would help boost compute, network, or storage capacity while also reducing cost and energy consumption – including what many might consider to be a radical shift away from X86 to Power processors within its infrastructure.
Google is arguably the first commercial hyperscaler (as opposed to government agencies that were probably hyperscale before then), and the search engine and online advertising giant has been trying to outrun Moore’s Law almost from its founding. Google doesn’t show off its infrastructure very much, and it doesn’t often give out precise numbers about how many servers it has or how it has managed to improve them over time. But Hölzle yanked some old systems and motherboards that it had hanging around the lab for show and tell and also provided some data to illustrate how its most recent systems – ones that it is not showing – are doing in terms of beating Moore’s Law.
The workload that Google has to run to index the world’s web pages has grown immensely in the past seven years, and this is what drives a large portion of the compute demand inside of Google’s thirteen campuses that house its worldwide datacenters. Back in 2008, the Internet had only 1 trillion web pages, but today, said Hölzle, Google has identified over 60 trillion web pages and it has indexed the majority of them. (Hölzle did not have the precise number, and did not explain the pages that do not get indexed.) Every month, Google processes over 100 billion searches against its web indexes.
“The amount of information has really gone up a ton in a short period of time,” Hölzle explained. “One of the surprising facts is that many of these queries are stable over time, but still 15 percent of the queries that we see every day are new. It is amazing that people don’t run out of things to ask for or ways of asking.”
Hölzle has seen that growth first hand, and has gotten a few gray hairs from the explosive growth that Google sees from time to time. He showed a chart that started in December 1998, when Google was processing 50,000 queries per day and it jumped to 500,000 queries per day in only five months. This growth was the main reason that Hölzle was hired by Google founders Sergey Brin and Larry Page to take over its infrastructure back in 1999 as its first vice president of engineering. At the time, Hölzle was an associate professor of computer science at the University of California at Santa Barbara, but he was more than just a professor. His research for his PhD at Stanford University led to the development of the HotSpot Java virtual machine that Sun Microsystems acquired back in 1997 and that is still used to this day by Oracle.
“People ask me if we would switch to Power, and the answer is absolutely. Even for a single generation.”
Hölzle probably has the best job in the world as the person who leads the teams that make all of the goodies at Google that we know about – and the ones we won’t know about until many years from now when some Googlers will write yet another paper that changes the IT landscape. The list of innovations at Google is long, too long to rattle off. It includes containerized datacenters and custom servers and switches (back in 2004 for its Atlanta datacenter), which indirectly provided the inspiration for the Open Compute Project at Facebook. On the software side, Hölzle oversaw the development of MapReduce batch-style data analysis and its related Google File System (from 2001), which inspired Hadoop and HDFS and the BigTable distributed data store (from 2004) that has been mimicked in some fashion by Cassandra, MongoDB, and other NoSQL data stores. All of these technologies were driven by the need to do more compute, storage, or networking at a rate that was faster than what can be sustained by the broader IT industry.
Take switches, for example. Back in 2005, Google started building its own 10 Gb/sec Ethernet switches because it could not get what it wanted from the commercial suppliers. Back then, to get 1 TB/sec of aggregate switching bandwidth took 56 switches, but by 2012, only seven years later, Google could do that within a single one of its homemade switches. (The Google chart said TB, not Tb.)
“On the compute side, it is pretty much the same thing,” Hölzle explained. “Here is a number that we have not published before. We get over three times more compute power for the same amount of money, and actually coincidentally, for the same amount of power. So what took us a megawatt five years ago today takes us less than 300 kilowatts.”
