

The nexus of traditional high performance computing and artificial intelligence is a fact, not a theory, and the exascale-class machinery installed in the United States, Europe, China, and Japan will be a showcase for how these two powerful simulation and analytical prediction techniques can be brought together in many different ways.
A year ago, we wrote about some benchmarks done in China with the Tianhe-3 exascale prototype supercomputer running on custom native many-core Armv8-based Phytium 2000+ processors.
Now comes yet another research paper from more than a dozen scientists from multiple universities in China laying out a hybrid AI-HPC framework on the next-generation exascale Sunway system, the follow-on to the Sunway “TaihuLight” supercomputer that now sits at number four on the Top500 list of the world’s fastest systems, combined with innovative neural network designs and deep learning principles to enable researchers to solve massive and highly complex problems. This effort referred to above is distinct from the BaGuaLu machine learning model that we covered back in March, which spanned 37.44 million cores and that juggled 14.5 trillion parameters.
In this new AI-HPC mashup run on OceanLight, the challenge was what is called quantum many-body problems, which occur when large numbers of microscopic particles interact with each other, creating a quantum entanglement and resulting in a range of physical phenomena. Solving such problems could deliver answers to questions about the laws that hold the natural world together and open doors to new ideas and materials that could be used in areas such as energy and information, the Chinese scientists wrote in a research paper, which was published this month.
Researchers have taken runs at the quantum many-body problems with varying degrees of success.
“Recently, the rapid progress of artificial intelligence powered by deep learning has attracted the science community on applying deep learning to solve scientific problems,” they wrote. “For example, using neural networks to solve differential equations, accelerate molecular dynamics, predict proteins’ 3D structures, control nuclear fusion, and so on. There are also great efforts in applying the deep learning methods to study the quantum many-body problems.”
There have been multiple tests since 2017 using neural networks methods to solve spin models and Fermion models of the quantum many-body problems, but challenges have remained, the researchers wrote. That said, innovations they’ve developed are foundational to an efficient and scalable method for solving the problems with high precision.
“This is achieved by combining the unprecedented representation ability of the deep CNN neural network structures and a highly scalable and finetuned implementation on heterogeneous Sunway architectures,” they wrote. “With the optimized HPC-AI framework and up to 40 million heterogeneous SW26010Pro cores, we solve the ground state of the 1- 2 model in the 36×36 lattice, corresponding to a 21296 dimensional Hilbert space, and solve the model in the 12 × 12 lattice, corresponding to a 3 144 dimensional Hilbert space.”
The researchers created two deep convolutional neural network (CNN) structures, one each for the spin and Fermion models, as seen below. The CNN is less complex and, by leveraging translational invariance, it can scale to very large lattice. The structure of the second CNN is similar to the first, with modifications to adapt to the spin model.
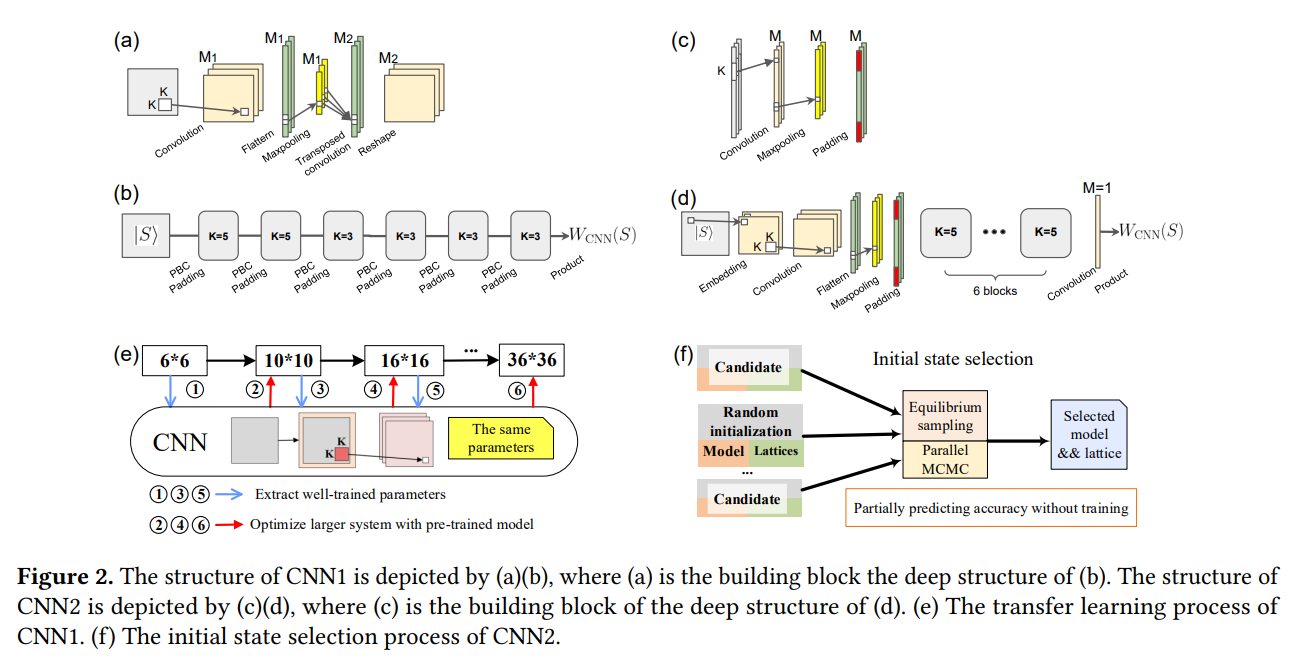
Both CNN structures have differences from others that have been used in such areas as the nonlinearity being induced by maxpooling rather than activation functions and that the wavefunction coefficient is generated by the product of neurons, which is different from the exponential function in other structures.
