

Frustrated by the limitations of Ethernet, Google has taken the best ideas from InfiniBand and Cray’s “Aries” interconnect and created a new distributed switching architecture called Aquila and a new GNet protocol stack that delivers the kind of consistent and low latency that the search engine giant has been seeking for decades.
This is one of those big moments when Google does something that makes everyone in the IT industry stop and think.
The Google File System in 2003. The MapReduce analytics platform in 2004. The BigTable NoSQL database in 2006. Warehouse-scale computing as a concept in 2009. The Spanner distributed database in 2012. The Borg cluster controller in 2015 and again with the Omega scheduler add-on in 2016. The Jupiter custom datacenter switches in 2015. The Espresso edge routing software stack in 2017. The Andromeda virtual network stack in 2018. Google has never done a paper on its Colossus or GFS2 file system, the successor to GFS and the underpinning of Spanner, but it did mention it in the Spanner paper above and it did give a video presentation during the coronavirus pandemic last year about Colossus to help differentiate Google Cloud from its peers.
Two asides: Look at where the problems are. Google is moving out from data processing and the systems software that underpins it and through scheduling and into the network, both in the datacenter and at the edge, as it unveils its handiwork and technical prowess to the world.
The other interesting thing about Google now is that it is not revealing what it did years ago, as in all of those earlier papers, but what it is doing now to prepare for the future. The competition for talent in the upper echelon of computing is so intense that Google needs to do this to attract brainiacs who might otherwise go to a startup or one of its many rivals.
In any event, it has been a while since the search engine and advertising behemoth dropped a big paper on us all, but Google has done it again with a paper describing Aquila, a low-latency datacenter fabric that it has built with custom switch and interface logic and a custom protocol called GNet that provides low latency and more predictable and substantially lower tail latencies than the Ethernet-based, datacenter-wide Clos networks the company has deployed for a long time now.
Taking A Different But Similar Path
With Aquila, Google seems to have done what Intel might have been attempting to do with Omni-Path, if you squint your eyes a bit as you read the paper, which was published during the recent Network Systems Design and Implementation (NSDI) conference held by the USENIX Association. And specifically, it borrows some themes from the “Aries” proprietary interconnect created by supercomputer maker Cray and announced in the “Cascade” CX30 machines back in November 2013.
You will remember, of course, that Intel bought the Aries interconnect from Cray back in April 2012, and had plans to merge some of its technologies with its Omni-Path InfiniBand variant, which it got when it acquired that business from QLogic in January 2012. Aries had adaptive routing and a modicum of congestion control (which sometimes got flummoxed) as well as a dragonfly all-to-all topology that is distinct from the topologies of Clos networks used by the hyperscalers and cloud builders and the Hyper-X networks sometimes used by HPC centers instead of dragonfly or fat tree topologies. It is harder to add capacity to dragonfly networks without having to rewire the whole cluster, but if you are podding up machines, then it is perfectly fine. The Clos all-to-all network allows for machines to be added fairly easy, but the number of hops between machines and therefore the latency is not as consistent as with a dragonfly network.
Steve Scott, the former chief technology officer at Cray who led the design of its “SeaStar” and “Gemini” and aforementioned Aries interconnects, which were at the heart of the Cray XT3, XT4, and XC machines, joined Google back in 2013 and stayed through 2014 before rejoining Cray to lead its supercomputing resurgence with the “Rosetta” Slingshot interconnect. Scott told us that being a part of Google’s Platform Group made him really appreciate the finer points of tail latency in networks, but it looks like Scott impressed upon them the importance of proprietary protocols tuned for specific work, high radix switches over absolute peak bandwidth, the necessity of congestion control and adaptive routing that is less brittle than the stuff used by the Internet giants, and the dragonfly topology. (Scott joined Microsoft Azure as a Technical Fellow in June 2020, and it is reasonable to expect that the cloud giant is up to something relating to networks with Scott’s help.)
In short, Intel, which spent $265 million buying those networking assets from QLogic and Cray and heaven only knows how much more developing and marketing Omni-Path before selling it off to Cornelis Networks, is probably now wishing it had invented something like Aquila.
There are a lot of layers to this Aquila datacenter fabric, which is in a prototype phase right now, and it is not at all clear how this will interface and interleave with the “Mount Evans” DPU that Intel designed in conjunction with Google and that the hyperscaler is presumably already deploying in its server fleet. It could turn out that the converged switch/network device that is at the heart of the Aquila fabric and the Mount Evans DPU have a common destination on their respective roadmaps, or they drive on parallel roads until one gets a flat tire.