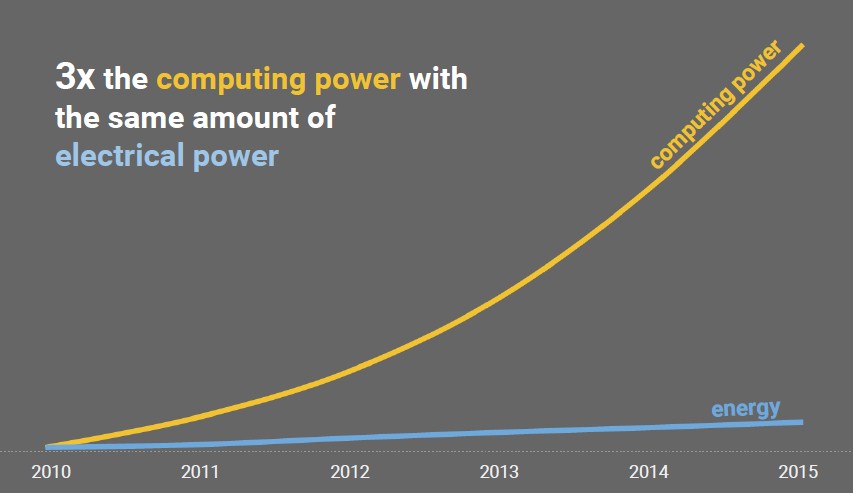
The secret is to ride Moore’s Law for the electronic components of the systems, but then to keep doing other things on top of that. “If you look at our cost or energy per query, we are doing better than Moore’s Law because we have figured out better ways to optimize compute or storage at the application level,” Hölzle explained to The Next Platform. “So that has gone down more strongly than Moore’s Law.”
Some of this improvement is accomplished by driving up the utilization on Google servers, which is done in a variety of ways such as tuning the software running on the stacks for particular workloads, adding containers to the software stack so workloads can share nodes, and doing orchestration and scheduling of workloads better across thousands of nodes. “In the IT industry it is generally accepted that 10 percent is a great number,” Hölzle said when asked about server utilization. “We have published a number of papers showing applications running at the 40 percent to 60 percent range, and we have clusters that run at the 80 percent to 90 percent range. It really depends on how much batch load you have.”
The real issue is how much of Google’s improvement in efficiency is driven by Moore’s Law and how much is from cleverness and engineering.
“What I can tell you is that in the last five years, I would say it is about even,” said Hölzle. “It is probably a little more Moore’s Law, like maybe 60-40. The way we look at this is we set a target of how much efficiency we want to gain and the industry is going to give us this much and so then how much do we have to bridge by figuring out how to do things better. And typically that was half of the gap of what our target was. And that we got in a number of different ways. For example, by driving utilization up. We published our OpenFlow WAN paper a few years ago, and one of the goals of delivering software-defined networking was to get much better utilization of our network lines. So that allowed us to have much more data safely go through the same physical network. We didn’t make the network physically more efficient but the same size network can transport more data. So it is really a combination of a myriad of things.”

While Hölzle was fine with talking about the workload explosion that preceded his coming to Google, he was understandably cagey about being too specific about what the workloads are doing now and what kinds of systems and networks the company has developed to handle them efficiently. The Next Platform asked if the efficiency improvements as noted in the chart above meant that the pressure on growing datacenters had lightened up, and Hölzle and Joe Kava, vice president of datacenter operations, and Gary Demasi, director of datacenter energy and location strategy all erupted into laughter, with Kava then saying he wished that were the case. (We suggested that actually that might be a bad thing for job security.) In the end, Hölzle said that he has basically stopped trying to predict when the explosive growth will end or start up again.
“We have our all-hands in January to kick off the year. Less than ten years ago, we were really going through this amazing growth phase, with Oregon and all of these other sites,” Hölzle explained, referring to Google’s datacenter in The Dalles on the Columbia River in Oregon, which opened in 2005 and which was the company’s first greenfield datacenter, designed from scratch for energy efficiency and to meet its own workloads and equipment. “I usually closed my presentation by saying that we were getting jaded because when you look back at what we did the prior year, it almost seems normal. But if you look at some industry comparisons, this is really insane and you might never see it again in your entire professional life. If you have thirty years in you, you will look back and think this was really unprecedented. After having to say that three years in a row, the next year I skipped it. And two years afterwards, I said it again because we had another year that was just like that. So I have kind of given up predicting that now is the time where we can coast and things are not growing so much. But we still see strong demand and an increase on pretty much all axes – servers, storage, networking. And we are really scrambling just to keep up with that.”
More Power To You
Which brings us all the way to Power-based systems, which Google has been experimenting with through the OpenPower Foundation in conjunction with IBM. The OpenPower collective has started showing off Power8-based systems and peripherals for them, as we have previously reported, and Gordon MacKean, who is chairman of the OpenPower Foundation as well as senior director in charge of server and storage systems design at Google for the past seven years, sat down with The Next Platform a month ago to talk about the potential of using Power-based machinery inside Google’s datacenters. Google has not made any commitments as far as use, but the fact that it has created a two-socket motherboard and tested its code stack on the machines speaks volumes to a market dominated by Intel Xeon processors.
