

There are some features in any architecture that are essential, foundational, and non-negotiable. Right up to the moment that some clever architect shows us that this is not so. What is true of buildings and bridges is equally true of systems and their processors, which is why we use the same word to describe the people who design this macroscopic and microscopic structures.
Peter Foley, who is the co-founder and chief executive officer at Ascenium, a startup that just uncloaked after raising $16 million in its Series A venture capital funding, is one such architect. And Foley and the team at Ascenium want to throw away a lot of the architecture in the modern CPU and start from scratch to create what Foley calls the software-defined, continuously reconfigurable processor. And the reason why Foley says tearing down the processor and building it in a new and different way is necessary is because we have run out of tricks with the current architecture of the CPU.
Some history of Foley is probably in order before we dive into the conversation that we had with him on the architecture of the forthcoming Aptos processor under development at Ascenium and how it will shake up the CPU market. Foley has covered a lot of ground and seen a lot of things that has brought him to this point.
Foley got his bachelors in electrical engineering at Rice University and a masters at the University of California at Berkeley. While at Berkeley, Foley worked on the Smalltalk on a RISC (SOAR) chip project with David Patterson and Alvin Despain. After graduating, Foley joined Apple, working on various chips for the Mac and Mac II personal computers, and was then tapped by Apple in 1987 to be one of the four original members of the ahead-of-its-time Newton personal digital assistant, which was really a dry run for the iPad but no one knew that at the time. In particular, Foley was put in charge of the development of the “Hobbit” processor used in the Newton. He left Apple to join SuperMac, a third party GPU supplier, and then when to Chromatic Research to work on its programmable VLIW and SIMD media processing accelerator. Foley did a stint as an entrepreneur in residence at Benchmark Capital and then founded nBand Communications and created a software-defined broadband wireless radio (something akin to the WiMAX we should have had instead of 5G, which really is more like 4.1G in most places, let’s be honest). He then did a nearly four year stint as vice president of engineering at Predicant Biosciences, which created diagnostic devices to scan for cancer in blood proteins, and then had a nearly four year stint at Tallwood Venture Capital as an executive in residence.
Significantly, in December 2009, after all that and seeing the accelerated computing writing on the wall, Foley was founder and CEO at AI chip startup Wave Computing, and importantly, Foley left the company years before it did its complex deals to license its technology in China, before it bought the MIPS chip technology that had been passed around for more than a decade after Silicon Graphics spun it out, and before it had to file for Chapter 11 bankruptcy reorganization in April 2020. And to be precise, Foley left Wave Computing in June 2016, and ran his own consulting business until joining Ascenium, which was founded in March 2018, as its CEO in June 2019. Importantly, Ascenium got its $9 million angel funding round and its $16 million Series A funding round from Stavanger Ventures AS, a venture capital firm run by Espen Fjogstad, a Norwegian serial entrepreneur who has sold companies to eBay and Google as well as taken several public on the Oslo Stock Exchange; several did reservoir modeling, which probably came in handy during the North Sea oil boom that breathed new life into the economies of the United Kingdom and Norway starting in the late 1970s. (Oil got expensive enough and technology advanced far enough that it was economical to drill it offshore.)
As far as we know, Ascenium was founded at least prior to 2005, when Robert Mykland, its founder and chief technology officer, gave a presentation at the Hot Chips conference (PDF). The company has been granted nine patents, which are useful in a litigious semiconductor space. The current incarnation of Ascenium was founded in June 2019 to leverage and extend that research by Foley, Oyvind Harboe, and Tore Bastiansen.
Just like the Newton was ahead of its time and Moore’s Law had to let chips and networks catch up before we could have a PDA, perhaps we had to get to the end of Moore’s Law before we could even consider the ideas that Mykland espoused more than 16 years ago.
With that out of the way, we had a chat with Foley about what Ascenium was up to with a processor that doesn’t have an instruction set as we know it and seeks to redefine the interface between software compilers and the underlying hardware with its Aptos processor, which is a programmable array of 64-bit computational elements. Here’s a block diagram of sorts to get a feel for it, but this is admittedly a little vague because Ascenium is a bit secretive at the moment:

With all of that in mind, here is our chat with Foley.
Timothy Prickett Morgan: I thought I saw that this was an instruction set architecture-free processor. And I read that twice, shook my head, and thought, “What in the hell is that?” So you have got my attention now.
Peter Foley: We see what my ex-boss, Dado Banatao from Tallwood, used to call a large, sleepy market that is ripe for innovation. And so our mission is to enter that big market with something that’s completely different.