The Chinese researchers also drove innovations in the HPC-AI hybrid framework, which is shown below.
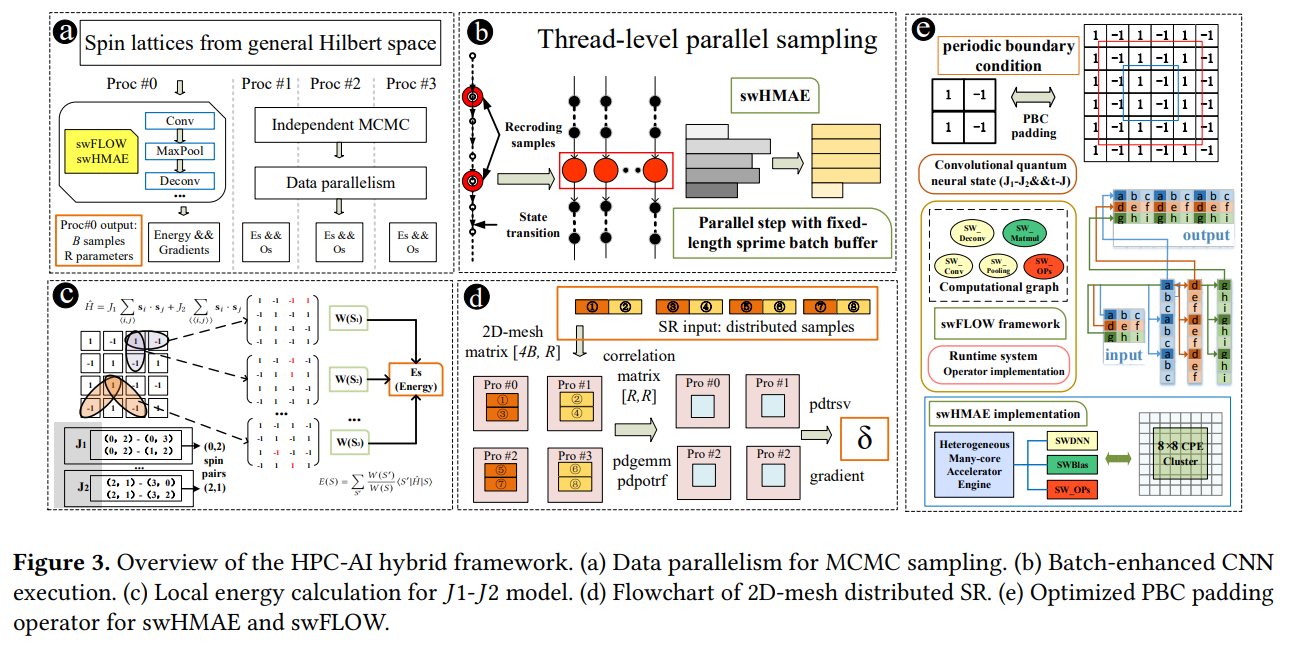
“Despite the fact that quantum many-body problem resides in the realm of dimensional reduction and feature extraction in a much border context, current deep learning frameworks and model optimizations are inefficient,” they wrote. “There are two major difficulties: Firstly, the input size and the network size applied in physics are usually smaller than that of mainstream deep learning tasks, where insufficient computation leads to low computing efficiency and hardware utilization. Secondly, the global minimal energy is difficult for the prevalent first-order gradient optimizer (i.e., Adam, SGD) and the mini-batch based training. To address above difficulties, we propose a highly optimized HPC-AI hybrid framework on the new Sunway supercomputer and achieve multifaceted improvements.”