We were looking over some of the vintage switch and server boards – two of the three systems were based on AMD Opteron processors, incidentally, and one was a monster board with four Opterons and sixteen memory slots – and asked Hölzle about the potential for Power8 machinery inside of Google.
“People ask me if we would switch to Power, and the answer is absolutely,” Hölzle said emphatically and unequivocally. “Even for a single generation.” And the reason is simple: A 20 percent advantage, to pick a number that he threw out, on a very large number of systems that Google deploys every year, “is a very large number. And after that, if conditions change, we might switch back.”
Google has apparently been noodling Power-based systems for a while, because Hölzle said that the company was struggling to port its homegrown Linux and application stack to Power chips until IBM switched to little endian byte ordering with the Power8 chips. “Before, we were struggling, but with Power8, within days, everything worked.”
Google tends to keep servers around for three or four years, and it plays off the depreciation of the machines against the amount of energy and space it takes to get a given amount of work done. A fully depreciated machine is free in some ways (you don’t have to buy it), and not in others. The search applications take a lot of compute but very little network, so they tend to get upgraded first. On the other end of the spectrum, YouTube requires a lot of I/O without very much compute. Google tends to have a maximum of three different system and storage server boards under development at any given time.
Hölzle said that it likes to have two different suppliers of CPUs, and that has included both Intel and AMD in the past. Now, Google is openly talking about Power8 system boards and that its code works on them, and Google generally only talks about something after it has been put into production.
Maybe there is a reason why IBM’s Power Systems business was up in the first quarter. Neither Google nor IBM will say anything about that, of course, or confirm or deny that Power machines are in production at Google.
As for future technologies that might be used in its systems, Hölzle was skeptical yet hopeful. Google was one of the early adopters of flash-based non-volatile memory, and it was so early in the SSD cycle that it had to create its own storage controller using field programmable gate arrays (FPGAs) to lash the storage to its servers. When asked about memristors, phase change memory, and other possible non-volatile storage, Hölzle said it all comes down to price/performance.
“A number of these technologies have not made it out of the labs because there is a premium compared to flash or DRAM,” he explained. “I am excited about these, but they have to happen. Even if you have something that works, you have to get it out at a price that can compete with super-optimized flash and DRAM manufacturing.”
As for GPUs, Hölzle said that they are not really appropriate for search, which required a lot of cores as well as a lot of main memory, but we would point out that Intel’s Knights Landing parallel processors with local, high-bandwidth memory on the package and external DRAM like a server might make a good compute engine for search in the future. GPUs are good, he said, for machine learning and other kinds of specialized processing, but he did not expect that Google would be switching away from CPUs any time soon for its core workloads. Ditto for FPGAs.
“They are a bit awkward because they are much harder to program than a CPU,” said Hölzle. “They work for a niche thing, and you use them in a place where you don’t have a choice.” That includes prototyping components of future systems, he added.

The Next 100X For AI Hardware Performance Will Be Harder
For those of us who like hardware and were hoping for a big reveal about the TPUv5e AI processor and surrounding system, interconnect, and software stack at the Hot Chips 2023 conference this week, the opening keynote by Jeff Dean and Amin Vahdat, the two most important techies at Google, …
The Balancing Act Of Training Generative AI
We learn a lot of lessons from the hyperscalers and HPC centers of the world, and one of them is that those who control their own software control their own fates. And that is precisely why all of the big hyperscalers, who want to sell AI services or embed them …

Missing The Moat With AI
Google is a big company with thousands of researchers and tens of thousands of software engineers, who all hold their own opinions about what AI means to the future of business and the future of their own jobs and ours. Our colleague, Dylan Patel, of SemiAnalysis, got his hands on …
Great article on showing how bold Google continues to be in defining and driving IT. They’ve helped innovate while introducing new technologies. With IBM they also show what may be perceived as old being new. IBM continues to evolve their business and technologies which is why Google leads the OpenPower Foundation, why they have tested and invested in POWER8 technology and presumably (if the authors assertion is correct) deployed their huge Linux stack running in Little Endian mode on POWER8 technology. They recognize the value and differentiation: Faster with higher utilizations leading to fewer servers running more reliably with greater flexibility. Google is always looks for the edge. Are you a leader like Google or will you remain with the herd and settle for good enough and the lack of innovation that Urs all but states is taking place with Intel.