And the reason we think it needs to be completely different is if you try to play by the same set of rules in the same sandbox, which is basically an instruction set architecture approach where you have serial streams of instructions that go into an out-of-order issue machine with very deep pipelines – you know the whole shebang, I won’t get into all of the details – but if you play by that set of rules, you can’t win in. Look at all the Arm roadkill along the way: Calxeda, Cavium, Broadcom, blah, blah, blah.
TPM: There’s a lot of roadkill, billions of dollars of roadkill.
Peter Foley: And Qualcomm has tried to do it twice and I think they’re still at it. It’s very tough. It’s very tough to beat Intel on single core, single threaded SPECint, which is really what people care about.
TPM: AMD is doing it this week.
Peter Foley: Yeah, but they are still X86, and they have a license. And yes, they’re actually sort of beating Intel right now, but a lot of it has to do with Intel’s screwup on the fabs and AMD using TSMC so they have a node advantage for a while.
TPM: I wrote a story recently, which has not yet been published, saying the best thing that ever happened to AMD is GlobalFoundries screwed up 14 nanometer, but IBM sold them Microelectronics which helped, and then 10 nanometer was really messed up.
Peter Foley: That’s exactly right.
TPM: Because after that, AMD had to jump to 7 nanometer on TSMC at exactly the same time Intel was having big issues with 10 nanometer. AMD could always design a good chip, but those foundry factors at Intel made them so relevant.
Peter Foley: You’re exactly right. All the other stuff is sort of second order: slight tweaks to the architecture, dump in a few billion more transistors. Moore’s Law and Dennard scaling are not cooperating, though, and because these architectures are so incredibly complex, they have to dump in a few billion transistors to get another 5 percent or 10 percent or 20 percent or whatever. And the problem with that is now it gets too hot and you either have to turn down the clock or you have to shut off part of the die – and then you have a dark silicon problem.
TPM: I have been saying turn down the clocks and get memory and CPU back into something close to phase because you’re just spinning the clock to wait most of the time anyway. So you might as well just go slower and not wait. We have to parallelize our code anyway to run on a GPU, so make the CPU look like a GPU and boost its throughput that way.
Peter Foley: Nvidia had that problem with Ampere GPUs. They came in too hot, at 400 watts even with a slower clock, and that meant Ampere couldn’t go on PCI boards without redesigning it fit into a 300 watt PCI-Express form factor.
TPM: So, that sets the stage for what Ascenium is trying to do, I think.
Peter Foley: What we are doing is going to be really different. And the idea is let’s redefine the partitioning between the compiler and the hardware, which was established fifty years ago with the ISA for IBM mainframes and then RISC machines.
Back then, you had like a three stage or a five stage pipeline and the compiler couldn’t do much because you didn’t have much horsepower. And this seemed like a good division of labor. And the problem is that that that particular API partitioning has gotten really stale and doesn’t really work 50 years later with the advancements in compute horsepower and the problems that, as I mentioned with Dennard scaling and just dumping transistors into an out-of-order architecture. It’s time for a fresh rethink and just dump everything associated with the ISA: deep pipelines, out of order, reordering, renaming, forwarding, runtime branch prediction. Just get rid of all of it.
TPM: What the hell is left? Everything I understand – everything I think I understand – is in that list.
Peter Foley: There are some key enablers here, right? One is that there’s an incredible amount of horsepower available now to the compiler. So you could have more complex compilers do much more work because there’s just the horsepower to do it.
Another enabler is if you are going to go to an array-based approach that is controlled at a very, very fine grain by the compiler directly, kind of like a giant microcode word if you will, into this array-based machine, then your typical compilers are one dimensional. You spit out a serial stream of instructions and then you throw everything over the wall to the hardware. Hardware has to extract all the parallelism, do everything. We say let the compiler do a ton more work, have a much bigger, broader view of the whole program and do much more sophisticated optimizations. And now the compiler is a 5D compiler. It’s got to do 2D placement, it’s got to do 2D routing, it’s got to do scheduling. And so that’s a whole lot more work.
And because our market is the datacenter, we can recompile stuff all the time because you could spend 15 minutes to a half hour compiling something and then run it 10 million times in the datacenter and reap the power rewards. That calculus has changed, too, in terms of the total focus on power. So it’s worth to see if you can spend more time up front with a really super-sophisticated, complicated compiling 2D computational array that’s directly controlled by the compiler with a giant microcode word, it’s worth it if you can save even 5 percent or 10 percent of the power. The hyperscalers will bend over backwards to get you into their datacenters if you can do that.
