
While the hyperscalers have been running AI workloads against vast datasets in production for a decade and a half, many large enterprises have lots of data they think is relevant but they are not at all experiences with AI and the system requirements it has.
That’s where companies like Hewlett Packard Enterprise can step in and help out and also make a little money, too.
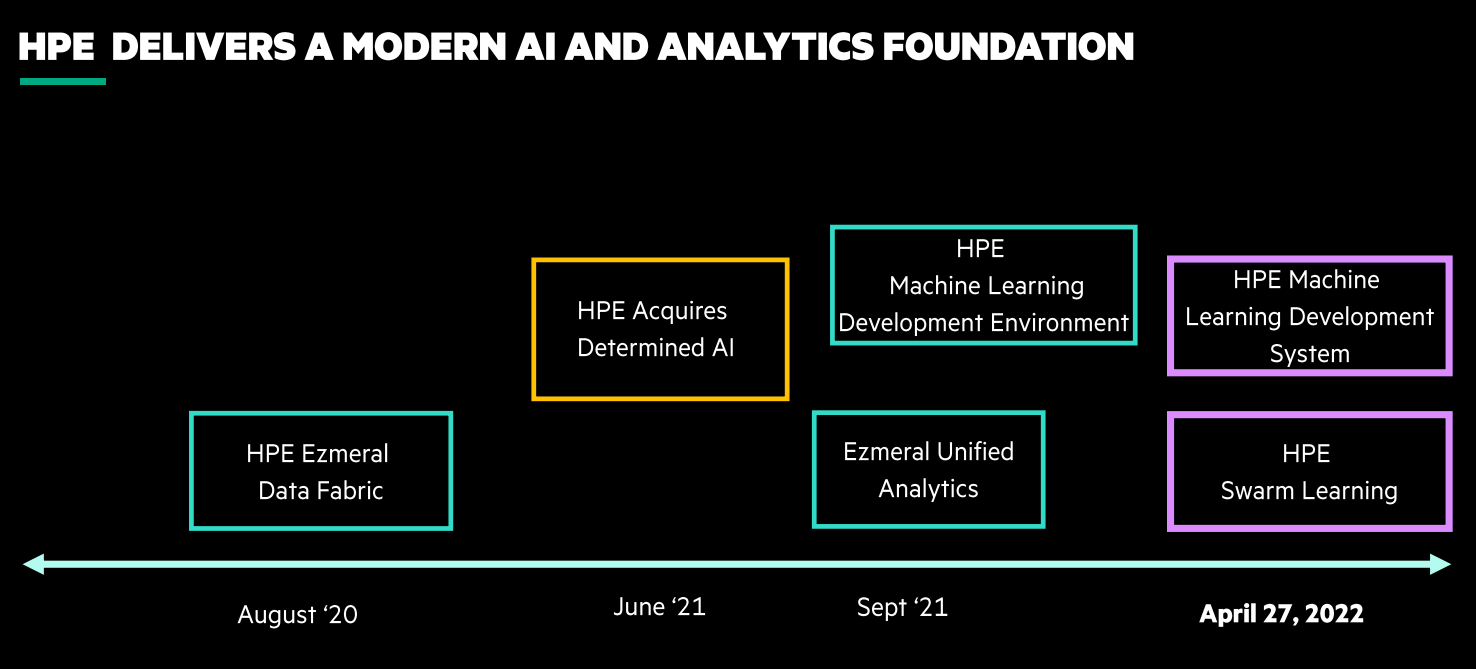
HPE has been banging its “AI for all” message for the past few years, echoing the “democratization of HPC” initiatives that the major OEMs have been touting for decades. But for HPE, this is more than talk. Last year, HPE bought startup Determined AI and its software platform for training machine learning models at scale, which takes advantage of the HPC-level capabilities that HPE has in its arsenal. Two months later, the company launched the Machine Learning Development Environment – its own machine learning training platform – and the companion Unified Analytics offering in its Ezmeral software portfolio.
HPE this week is expanding its AI software portfolio but is also leaning on its HPC hardware background – which was bolstered greatly with its $1.4 billion acquisition of supercomputer maker Cray in 2019 – by aiming to essentially take it out of the equation that enterprises calculate with when running such workloads.