Starting From Scratch With Cells, Not Packets
Aquila, which is the Latin word for eagle, explicitly does not run on top of – or in spite of – the Ethernet, IP, or TCP and UDP protocols that underpin the Internet. (For a great image of the differences between these nested protocols, here is a great explanation: “Imagine one of those pneumatic tube message systems. Ethernet is the tube used to send the message, IP is an envelope in the tube, and TCP/UDP is a letter in the envelope.”
Forget all that. Google threw it all out and created what it calls a cell-based Layer 2 switching protocol and related data format that is not packets. A cell in fact, is smaller than a packet, and this is one of the reasons why Google can get better deterministic performance and lower latency for links between server nodes through the Aquila fabric. The cell format is optimized for the small units of data commonly used in RDMA networks, and with the converged network functionality of a top of rack switch ASIC and a network interface card, across the 1,152 node scale of the Aquila interconnect prototype, it can do an RMA read in an average of 4 microseconds.
This converged switch/NIC beast, the cell data format, the GNet protocol for processing it very efficiently with its own variant of RDMA called 1RMA, the out-of-band software-defined networking fabric, and the dragonfly topology create a custom, high speed interconnect that bears a passing resemblance to what would happen if Aries and InfiniBand had a lovechild in a hyperscale datacenter and that child could speak and hear Ethernet at its edges where necessary.
Let’s start with the Aquila hardware and then work our way up the stack. First off, Google did not want to spend a lot of money on this.
“To sustain the hardware development effort with a modest sized team, we chose to build a single chip with both NIC and switch functionality in the same silicon,” the 25 Google researchers who worked on Aquila explain in the paper. “Our fundamental insight and starting point was that a medium-radix switch could be incorporated into existing NIC silicon at modest additional cost and that a number of these resulting NIC/switch combinations called ToR-in-NIC (TiN) chips could be wired together via a copper backplane in a pod, an enclosure the size of a traditional Top of Rack (ToR) switch. Servers could then connect to the pod via PCIe for their NIC functionality. The TiN switch would provide connectivity to other servers in the same Clique via an optimized Layer 2 protocol, GNet, and to other servers in other Cliques via standard Ethernet.”
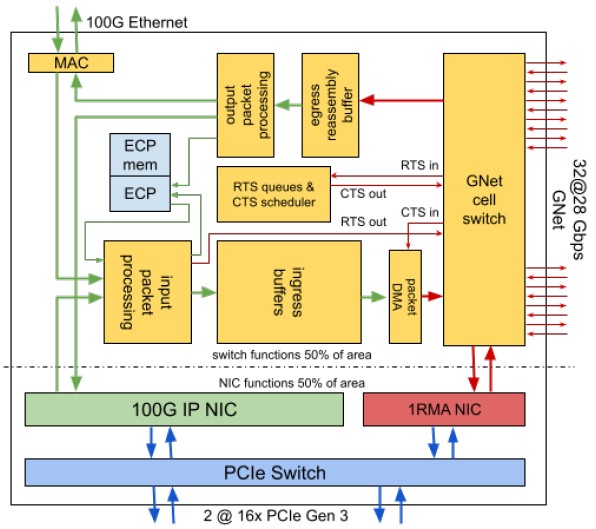
There is a lot of stuff on this “torrinic” chip. Amin Vahdat, who is the engineering fellow and vice president who runs the systems and services infrastructure team at Google and who led the network infrastructure team for a long time before that, told us this time last year that the SoC is the new motherboard and the focus of innovation, and it comes as no surprise to us that each Aquila chip is in fact a complex with two of these TiNs in the same package (but not necessarily on the same doe, mind you). Vahdat is one of the authors of the Aquila paper, and no doubt drove the development effort.
As you can see, there are a pair of PCI-Express 3.0 x16 slots coming out of the device, which allows for one fat 256 Gb/sec pipe into a single server or two 128 Gb/sec half-fat pipes for two servers. Sitting on the other side of this PCI-Express switch is a pair of network interface circuits – one that speaks 100 Gb/sec IP and can pass through the chip to speak Ethernet and another that speaks the proprietary 1RMA protocol and that hooks into the GNet cell switch.