The framework runs on the next-gen Sunway supercomputer that is powered by the new sw26010pro processor, the latest example of China’s continuing effort to build its most advanced systems with homegrown Chinese technologies. The new chip – an enhanced version of the sw26010 that powers the TaihuLight – comprises six core groups, with each attached to a ring network. Each core group includes a management process element – or control core – that manages the 64 computing process elements, all of which are arranged in an 8-by-8 mesh.
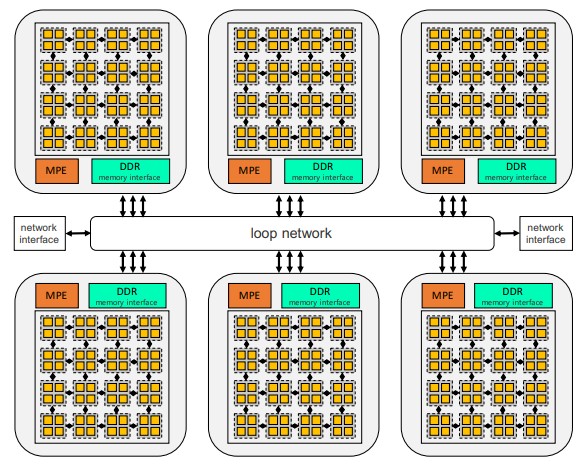
The management element also manages the global memory, while the compute elements execute the tasks assigned via the management element. A local directive memory (LDM) is attached to each compute element, similar to the shared memory in a GPU. Because most of the compute performance for each core group in the new Sunway system is delivered via the 64 compute elements, essentially all of those elements need to be used to reach the highest performance.
The neural networks used in this project involve a lot of memory-intensive operations and are restricted by the gap between the computing capability and the access bandwidth into memory, so the scientists separately optimize the operators on Sunway’s heterogeneous chips, particularly for memory-intensive operators.
In addition, the “software environment has been greatly improved on the new Sunway supercomputer, especially for AI applications,” the researchers wrote. “Meanwhile, the traditional high performance algebra libraries, like BLAS, Lapack, and the distributed ScaLapack, are also optimized. The new generation of Sunway supercomputer delivers great potential to attack various challenges for both HPC and AI.”
The scientists used simulations of quantum many-body problems to get their results, looking at the combination of the latest deep-learning method and the next-gen Sunway platform. They noted the high performance and efficiency of the model, with a focus on scalability delivered via the up to 40 million heterogeneous cores delivered from the latest Sunway chip, with the applications reaching 94 percent weak scaling efficiency and 72 percent strong scaling efficiency.
They also noted that their framework isn’t limited to Sunway and can be ported to other supercomputing platforms, including the Nvidia’s V100 GPU used in the “Summit” supercomputer installed at Oak Ridge National Laboratory (as well as machines based on its follow-on A100 GPU) and Fujitsu’s A64FX heavily vectored Arm chips used in the “Fugaku” supercomputer, which are ranked number two and number one the Top500 at the moment.
“However, as computational power increases, the overall application performance will be limited by the gap between the computing capability and the memory access bandwidth,” they wrote, adding that “Considering the performance of the LDM used in SW26010Pro is not competitive to the performance of HBM2 used in A100 and A64FX … the performance of our framework can be further boosted on Summit or Fugaku systems.”


Why Did China Keep Its Exascale Supercomputers Quiet?
There are no greater bragging rights in supercomputing than those that come with top ten listing on the bi-annual list of the world’s most powerful systems – the Top500. And there are no countries more inclined to throw themselves (and billions) into that competition this decade than the U.S. and …

The Nitty Gritty Of The Sunway Exascale System Network And Storage
We took a look recently at the compute engines at the heart of the future – and as yet unnanmed – Sunway exascale system that will be installed at the National Supercomputing Center in Wuxi, China. This exascale machine will be a follow-on to the current Sunway TaihuLight system, both …

Top500 Supercomputers: Who Gets The Most Out Of Peak Performance?
The most exciting thing about the Top500 rankings of supercomputers that come out each June and November is not who is on the top of the list. That’s fun and interesting, of course, but the real thing about the Top500 is the architectural lessons it gives us when we see …
Be the first to comment