“What we found with our work through the acquisition of Determined AI and with many customers is many engineers spend their time managing infrastructure,” Justin Hotard, executive vice president and general manager of HPE’s HPC and AI business, told journalists in a recent virtual meeting. “They’re dealing with a lot of the technical intricacies of the infrastructure as opposed to focusing on optimizing their models and refining them at scale. The other key thing as you go into large-scale models, which is really the core of the HPC and AI business unit, is delivering large-scale models in traditional and HPC and now in AI. Much like we see in HPC, customers need specialized infrastructure. Further, there’s been a massive explosion in companies developing accelerators and looking for different levels of optimization and that actually makes it harder on the individual data scientists and engineers because that drives complexity as they’re working through their solutions.”
The market is crowded with “specific and rigid” offerings that are expensive and difficult to scale, which drives complexity and the time it takes to get insights from the data, Hotard said. What HPE is trying to simplify the hardware situation and make it easier to collaborate across organizations to train their models.
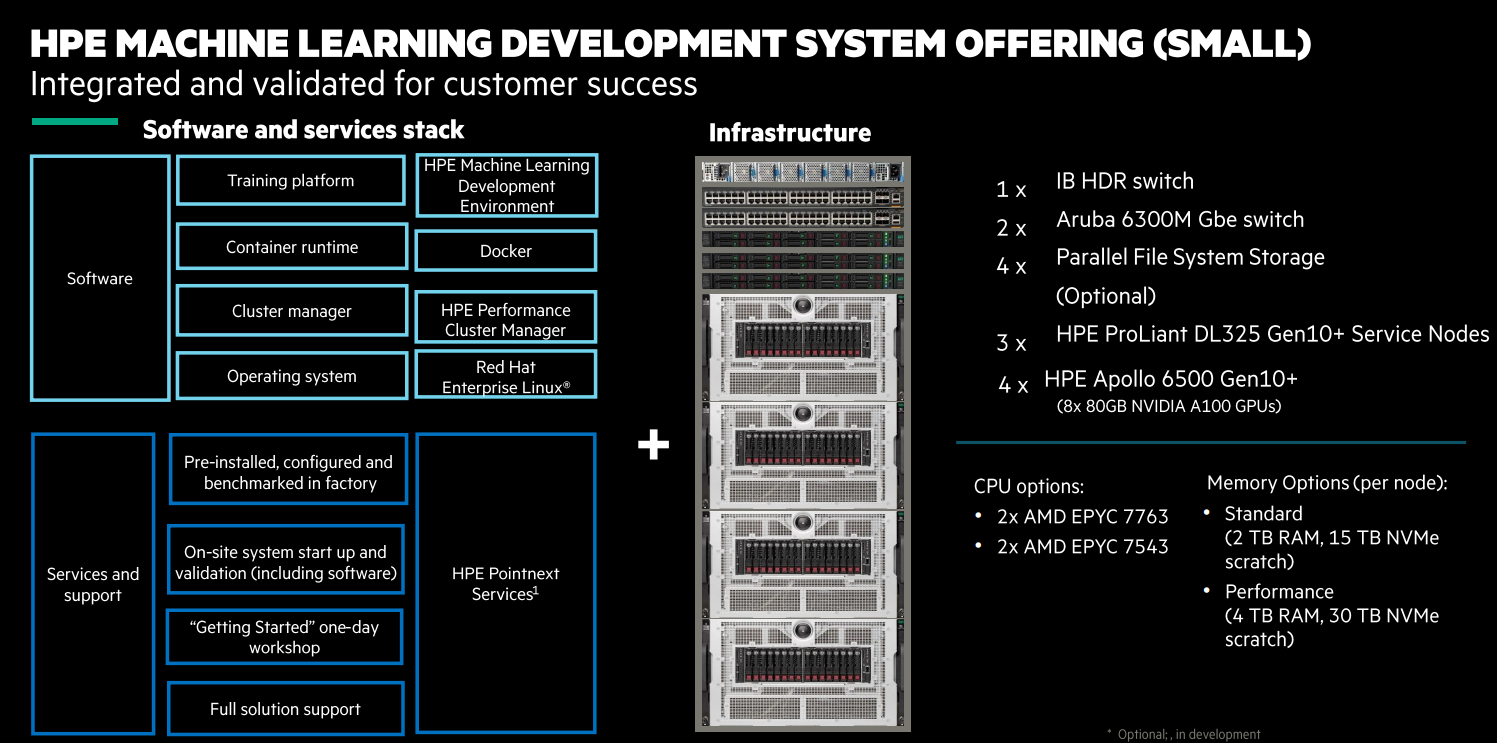
The vendor’s Machine Learning Development System brings together accelerated hardware and software that together can enabled model training at scale. The hardware can scale from 32 GPU accelerators to 256 GPUs and leverages HPE’s highly dense Apollo systems that include eight 80 GB Nvidia A100 GPUs and ProLiant DL325 Gen10+ nodes that are powered by AMD “Milan Epyc 7763 or 7543 chips. It also including the 6300M 1 Gb/sec switch from Aruba Networks (owned by HPE), a 200 Gb/sec InfiniBand HDR switch, and an optional HPE Parallel File System. There also are NVM-Express scratch memory options.
