

In a world where Moore’s Law is slowing and hardware has to be increasingly co-designed with the system software stack and the applications that run above it, the matrix of possible combinations of hardware is getting wider and deeper. This, more than anything else, shows that the era of general purpose CPU compute is coming to an end. But it also makes the job of choosing the right hardware for your specific workloads a lot harder than say two decades or even one decade ago, when a general purpose X86 server was the safest bet and nearly everyone took it, and thus we saw the rise of Intel in the datacenter.
Here in the second decade of the 21st Century, fine grained capacity sized specifically for workloads and charged for by the hour, plus specialization of compute across a wide array of CPUs, GPUs, FPGAs, and custom ASICs for running AI workloads in particular, is increasingly the rule. The public cloud is allowing companies to test out which mix of capacities and capabilities are right for them before they make big capital commitments, which is why we are seeing the proliferation of compute among the hyperscalers and the cloud builders. The need this cornucopia of compute to drive their own workloads, and they are letting us rent it out for ours. And that means we can offload the buyer’s remorse and the compute matrix to the hyperscalers that are also cloud builders.
Nothing proves this more than the announcement by Google of its new Tau instance types on the Google Cloud.
Tau, which most of you know, is the Greek symbol denoting the Golden Ratio, and as Urs Hölzle, senior vice president for technical infrastructure at Google, explains to The Next Platform, this name is meant to convey that the company is trying to get the balance of compute, memory, and I/O “just right” for specific scale-out workloads that are commonly run at the search engine and application giant and a definite contender in the public cloud race. And to be precise, the kind of workload we are talking about when Google sales “scale out” is search engine, Web serving, and other workloads like that.
The Tau t2d is the first instance in what will be a family of instances that will very likely include other processors also tuned up to deliver better bang for the buck on very specific workloads. The t2d instance is based on a single-socket implementation of the “Milan” Epyc 7003 processor from AMD, which in this case has a maximum of 60 cores activated and can be carved up into smaller bits from there. The special Milan chip has 64 cores in total, so four of those cores are being used to manage KVM hypervisor and other storage and network functions. As far as we know, Google does not have a full-on, homegrown DPU to handle this work – thus freeing up all of the cores from running the hypervisor and its I/O, as Amazon Web Services does with its homegrown “Nitro” DPU and its modified KVM hypervisor. But we strongly suspect that Google does have SmartNICs in some fashion, which can offload some storage and network functions without going all the way to the DPU. That would be why the Tau t2d instance has 60 cores out of 64 available for running real work; otherwise, as much as 30 percent of the cores on the CPU would be burned up on the hypervisor, storage, and I/O overhead.
Neither Google nor AMD are being specific about the feeds and speeds of this special Milan Epyc 7003 chip, which is annoying but expected. Eventually, the t2d will be visible when it is available on the Google Cloud, so why will Google not just tell us how it is getting 56 percent higher performance and 42 percent better price/performance with the Tau instance over Arm Graviton2 instances at Amazon Web Services and even a wider margin against “Cascade Lake” Xeon SP instances at Microsoft Azure running the SPECrate2017_int_base integer benchmark test.