That cell switch has 32 ports running at 28 Gb/sec – not that many ports as switches go and not that fast as ports go, as Google pointed out above. With encoding overhead taken off, these GNet cell switch lanes run at 25 Gb/sec, which is the same speed as IBM’s “Bluelink” OpenCAPI ports on the Power9 processor and as the lanes in the NVLink 3.0 pipes in the “Ampere” A100 GPU and related NVSwitch switches. There are 24 of these 25 Gb/sec lanes that are used to link all of the server nodes in pod over copper links, and there are eight links that can be used to interconnect up to 48 pods into a single GNet fabric, called a “clique,” using optical links. The Dragonfly topology used at Cray and now at Google is designed explicitly to limit the number of optical transceivers and cables need to do long-range linking of pods of servers. Google has apparently also designed its own GNet optical transceiver for these ports.
The Aquila TiN has input and output packet processing engines that can interface with the IP NIC and the Ethernet MAC if the data from the cell switch needs to leave the Aquila fabric and reach out into the Ethernet networks at Google.
Google says that the single chip design of the Aquila fabric was meant to reduce chip development costs and also to “streamline inventory management.” Anyone who has been waiting for a switch or NIC delivery during the coronavirus pandemic knows exactly what Google is talking about. The dearth of NICs is slowing down server sales for sure. It was so bad a few months ago that some HPC shops we heard about through resellers were turning to 100 Gb/sec Omni-Path gear from Intel because it was at least in stock.
The main point of this converged network architecture is that Google is nesting a very fast dragonfly network inside of its datacenter-scale Clos network, which is based on a leaf/spine topology that is not an all-to-all network but does allow for everything to be interlinked in a cost-effective and scalable fashion.
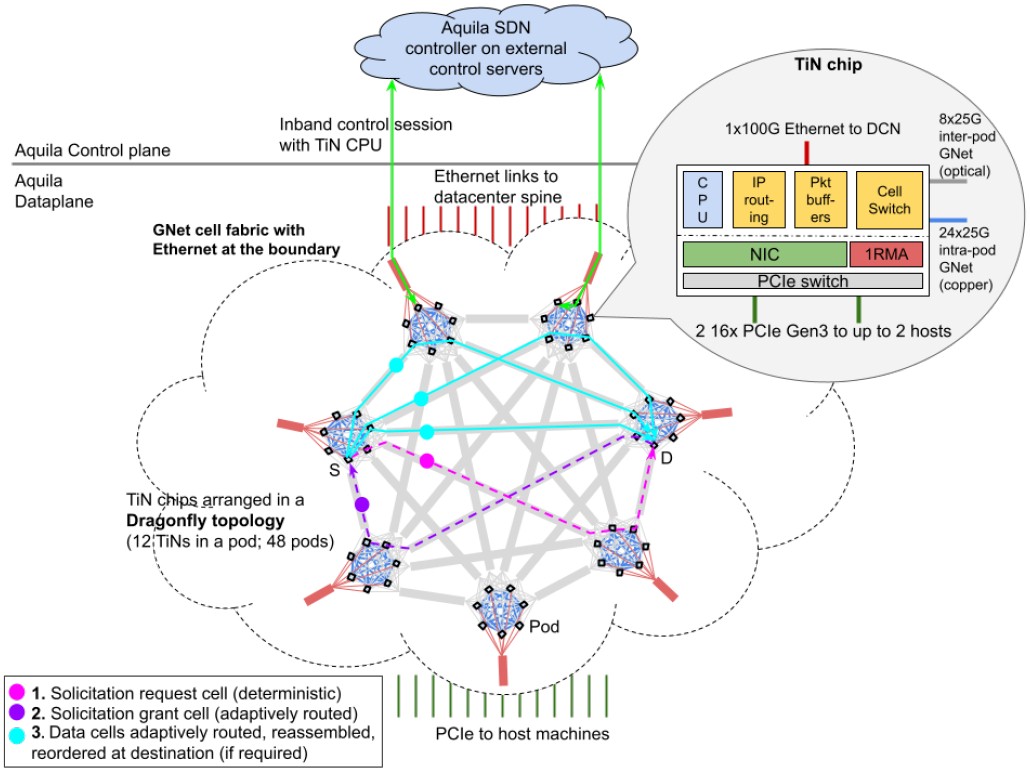
Google says that the optical links, allows for the Aquila pods to be up to 100 meters apart and impose a 30 nanosecond – Google said nanosecond – per hop latency between the interconnected pods, and that is with forward error correction reducing the noise and creating some latency.
These days, most switches have compute built in, and Google says that most switches have a multicore, 64-bit processor with somewhere between 8 GB and 16 GB of main memory of its own. But by having an external SDN controller and by using the local compute on the Aquila chip package as an endpoint local processor for each TiN pair, the Aquila package can get by with a 32-bit single-core Cortex-M7 processor with 2 MB of dedicated SRAM to handle the local processing needs of the SDN stack. The external servers running the GNet stack were not divulged, but this is a common design for Google.