A small configuration of 32 GPUs, seen below, provides 90 percent scaling efficiency for such workloads as natural language processing (NLP) and computer vision and more than five times faster throughput for NLP applications.
“What’s really unique about this platform is we’re adding a software layer into the solution and the Machine Learning Development System provides a full stack that allows our customers to have at the core pre-configured hardware and a machine learning platform, networking and services that allow our customers to develop prototypes and then productize those prototypes into true solutions,” Hotard said. “This is a very simplified and basic offering that allows anybody to get started.”
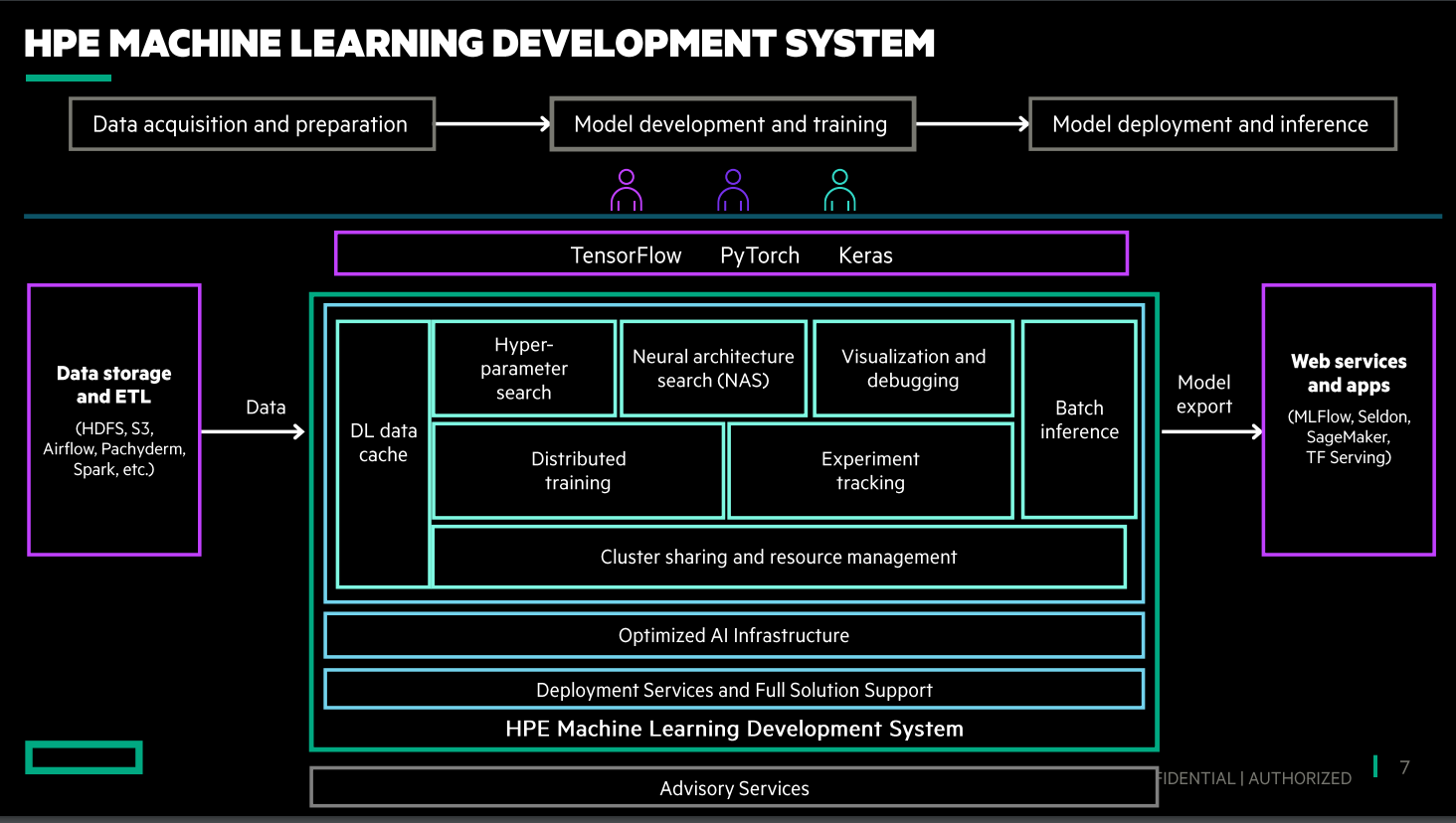
It includes the Machine Learning Development Environment software rolled out last year and such tools as container runtime, cluster management and a training program. The software stack includes Docker for containers, Red Hat Enterprise Linux as the base operating system, HPE’s Performance Cluster Manager; the setup also includes HPE services and support for such AI frameworks as PyTorch and TensorFlow as well as on the often-used Keras Python-based deep learning API.