Here are the performance differences that Google is seeing with its own SPEC tests:
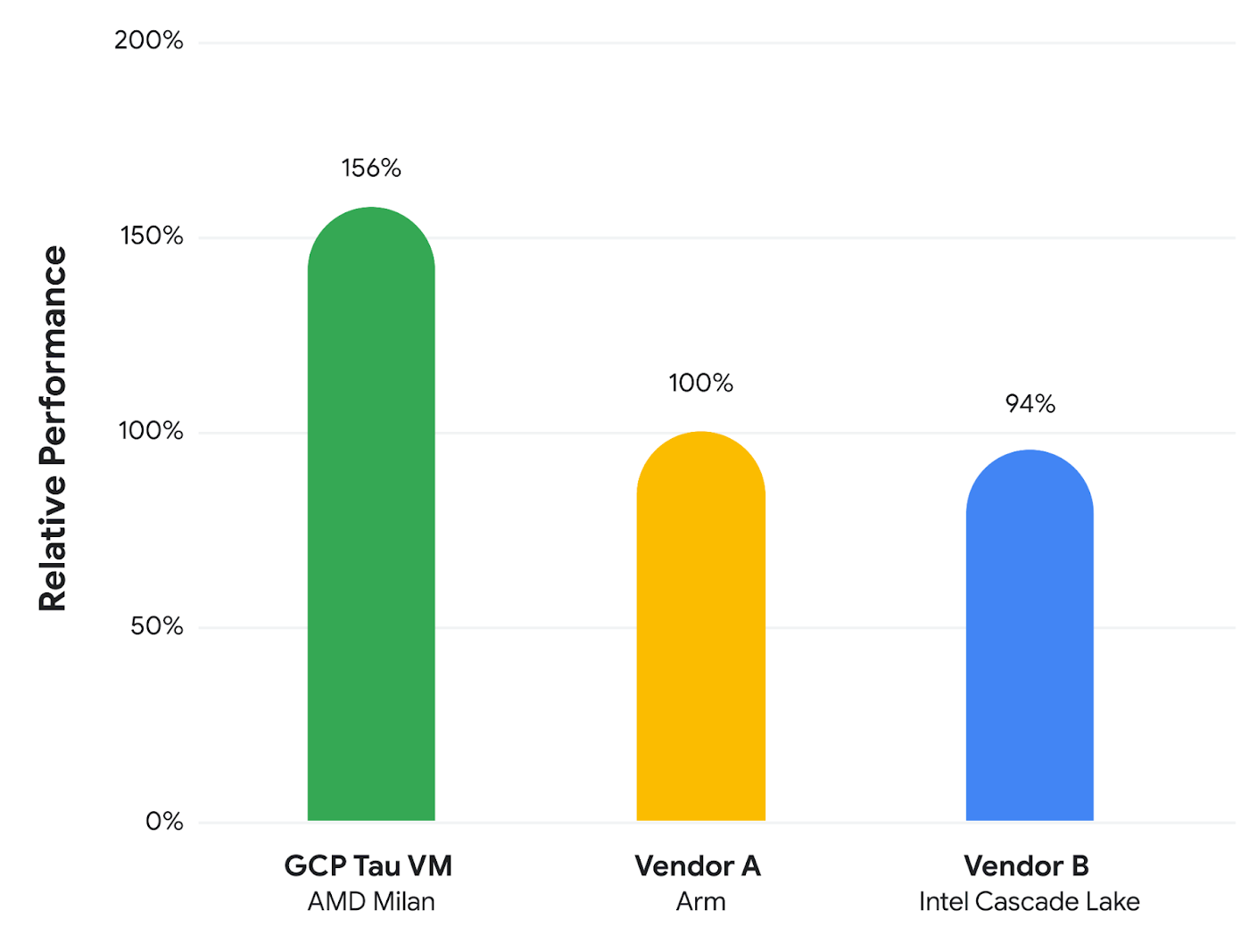 And here are the price/performance differences:
And here are the price/performance differences:
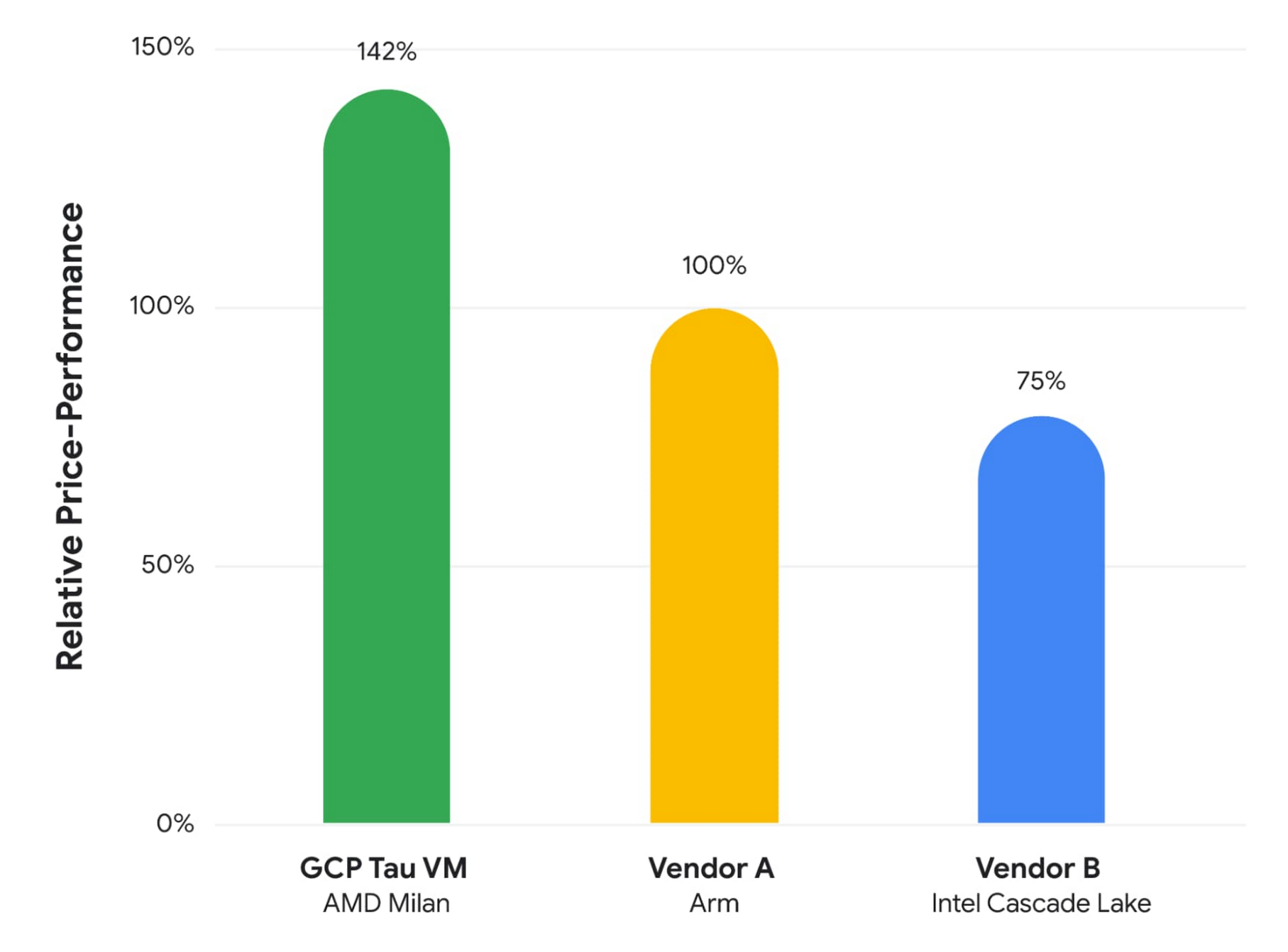
As you can see, Google has normalized this data for the Graviton2 m6g.8xlarge instance, which has 32 vCPUs and 128 GB of memory and a 12 Gb/sec link to the network; it costs $1.232 per hour on demand to rent. The Tau instance with 32 vCPUs and 128 GB of memory will cost $1.352 per hour to rent on demand, so it is a bit more expensive but makes it up with a lot higher performance. The question is what Google is paying AMD to get this 64-core Milan part for the t2d instance, and Hölzle was not going to say but he hinted strongly when he said that the way to improve price/performance was to have “more speed and less cost.”
The Microsoft Azure instance shown above, which is identified specifically in this document, was the D32s_v4 instance, which has 32 vCPUs and 128 GB of memory and 16 Gb/sec networking; it costs $1.536 per hour.