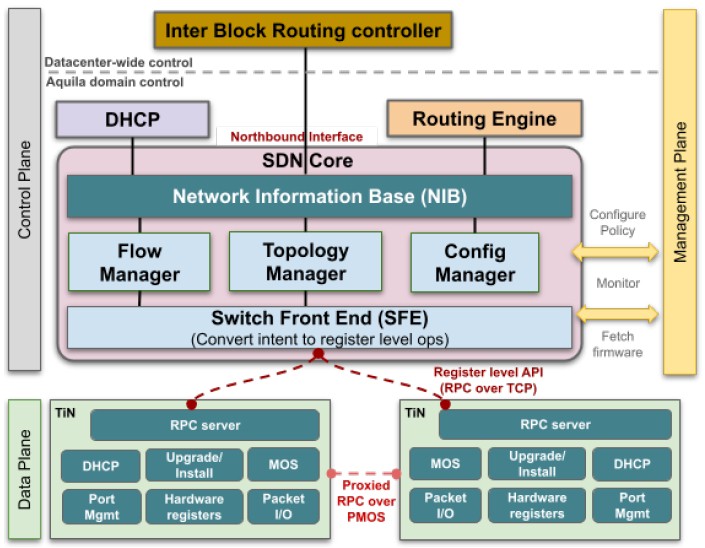
The SDN software is written in C and C++ and is comprised of around 100,000 lines of code; the Aquila chip runs the FreeRTOS real-time operating system and the lwIP library. The software exposes all of the low-level APIs up to the SDN controller, which can reach in and directly manipulate the registers and other elements of the device. Google adds that having the firmware for Aquila distributed – and most of it on the controller, and not the device – was absolutely intentional, and that the idea is that the TiN device can bring up the GNet and Ethernet links and attempt to link to the DHCP server on the network and await further configuration orders from the central Aquila SDN controller.
One interesting bit about the Aquila network is that because it is a dragonfly topology, you have to configure all of the nodes in the network from the get-go or you have to recable every time you add machines to get the full bandwidth of the network. (This is the downside of all-to-all networks.) So Google does that and then adds servers as you need them. Here is what the schematic of the servers and network look like all podded up:
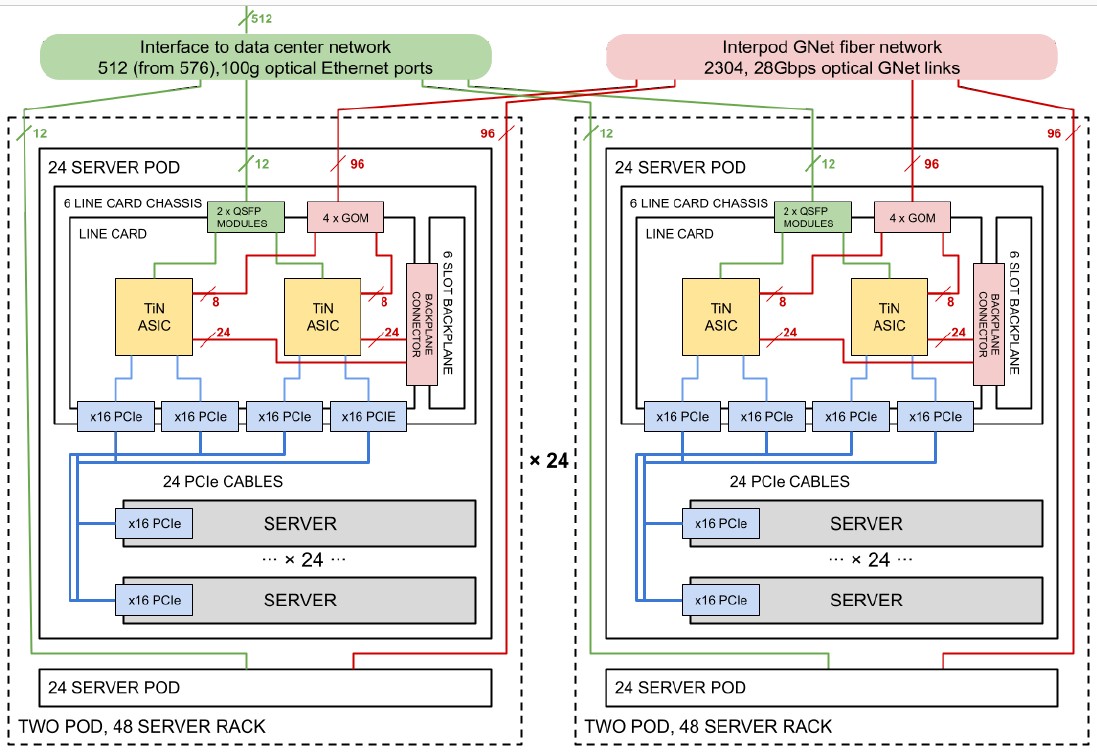
The Aquila setup has two 24-server pods in a rack and 24 racks in a clique. Google is using its standard server enclosures, which have NICs on adapter cards, in this case a PCI adapter card that links to a switch chassis that has a dozen of the T1N ASICs on six adapter cards. The first level of the dragonfly network is implemented on the chassis backplane, and there are 96 optical GNet links coming out of the pod to connect the 48 pods together, all-to-all, with two routes each.