There is one other key enabler for Ascenium’s Aptos processor and our approach, and I’ve been down this path and that’s something I brought to this company. I learned this and I thought it could really make a difference to what Ascenium was doing. There’s a company called Tabula that had a similar problem and they had real problems getting the software work and they didn’t get it to work until the end after their second or third try because they finally brought in a constraint solver. Tabula used a SAT solver based approach to do the compiling backend. And we did the same thing at Wave Computing. And then I brought that technology here to Ascenium.
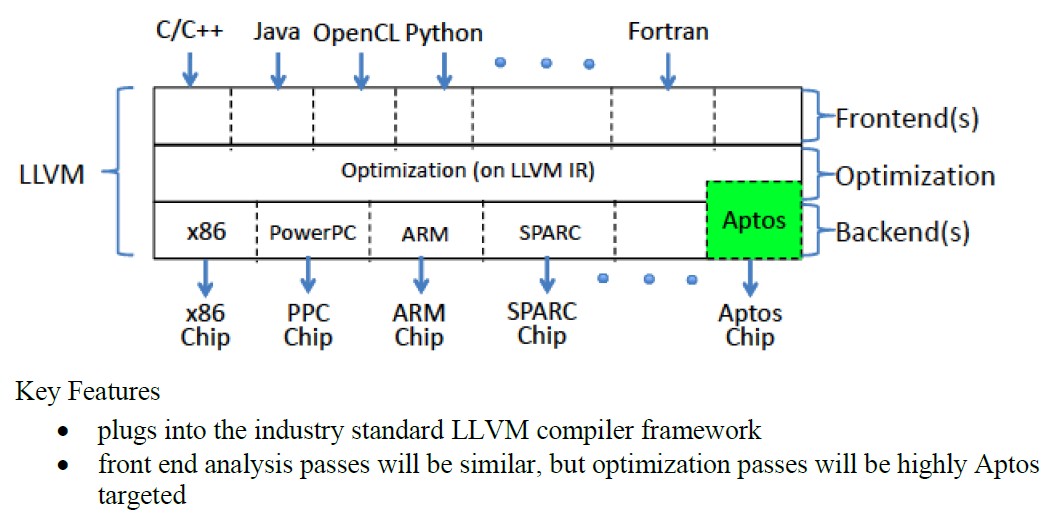
We have a standard LLVM compiler infrastructure but a new LLVM backend targeting our hardware that is heavily oriented on constraint solvers. And so it’s like a black box. If you have a really simple regular architecture where you can completely describe the behavior, both temporally and physically, in a set of logical equations, then our SAT solver can digest it and give mathematically provable optimum results. This is tough to beat. You could never use a constraint solver on a complex, heterogeneous, out-of-order architecture. Forget it. You would be wasting your time. But this could work.
The mathematically provable optimum results for an SAT solver approach is an overreach when talking about an entire program. It’s mathematically provably optimum for chunks of code – but computationally intractable for whole programs. So then those chunks have to be stitched together. Hence the SAT solver windows across the code, stitching the compiled windows together – and there is some loss of efficiency there. So part of the secret sauce then, the company know-how, is knowing how to optimally partition, compile, and stitch together the SAT compiled chunks of the program.
The idea is make the chip architecture as simple as possible. Throw it at a SAT solver, which generates these really amazingly optimum 5D solutions and then go from there. And that’s the bet: Get outside the X86 and Arm sandbox, and importantly, have an IP clean approach. Because that’s the other problem: If you try to go up against these CPU guys, you’re going to run up against an enormous IP wall. As soon as you start actually being a threat, they’re going to sue you. Period. It’s just business, right?
TPM: So this is kind of RISC taken to an extreme?
Peter Foley: Exactly. And, you know, I come from that world. I worked with David Patterson on the Smalltalk on a chip research team at Berkeley way back when. I have been doing processers my whole career, on and off, and almost all of them are RISC-based.
TPM: I guess this is really NISC, then: No Instruction Set Computing.
Peter Foley: [Laughter.] Right!
But seriously, constraint solvers are really a hot thing now. They’re taking over the EDA industry. And in essence, what we’re doing is really more of an EDA problem than a classic compilation problem. It’s kind of like a complete Xilinx or Altera FPGA backend rolled into a compiler because they do many of the same sorts of things with placement and routing and scheduling and everything into the FPGA lookup table fabric. We’re doing something very similar but targeting a truly general-purpose compute engine. Constraint solvers are being applied elsewhere, but this is the first application I’ve ever seen to general-purpose computing. And we’re working hard to stake out a first mover advantage in terms of IP claims and patents and all that good stuff.
TPM: So are you somewhere like halfway between an FPGA dataflow engine and a CPU, is that the way we think about it?