Aleph Alpha, an AI startup in Germany, is using HPE’s system to train its multimodal AI that includes NLP and computer vision.
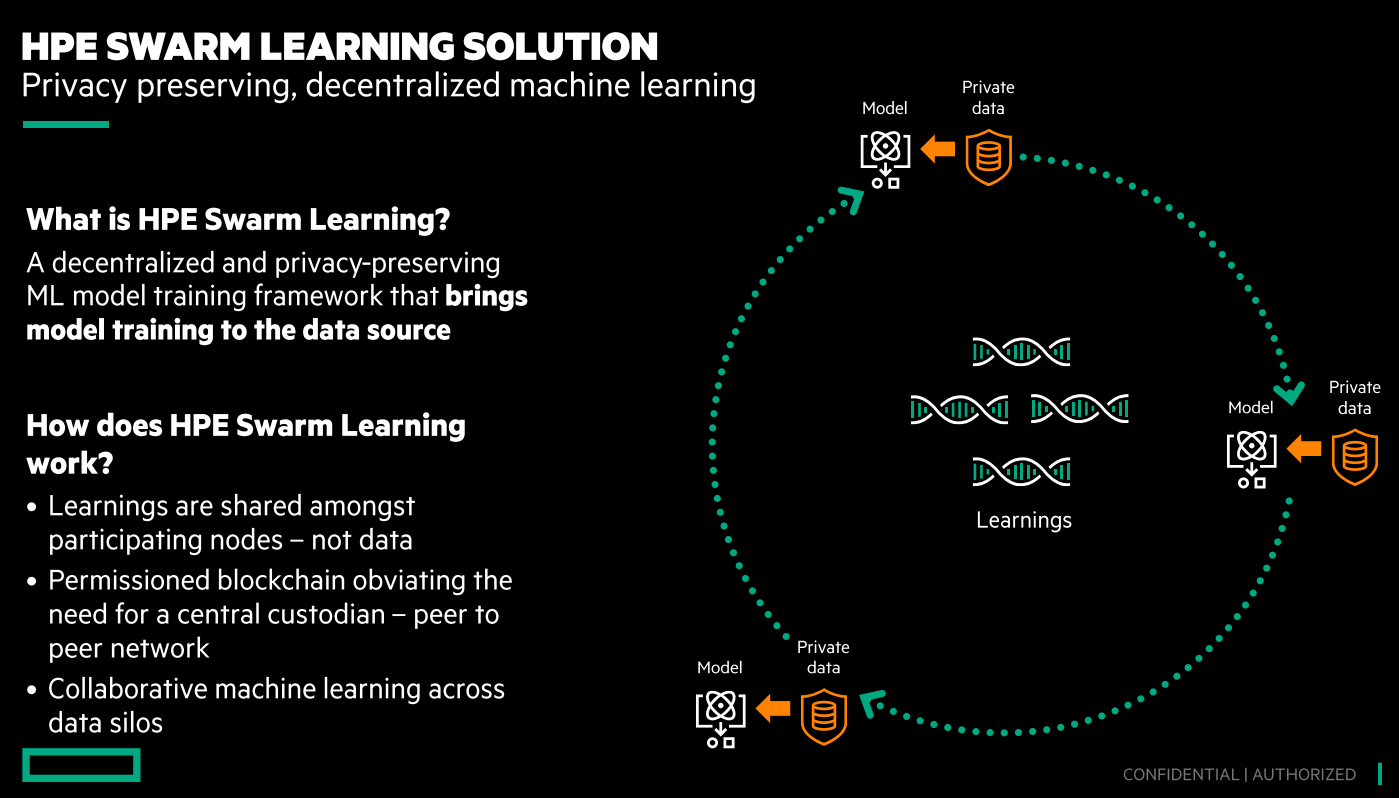
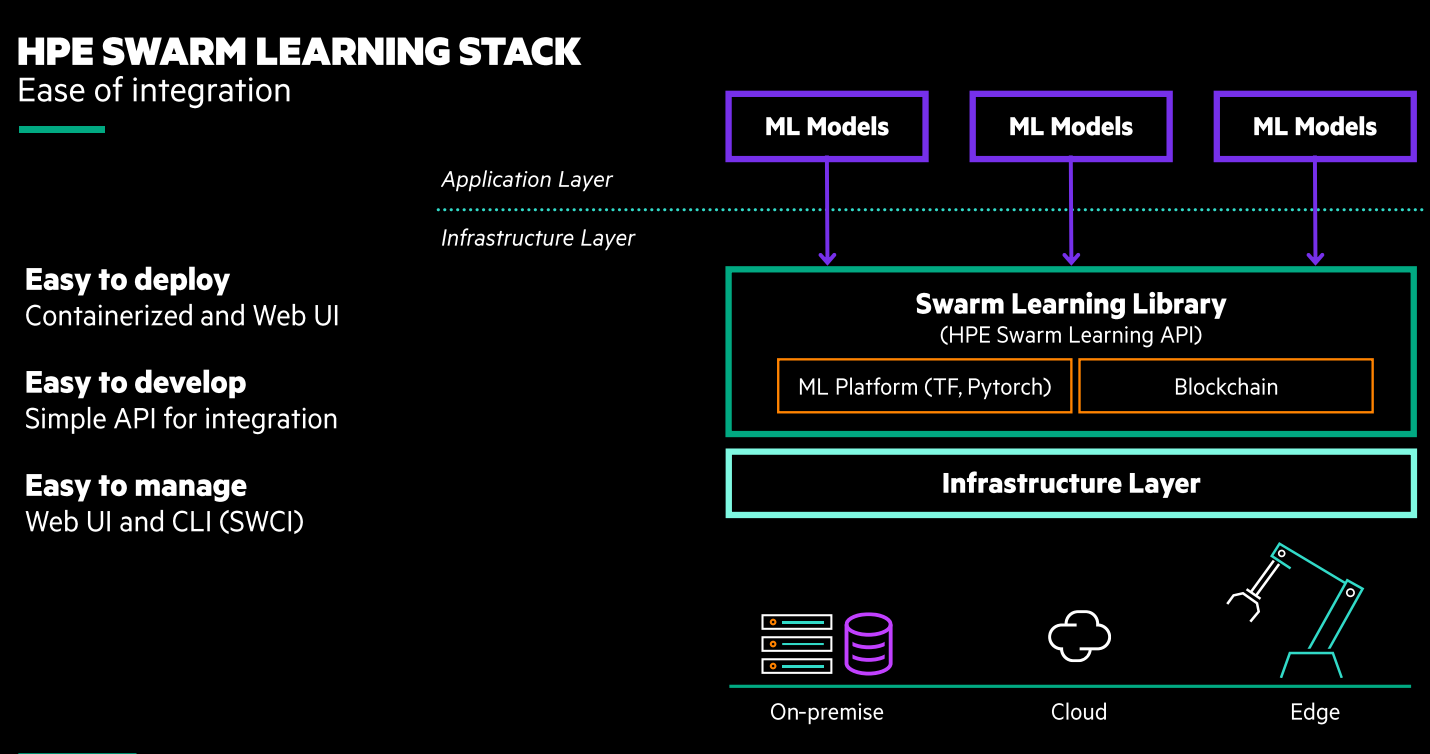
The company also is pulling a swarm learning technology that was developed in Hewlett Packard Labs to create a software product that organizations can use to run analytics on data in such areas as healthcare research and fraud detection. The goal is to analyze the data – which often is located at the edge while preserving the privacy of the data.
