
If you were going to build an electronic brain in 2022, it might look something like the Neocortex supercomputer at the Pittsburgh Supercomputing Center at Carnegie Mellon University. That machine, which was only installed last year, has now got a brain transplant of sorts with the upgrading of its two AI hemispheres, which are based on the wafer-scale matrix math engines created by Cerebras Systems.
The initial Neocortex system, which we wrote about in March last year when the system first became available for running machine learning training and inference applications and which is being used as a means to converge traditional HPC simulation applications, was based on the WSE-1 compute engines, which had 400,000 of the Cerebras sparse linear algebra compute (or SLAC) cores on a single silicon wafer etched with 16 nanometer processes from Taiwan Semiconductor Manufacturing Co. The WSE-1 has 1.2 trillion transistors, 18 GB of SRAM supporting those cores, 9.6 PB/sec of bandwidth with that SRAM, and 100 Pb/sec of aggregate bandwidth over the 2D mesh interconnect linking all of those SLAC cores. To get data into and out of the resulting CS-1 system required a dozen 100 Gb/sec Ethernet ports.
The Neocortex machine had a pair of these CS-1 machines and a big wonking Superdome Flex system from Hewlett Packard Enterprise acting as a kind of “corpus callosum” interconnect between the two CS-1 machines, but in this case the interconnect has its own local memory, storage, and compute, too. The Superdome Flex machine is configured with 32 of Intel’s “Cascade Lake” Xeon SP 8280L processors, which have 28 cores each and which run at a base 2.7 GHz. The HPE system has 24 TB of main memory that has a combined 4.5 TB/sec of memory bandwidth; it also has 204.6 TB of NVM-Express flash with 150 GB/sec read performance. There are two dozen 100 Gb/sec Ethernet ports, with a dozen linking to each CS-1 machine, and then there are sixteen 100 Gb/sec HDR InfiniBand adapters, with a total of 1.6 Tb/sec of bandwidth, linked out to the “Bridges-2” traditional supercomputer.
In a sense, the Neocortex cluster is a memory-enhanced AI accelerator with three very intense nodes for the Bridges-2 machine, which is a $10 million machine that was installed at PSC back in March 2021. The Bridges-2 system has three different kinds of nodes. There are 272 “regular memory” nodes that have a pair of AMD “Rome” Epyc 7742 processors running at 2.24 GHz and with 256 GB of memory; 16 “regular memory” nodes with the same processors but with 512 GB of memory; 16 “extreme memory” nodes based on a pair of 24-core Intel Cascade Lake 8260M platinum processors with 4 TB of memory; and 24 “GPU” nodes that have eight Nvidia V100 GPU accelerators tied to a host with a pair of Cascade Lake 6248 Gold processors running at 2.5 GHz and sporting 512 GB of memory. The nodes use 200 Gb/sec HDR InfiniBand to link to each other.
Here is a schematic of the Neocortex and Bridges-2 machines:
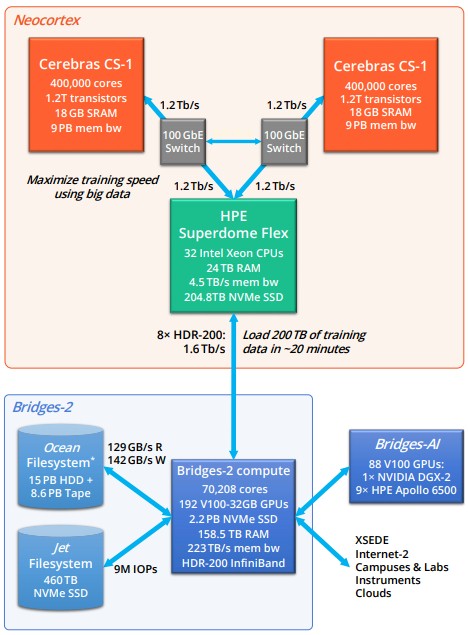
PSC does not run the Linpack benchmark for publication in the Top 500 supercomputer rankings on the Bridges or Bridges-2 machines, but the latter has 70,208 X86 cores and with the GPU nodes, it is easily petaflops of performance. The metric that PSC cares about with regard to Neocortex, and which it published in this paper, is this one: If data is “well-distributed” in the memory of the Bridges-2 machine and its attached “Jet” Lustre parallel file system running on flash and “Ocean” Lustre parallel file system based on disk, then Bridges-2 can load 200 TB of training data into the Neocortex system in about 20 minutes.