Peter Foley: Yes, I think that’s fair. Although we are a general purpose processor. We’re not emulating hardware the way an FPGA does with a lookup table fabric.
And here’s another interesting thing that is relevant. If you look at an X86 instruction stream, I think at least 50 percent, if not more, of the instructions are move instructions all related to data movement. I think only 20 percent of the instructions in an actual X86 instruction stream do work: add or subtract or multiply or whatever. Well, in our world, everything is all controlled by the compiler intimately in the same control words. So data movement, computation, direction, routing – everything is all controlled by the compiler at the same time in the same instruction control word that goes into the array. So there’s no sort of serialization, there’s sort of no Amdahl’s law penalty in terms of instructions streaming into the architecture that just do moves. It’s all done at the same time by the compiler.
The compiler has to keep track of a lot of stuff, to be fair. But also to be fair, in a classic out-of-order machine, there’s all kinds of renaming that goes on, very complex stuff. And there are all these resources in the array to effectively implement an extremely large distributed renaming capability. So we have this distributed memory that we leverage and we do a lot of reuse so there’s not as much traffic to a classical register file. So that’s all eliminated. We have virtually no pipeline, so the branch shadow is extremely short. It really is different.
TPM: OK, so it’s like Hewlett-Packard cons Intel into doing EPIC, and kind of grafting it onto something that smells like an X86 but not enough and we end up with Itanium. And here you are, throwing away everything that Intel and HP did and only keeping the Explicitly Parallel Instruction Computing part. . . . [Laughter]
Peter Foley: So I’ll head your next question off at the pass. So how real is it?
TPM: Not exactly. You have to understand. Nicole and I make jokes here at The Next Platform about all of the AI startups, who have elegant hardware and then they start talking about bringing in the magic compiler. There’s always this and “then a magic compiler makes it all work right.” And you, you just described the most magical of compilers I have ever heard about.
Peter Foley: [Laughter].
TPM: So, you know, if I sound skeptical, I’m probably not understanding. . . . Or maybe I am.
Peter Foley: One of the reasons our investors ponied up the Series A and got the company moving into the next stage is that we’ve demonstrated being able to compile 700,000 lines of code between five and ten minutes and run it on an FPGA prototype. And so that’s one of the neat things about this architecture. It’s simple enough that you can actually prototype it on the FPGA.
TPM: Let’s be precise in our language here. This was not a set of four boards with eight FPGAs on each board, of the most expensive type, linked together to emulate one small chip?
Peter Foley: Oh, no, no. This is not a Paladium. No, this is one midrange FPGA board. We couldn’t afford anything more.
We can run 700,000 lines of code, which includes standard C libraries used in SPEC, and we compile that and run that on our FPGA testbed, which is not the full architecture, but a big chunk of it, and get functionally correct results. We have a full symbolic debugger and other infrastructure to actually make something like that work.
TPM: What is this thing going to look like when it’s a product, and how are you going to pitch it?
Peter Foley: We’re trying to win on the two most important metrics. One is SPECint performance, and people use instructions per clock as a kind of a proxy for that. It’s not a great proxy. But we have a metric that’s an X86 equivalent instructions worth of work performed in every one of our control words. Our goal, in terms of the compiler quality of results and improvements, is to move that bar in terms of our IPCW, instructions per control word, our IPC equivalent. That’s super-important for the hyperscaler guys,
TPM: That’s table stakes.
Peter Foley: The other is power. So the idea is to win on both metrics and have a really compelling kind of slam dunk story. And the thing about the power there is we just get rid of all the transistors.
TPM: So you look at how many transistors does it take to get something done, right?
Peter Foley: Considerably less. Let’s just say a ton less than X86.
TPM: Is it an order of magnitude or a factor of three? I mean, what are we talking about?
Peter Foley: It’s probably an order of magnitude, but I don’t you know, that’s just a swag. I don’t have detailed numbers yet. That’s what this money is going to go for. We’re going to flesh out and finalize the microarchitecture and actually build some trial silicon and get ahold of the 5 nanometer tools or whatever we need, and go build this thing and lay it out.
That’s part of the job of building a processor, dealing with all of these geometries. It’s all about spatial delays and the tyranny of distance. Layout determines so many factors that bleed back into your microarchitecture. So we need to go make sure that we address those and take care of all that. And once we start getting deeper into that, we’ll be able to give the kind of numbers that you’re looking for in much higher confidence.
TPM: The goal, then, if I can sum up the Aptos architecture, is to lower the watts and increase the performance – but you don’t have to drop the price.
Peter Foley: That’s correct. And we don’t have to pay Arm.




