

We are starting to see more exascale and large supercomputing sites benchmark and project on deep learning capabilities of systems designed for HPC applications but only a few have run system-wide tests to see how their machines might stack up against standard CNN and other metrics.
In China, however, we finally have some results about the potential for leadership-class systems to tackle deep learning. That is interesting in itself, but in the case of AI benchmarks on the Tianhe-3 exascale prototype supercomputer, we also get a sense of how that system’s unique Arm-based architecture performs for math that is quite different than that required for HPC modeling/simulation.
There are established software stacks and expected metrics for AI performance on CPU/GPU architectures, but Arm-based architectures and especially those with unique network topologies (like the 2D mesh on Tianhe-3) present unique conditions. That offers one set of surprises, as does the fact that the system is alive and benchmarking at all. At last report the machine was set to arrive in 2020 but with the pandemic, little was heard about the supercomputer until the CNN benchmarking results were released.
The Tianhe-3 machine is based on China’s native manycore Armv8-based Phytium 2000+ (FTP) and the Matrix 2000+ (MTP) processor/node architecture (which we believe to still be DSP-based). Recall that this is one of several exascale computing approaches China has been exploring in recent years (from mainstream CPU/GPU to the Sunway SW26010 RISC-based processors on the #4-ranked TaihuLight supercomputer, for instance). We do not have a node count for the Tianhe-3 exascale prototype as very little is public about this machine, in fact, we were surprised to see published benchmarking results at all, especially for deep learning versus traditional HPC applications.
The researchers who put the Tianhe-3 exascale prototype system through the CNN paces focused on architectural performance for reasoning, training, and distributed training with an eye on bottlenecks in the FTP/MTP architecture using the Roofline performance model. They also included a sketch of the processor architecture for the Tianhe-3 prototype:
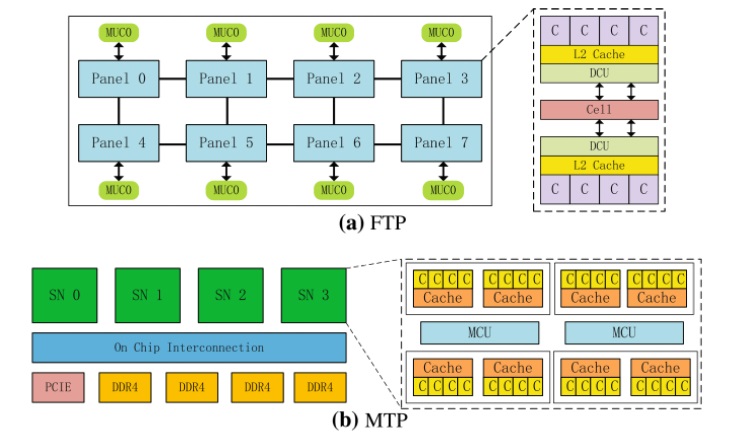
The top is the Phytium architecture and below is the Matrix. The authors say that for the FTP, there are 64 cores distributed in eight panels with an independent memory control unit (MCU) every four cores sharing 2MB of L2 cache with each core having 32KB of L1 cache. Cores operate at 2.2GHz with an entire processor operating at 614.4 GFLOPS (double-precision). MTP has four “super nodes” with 32 cores and 2 MCUs on each node with shared cache for every 4 cores. “The Tianhe-3 prototype divides the FTP and MTP into 32 cores for each node. The high-speed interconnection network in the protoype can provide bidirectional bandwidth of 200Gbps.”
The full paper (gated) describes the various conditions for the benchmarking efforts. In short, they’ve implemented GEMM and Conv2D on the system to test reasoning and training and to determine strong or weak scaling, both for single nodes and multicore and multi-node communication performance. The team used more than 100 parameters and DeepBench as the platform with random FP matrices as test sets.
On the Tianhe-3 prototype with a single sample input, they found CNN reasoning ability of their node is “weak and the processor performance itself cannot be fully exerted.” However, with multiple inputs, which more valuable production-wise, there is a “huge improvement of both two processes (GEMM and Conv2D with the increase in input samples.” Network performance is also good with GEMM and Conv2D approaching peak use of the FTP but with “low memory bandwidth, the ability of MTP cannot be fully exploited.”
Unfortunately, we do not have permission to reprint the graphical images but overall, the team made some notable observations. Remember, the benchmarking was performed on an architecture without all the AI-specific tooling an Nvidia GPU or Intel CPU might have. In other words, it can be considered essentially raw without specific optimizations. The authors add that in the future they’ll use current results to compare the performance of Arm-focused libraries like ACL and distributed training frameworks such as Caffe-MPI so they can make use of the MPI-tuned system.
It is hard to tell what to expect from this novel architecture in terms of AI workloads but for us, the news is that the system is operational and teams are at least exploring what might be possible in scaling deep learning using an Arm-based architecture and unique interconnect. It also shows that there is still work to be done to optimize Arm-based processors for even routine AI benchmarks to keep pace with other companies with CPUs and accelerators.
More detailed descriptions and full graphical benchmark results (gated) here.


GPU Engines Are So Strategic China Will Have To Use Its Own
China is the world’s second largest economy, it has the world’s largest population, and it is only a matter of time before has a world-class technology ecosystem spanning the smallest transistors to the largest hyperscale and HPC systems. It simply has enough money, and enough time, and enough smart people, …

China’s Exascale Quantum Simulation Not All It Appears
And actually, one could say it is also far more than it appears. Three years ago, a team from Oak Ridge National Laboratory (ORNL), Google, and NASA Ames published a paper showing the first glimmer of quantum supremacy. For those who don’t follow quantum computing, in a nutshell this means …
RISC-V In The Datacenter Is No Risky Proposition
It was only a matter of time, perhaps, but the skyrocketing costs of designing chips is colliding with the ever-increasing need for performance, price/performance, and performance per watt. Something has got to give, and that thing might be the architectures currently used in the datacenter. What the world needs, perhaps, …
Be the first to comment