The news this week is that the pair of CS-1 systems that do the AI calculations were swapped out with two shiny new CS-2 machines from Cerebras, an upgrade that presumably was part of the $11.3 million that the National Science Foundation (which also funded Bridges-2) shelled out for the Neocortex contract. The CS-2 machines and their WSE-2 processors were announced in August 2021 and Cerebras was showing off its success with big pharma and big oil with these CS-2 kickers back in early March.
The CS-2 machines have a lot more capacity on all vectors (so to speak), and that means that they can support larger AI models. Specifically, the WSE-2 chip has 850,000 SLAC cores etched with 2.6 trillion transistors using a 7 nanometer TSMC process. The chip also sports 40 GB of on-chip SRAM with 20 PB/sec of aggregate bandwidth, and 220 Pb/sec of aggregate bandwidth over that 2D mesh linking all of the cores. That’s a factor of 2.1X more SLAC cores, 2.2X more SRAM memory, 2.2X more 2D mesh bandwidth, which is a pretty balanced kicker compute engine as these things go. The increase in SLAC cores means that larger AI models can be run on the improved Neocortex Cerebras nodes, and if a model can be chopped up into more processing elements, the model will train faster. Because the grid of cores is so large, the many layers of a neural network can be mapped onto different logic blocks and connected over the 2D mesh and processed all within the single, wonking wafer.
But there is also a new “weight streaming” mode that is available with the CS-2 machine that complements the “pipelined” mode of the CS-1, and PSC gives a very good description of the difference between the two which we cannot improve upon: In the pipelined mode, the entire model is mapped onto the WSE-2 at once, with each layer of the model getting a portion of the wafer. This arrangement leverages activations and data sparsity with very low latency, an approach that works well for most deep learning models. With weight streaming, one layer of the network is loaded onto the CS-2 fabric at a time, leveraging dynamic-weight sparsity. Thus the model is arranged in time rather than space, with weights instead of activations streaming. This approach offers industry leading performance for extreme-scale models and data inputs.
Here is a diagram showing the weight streaming mode into one WSE-2 wafer chip:
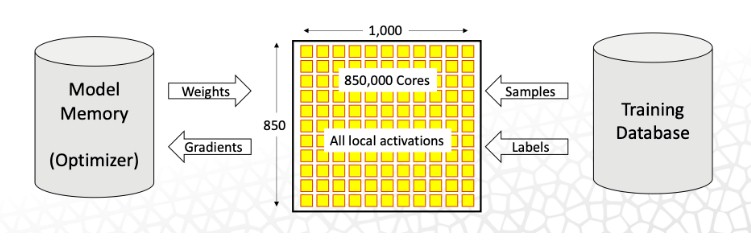
“The principal difference is what’s kept stationary on the wafer and what’s streaming through the wafer,” explains Natalia Vassilieva, director of product for machine Learning at Cerebras. “The compiler will pick the proper execution mode depending on the size of the model.”
In the near future, Cerebras says, users will be able to choose the mode, which seems to indicate that one of these modes is not available now. Our guess is pipelined mode is available now and weight streaming mode is still being perfected.
The CS-2 has all of this in the same footprint, power consumption, and cooling requirements of the CS-1.


Drug Discovery a Sweet Spot for Cerebras CS-2
So far, waferscale systems maker, Cerebras, has had its early success among the HPC centers looking for opportunities in AI and with drug makers, including GSK and AstraZeneca. Biotech startup, Peptilogics, announce today they have also been working with Cerebras to map and optimize neural search and other graph-driven AI …

Anton Sequel Makes Stronger Case for Custom Supercomputing
D.E. Shaw Research, the company founded by quantitative finance pioneer, professor, and entrepreneur, David E. Shaw, has always been shrouded in mystery. The company has a financial services arm, but also makes (among other systems) a special purpose supercomputer designed for the specific needs of molecular dynamics research. Based on a …
Be the first to comment