One side effect of having many ASICs implementing the network is that the blast radius for any given ASIC is pretty small. If two servers share a T1N and the T1N package has two ASICs, then the failure of one package only knocks out four servers. If a top of rack switch in a rack of 48 servers burns up, then 48 servers are down. If a whole Aquila switch chassis fails, it is still only 24 machines that get knocked out.
Looking ahead, Google is investigating adding more compute to the TiN device in future Aquila devices, on the order of a Raspberry Pi to each NIC, so that it can run Linux. This would allow Google to add a higher-level P4 programming language abstraction layer to the network, which it most definitely wants to do.
In early tests, the Aquila fabric was able to have tail latencies of under 40 microseconds for a fabric round trip time (RTT in the network lingo), and had a remote memory access of under 10 microseconds across 500 host machines on a key-value store called CliqueMap. This tail latency is 5X smaller compared to an existing IP network, even under high load.
One last thought. The scale of the Aquila network is not all that great, and to scale the compute more will mean scaling up the T1N ASICs with more ports and possibly – but not necessarily – with higher signaling rates to increase the bandwidth to match PCI-Express 5.0 speeds. (This was a prototype, after all.) We think Google will choose higher radix over higher bandwidth, or at least split the difference.
There is another performance factor to consider, however. When Google was talking about Borg seven years ago, it had 10,000 to 50,000 servers in a pod, which is a lot. But the servers that Google was using had maybe a handful to a dozen cores per socket and probably two sockets per machine. Aim high and call it an average of 20 cores. But today, we have dozens of cores per server socket and we are on the verge of several hundred cores per socket, so it may only take a few thousand nodes to run all but the biggest jobs at Google. And even the big jobs can be chunked across Aquila pods and then aggregated over regular Ethernet links. There is a factor of 10X improvement in core count along with about a 2X factor increase in instructions per clock (IPC) for integer work over that time; floating point performance has gone up by even more. Call it a 20X factor of improvement in performance per node. For all we know, the pod sizes at Google don’t need to be stretched all that far.
More importantly, (O)1000 clusters, as technical papers abbreviate clusters on the order of thousands of nodes, are big enough to do important HPC and AI workloads, even if they cannot run the largest models. It will be interesting to see what jobs fit into an Aquila fabric and what ones do not, and interestingly, this technology might be perfect for the scale of many startups, enterprises, academic, and government enterprises. So even if Aquila doesn’t scale far now, it could be the foundation of a very high performance HPC and AI service on Google cloud where (O)1000 is just right.


Google Joins The Homegrown Arm Server CPU Club
If you are wondering why Intel chief executive officer Pat Gelsinger has been working so hard to get the company’s foundry business not only back on track but utterly transformed into a merchant foundry that, by 2030 or so can take away some business from archrival Taiwan Semiconductor Manufacturing Co, …

Datacenter Infrastructure Report Card, Q3 2023
It is hard to keep a model of datacenter infrastructure spending in your head at the same time you want to look at trends in cloud and on-premises spending as well as keep score among the key IT suppliers to figure out who is winning and who is losing. And …

Anthropic Fires Off Performance And Price Salvos In AI War
It is a strange time in the generative AI revolution, with things changing on so many vectors so quickly it is hard to figure out what all of this hardware and software and people-hours costs and what it might be worth when it comes to transforming, well, just about everything. …
ATM switches of the 1990’s and 2000’s had cells. Faster Ethernet made them obsolete. Also ATM
switches were expensive. How does Aquila avoid the fate of ATM switches?
Cell based ? ATM ?