“Largely the way that we work – not only in model development and model training, but also operation – is we tend to take all of the data collected and bring it into one core location for model training and model development,” Hotard said. “That data is in many cases collected and gathered at the edge and … in some cases moving that data from the edge to the court has implications for compliance with GDPR [the EU’s General Data Protection Regulation] and other regulations. It’s not trivial to simply move everything into one central location. The complexities of data movement, the costs of data movement when you’re dealing with federated data and particularly federated data is not only geographically federated, but it’s federated across clouds, public and private. The data and the data movement costs and complexity are quite high. What we’re trying to eliminate is the dependency on centralizing and consolidating data. This has ramifications within an enterprise and even across enterprises of different groups.”
Rather than moving the data to a central location, with swarm learning the data analysis and model training is done where the data is located, protecting issues of data privacy and ownership. The learnings that come from the models are then shared across nodes via permissioned blockchains, which allow for access only by users with permissions. The model is refined, but the data isn’t shared.
As an example, Hotard pointed to research being done by separate hospitals using personal health data whose privacy needs to be protected. The data never leaves the individual hospitals; the results of the model training based the data from the hospitals are brought together in a centralized manner.
“This is a really important principle because not only does it allow you to benefit from the common aggregated larger data set, in the case of enterprise, you can eliminate movement between sets of data, which significantly reduces cost and complexity,” he said.
With HPE’s offering organizations use containers that are integrated with AI models using the vendor’s swarm APIs. The results of the AI modeling are shared within and outside of the organization as needed. The software is platform-agnostic, so it can run on systems from HPE – including the Machine Learning Development System – or other vendors and it can run in virtual machines, on bare metal or in containers. It has hyper-parameters that are highly tunable and a management command to control the swarm network.
Merge model parameters enable resilience and security to the network.
In industries like healthcare and banking, where the data can’t be shared, swarm learning allows for decentralized model training. In other sectors, like manufacturing, it’s not a matter of data privacy but more about giving administrators a way to improve predictive maintenance by pulling together data from multiple sensors and devices. The University Aachen in Germany is using HPE’s technology for a colon cancer research project and graph database maker TigerGraph is using it with its own data analytics technology to detect unusual activity in credit card transactions.


HPC In 2020: Acquisitions And Mergers As The New Normal
After a decade of vendor consolidation that saw some of the world’s biggest IT firms acquire first-class HPC providers such as SGI, Cray, and Sun Microsystems, as well as smaller players like Penguin Computing, WhamCloud, Appro, and Isilon, it is natural to wonder who is next. Or maybe, more to …
HPE Superdome Flex: The Other Big Iron In The Datacenter
Not every workload can be chunked up and spread across a relatively loosely coupled cluster of cheap X86 server nodes. Some really do much better running on a big, wonking, shared memory system. In the wake of IBM’s announcement of the Power10-based “Denali” Power E1080 three weeks ago, we have …
HPE GreenLake Platform Gets Expanded Storage And Custom KVM Hypervisor
When Fidelma Russo looks at Hewlett Packard Enterprise’s GreenLake, she sees a rapidly expanding platform that like others is trying to keep pace not only with the growing demands of organizations that are continuing to adopt the cloud but also are looking for ways to bring in and deploy emerging …
Be the first to comment