The Microsoft Azure D32s_v4 instance does not use the more recent “Ice Lake” Xeon SP, which would close the performance gap somewhat against Milan and Graviton2 and possibly the price/performance gap but maybe not depending on what Microsoft charges for them. The Azure DS_v5 instances based on Ice Lake Xeon SPs have been in public preview since late April, and a D32s_v5 instance with 32 vCPUs and 128 GB of memory costs only $0.768 per hour and would deliver somewhere around 20 percent more raw integer performance per core and about half the price. When we do that math, here is what it looks like:

It looked like Microsoft was able to get one hell of a discount on Ice Lake Xeon SPs, since we strongly suspect that Microsoft is not losing money in instances, and we got excited. But Microsoft warned in the fine print of this Ice Lake instance launch that this was special preview pricing. At that special pricing, Ice Lake is the price/performance winner here if the integer performance scales as we expect from Cascade Lake to Ice Lake. Yes, this is surprising, and no, it is not surprising why Google didn’t run its tests on the Azure Ice Lake instances, which are not yet generally available. But Google no doubt did the same math we did, and it is trying to figure out what Microsoft will need to charge to match its price/performance. The answer is: Somewhere just under $1.00 per hour. We shall see if Microsoft does the cloud instance lambada to get its nose under that broomstick.
All we know is the competition is good and it is making all of the cloud vendors compete hard for the dollar.
The AWS and Azure instances scale up to 48 and 64 vCPUs, and the wonder is why Google did not push the performance to the max to show off even more. Maybe a DPU could come in handy here?
Incidentally, that 56 percent performance increase came from using the AMD Optimizing C/C++ (AOCC) compiler, which is highly tuned to the Epyc architecture just like Intel’s compilers are highly tuned for its Xeon SP chips, and Google was completely honest when it pointed out that it only got a 25 percent performance increase over the Graviton2 when using the open source GCC 11 compilers. So half of the performance gain came from the compiler and half came from the chip, and the price came down because the Tau instance do not have maximum memory and probably other features somewhat diminished. (And hence Google can pay less for the chip and drive up bang for the buck.)
Here is how the three different VM’s stack up on the CoreMark benchmark test, which is a popular means of gauging CPU performance, and for some reason Google is only talking about price/performance here:
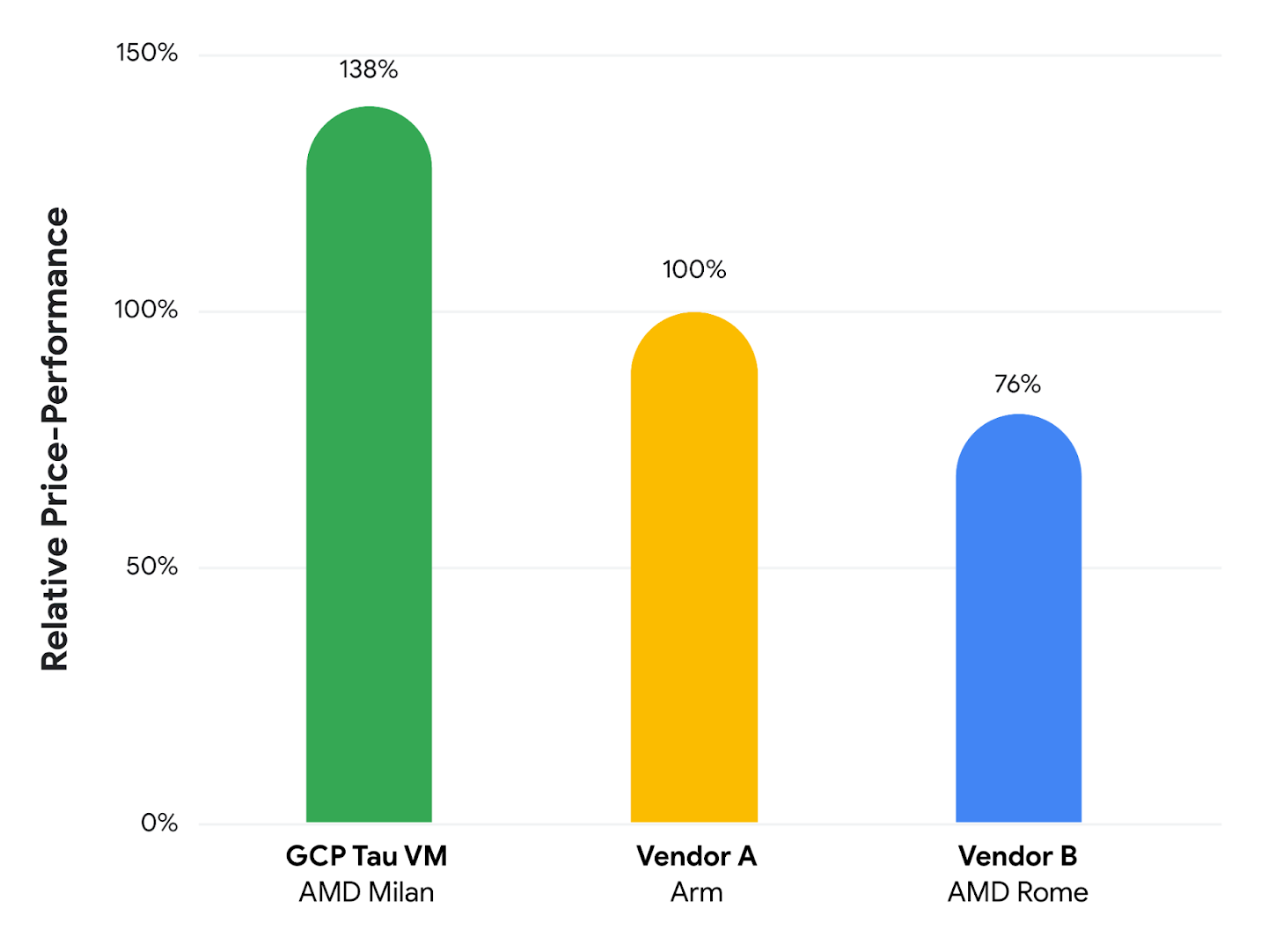
The Tau t2d instance will be available in the third quarter as an instance on Google Compute Engine (the equivalent of AWS EC2 and Microsoft Azure VM) as well as an underlying compute type on Google Kubernetes Engine, the container platform service also available on the Google Cloud public cloud.
We can expect for Google to have Tau instances based on other processors, by the way.
“For us, this is the first instance in the Tau family,” Hölzle tells The Next Platform. “We are going to continue that family with other chipsets over time, hopefully from AMD, maybe from others, and really it is to create a configuration that works very well for this kind of user. I think it is really great that we are able to produce this gap in the X86 world without compromise and without forcing customers to recompile and maybe relicense their software on a different architecture. But, you know, we do see Arm as a competitor down the road as well, and we are open to any solution that works for the customer. However, I do want to say AMD right now is clearly, as our numbers show, a step ahead in that workload category, even with Arm Graviton2 in there.”
All of the targets in the datacenter are moving all the time. It is amazing anyone hits anything. You just have to hot the target that is coming at your head, we suppose, and keep shooting.


AWS Cat Qubits Make Quantum Error Correction Effective, Affordable
In a scene from the movie Gladiator, Roman emperor Marcus Aurelius, worried about the fragility of his empire, tells his general, Maximus: “There was once a dream that was Rome. You could only whisper it. Anything more than a whisper and it would vanish.” The same could be said qubits. They are …

AMD Draws 30X Efficiency Increase Line In The Datacenter Silicon
If you don’t measure something, you can’t manage it. And if you don’t set ambitious goals, then you can’t attain them. This is why AMD in 2014 took on the task of raising the efficiency of its mobile processors with its 25X20 program, which sought to increase the power efficiency …

Key Hyperscalers And Chip Makers Gang Up On Nvidia’s NVSwitch Interconnect
The generative AI revolution is making strange bedfellows, as revolutions and emerging monopolies that capitalize on them often do. The Ultra Ethernet Consortium was formed in July 2023 to take on Nvidia’s InfiniBand high performance interconnect, which has quickly and quite profitably become the de facto standard for linking GPU …
Intel must discount to compensate for electric costs.