This reminds me a bit of the Thinking Machine architecture. The biggest problem with that architecture was non-neighbor communication which became the bottleneck for most applications. The extension that makes this architecture programmable really appeals to me. The single instruction per single clock cycle brings me back to the RCA 1800 architecture which it’s single instruction per 8 clock cycle architecture. You could do things like UARTs in software without timers by figuring out the right number of instructions to execute per 0 or 1 window. I will definitely be watching how this pans out.
Trying to rely too much on the compiler is exactly how Itanium failed. And it had very serious people, and clever people, supporting it…
Itanium had very compiler-unfriendly restrictions, like instruction paring. On top of this there were many not well documented issues, for example, load-store aliasing ignored low bits and as a result an invisible to compiler D$ invalidation and the load re-issue… Too many problems with HW to fix them in compiler.
This satirical article is hilarious. I haven’t seen such a spot-on spoof of the worst kinds of over-eager tech optimism in years. From the tech resume that lists all the failed products of the CEO to the miniscule power improvements, the “architecture slide” that’s impressively vague. Really well done. I can see why you couldn’t wait for April next year once you’d had the idea.
Haven’t we heard this story before: let’s solve hardware problems by making them software problems; Original RISC (Microprocessor without interlocking pipeline stages, aka MIPS, branch delay slots, load delay slots, s/w managed TLBs), VLIW, EPIC/Itanium (ALATs are great), Transmeta, Denver… the graveyard of those who believed in the magic compiler to come and save the day is a big one.
The idea as described is a lot like MIT RAW that begat Tilera. i.e. nothing new here. What’s tilera up to these days? Right.
And then, Real CPUs have to take exceptions, do I/O etc. Architectures with precise exceptions (i.e. CPUs) are the norm because they help debugability and provide a clean interface to s/w.
This is an accelerator that may be an add-on card over PCIe like a GPU. There may be a market for that but the GPU has a far more mature software stack to take advantage of this.
Also, this exchange is ridiculous
“It’s very tough. It’s very tough to beat Intel on single core, single threaded SPECint, ”
“AMD is doing it this week.”
“but a lot of it has to do with Intel’s screwup on the fabs and AMD using TSMC so they have a node advantage for a while.”
So, process is all that matters? In which case it should be easy enough now for literally anyone to beat intel at ST perf. So why isn’t there anyone apart from AMD?
There are some…
The new Apple bionic chip.
Heck, even some older design ARM 70 series cpus beat Intel’s fastest, at half the frequency, in *SOME* workloads.
Intel is just software optimizes for a lot of tasks.
But there still are a lot of tasks, when optimized for ARM, will vastleggen outperform Intel (in specific lots of memory intensive tasks, but also lots of smaller tasks, that are repetitive tasks, like done on a GPU.
reminds me Itanium and of Transmeta and their VLIW chip that was relying on compiler to optimise the program.
Transmeta also had this “embedded software layer” that was able to translate x86 code on-the-fly: maybe we will finally see something similar again 🙂
All good and well, but without any optimizations, how will you process data on a fixed bandwidth, when multiple cores are trying to get data from, say, the memory, which operates at the same frequency?
You’re still going to have threads that are passive, until their data is loaded.
So now you’ll have to speed up the memory to twice the cpu speed, just to be able to feed 2 processors, wanting to read/write data to the same memory block (even if the modified values aren’t overwriting one another’s).
Your comments about a fixed clock for all hardware all sounds good in theory, but practice is a different thing.
Why not follow Nvidia, in making a cpu matrix? Instead of X – amount of cpu cores, why not an array of X by Y processing cores?
Nvidia uses this in their Ray tracing matrices, which are 8bit processors, and they’re working on 4 bit for AI. (Just have more software loops of 4bit data strings process, instead of less loops of 8bit strings. Then just add more 4 bit processors on the hardware, for a higher parallel processing count, as 8x4bit cpus cost exactly the same space as 4x8bit cpus, only now you won’t have to deal with partial cpu pipeline utilization when a smaller command enters a larger pipeline).
All a cpu needs is this at fpp (64 bit). Or, if you can implement modern features at 32 or 16 bit, would even be better!
Though I’d have to say that more loops of data, means more ram, means 16 and/or 32 bit is out of the question, and the cpu needs to be running at 48 to 64 bit.
Itanium and other static-scheduled architectures fail because there’s no amount of compiler smarts that can compensate for the variable, unpredictable latencies of things like cache misses (and therefore load latency). There’s just no substitute for dynamic scheduling in some of these cases. Relying on compilers for many optimization categories, and it’s even possible that compilers can do much more than they do now. But, they cannot predict the future. Maybe quantum computers can fill this gap. 🙂