

If you need any proof that it doesn’t take the most advanced chip manufacturing processes to create an exascale-class supercomputer, you need look no further than the Sunway “OceanLight” system housed at the National Supercomputing Center in Wuxi, China.
Some of the architectural details of the OceanLight supercomputer came to our attention as part of a paper published by Alibaba Group, Tsinghua University, DAMO Academy, Zhejiang Lab, and Beijing Academy of Artificial Intelligence, which is running a pretrained machine learning model called BaGuaLu, across more than 37 million cores and 14.5 trillion parameters (presumably with FP32 single precision), and has the capability to scale to 174 trillion parameters (and approaching what is called “brain-scale” where the number of parameters starts approaching the number of synapses in the human brain). But, as it turns out, some of these architectural details were hinted at in the three of the six nominations for the Gordon Bell Prize last fall, which we covered here. To our chagrin and embarrassment, we did not dive into the details of the architecture at the time (we had not seen that they had been revealed), and the BaGuaLu paper gives us a chance to circle back.
Before this slew of papers were announced with details on the new Sunway many-core processor, we did take a stab at figuring out how the National Research Center of Parallel Computer Engineering and Technology (known as NRCPC) might build an exascale system, scaling up from the SW26010 processor used in the Sunway “TaihuLight” machine that took the world by storm back in June 2016. The 260-core SW26010 processor was etched by Chinese foundry Semiconductor Manufacturing International Corporation using 28 nanometer processes – not exactly cutting edge. And the SW26010-Pro processor, etched using 14 nanometer processes, is not on an advanced node, but China is perfectly happy to burn a lot of coal to power and cool the OceanLight kicker system based on it. (Also known as the Sunway exascale system or the New Generation Sunway supercomputer.)
Back in February 2021, when we took a stab at how OceanLight could be built using 14 nanometer chips, we figured that given the need to get heat to stay low, NRCPC would keep the clock speed on its future processor the same, double up the number of compute elements on a future SW-class chip, double the vector widths to 512-bits, and double the cabinets to get to a proper exaflops peak theoretical performance at FP64 precision. (We drilled down into the storage and networking for the OceanLight machine here.)
As it turns out, it looks like NRCPC was less concerned with the clock speed than we thought, and the SW26010-Pro processor increased the compute elements 50 percent, boosted the vector widths to 512-bits, and maybe increased the clock speed (we will do some math in a second), and ran up the node and cabinet count to go quite a bit beyond exascale.
Here is what the SW26010-Pro compute engine looks like:
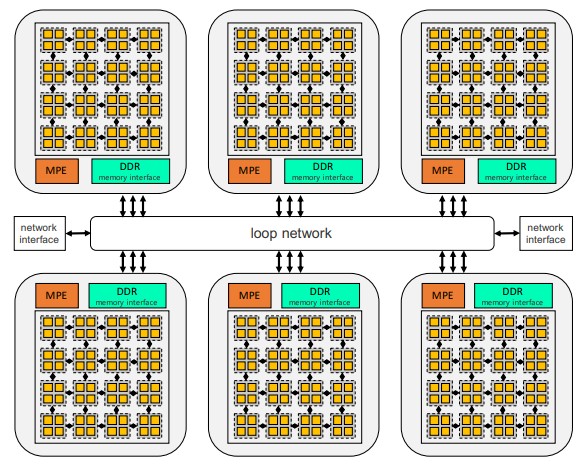
There are six blocks of core groups in the processor, with each core group having one fat management processing element (MPE) for managing Linux threads and an eight by eight grid of cores comprising a compute processing element (CPE) with 256 KB of L2 cache. If you look carefully, each CPE has four logic blocks, which can support FP64 and FP32 math on one set of units and FP16 and BF16 on another set. Each of the core groups in the SW26010-Pro has a DDR4 memory controller and 16 GB of memory with 51.4 GB/sec of memory bandwidth, so the full device has 96 GB of main memory and 307.2 GB/sec of bandwidth. The six CPEs are linked by a ring interconnect and have two network interfaces that link them to the outside world using a proprietary interconnect (which we think is heavily inspired by the InfiniBand technology used in the original TaihuLight system).
The SW26010-Pro is rated at 14.03 teraflops at either FP64 or FP32 precision and 55.3 teraflops at BF16 or FP16 precision. (The Sunway chip family is “inspired” by the 64-bit DEC Alpha 21164 processor from days gone by, and has no doubt been substantially changed since the 16-core SW-1 chip debuted in China back in 2006.
The TaihuLight system had 1,024 nodes (four supernodes) in a cabinet and a total of 40 cabinets to reach the 125.4 petaflops of peak theoretical performance.
As far as we know, SW26010-Pro processor is socket compatible with the SW26010, so the system setup should be the same. The largest configuration of the OceanLight system that has been tested accessed 107,520 nodes (one SW26010-Pro each) for a total of 41.93 million cores. That works out to 105 cabinets, which is a factor of 2.6X more floorspace and cabinetry.
This is how the system hierarchy of the OceanLight machine works:
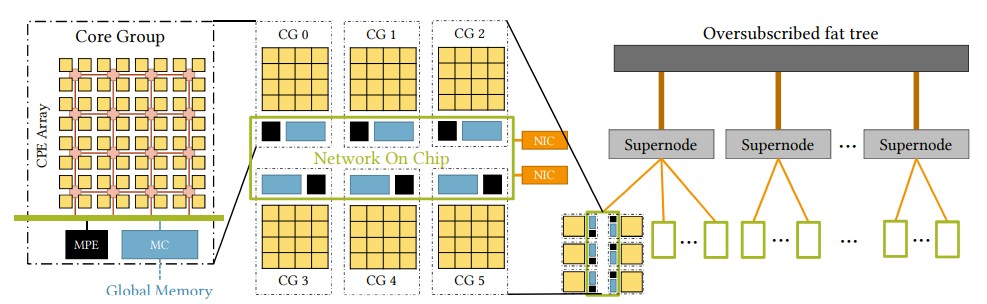
The nodes within a supernode are linked in a 3X oversubscribed, non-blocking fat tree topology. The paper says that it is a proprietary interconnect, but we think it is a tweaked version of InfiniBand (that’s just a hunch).
Now, let’s think about clock speed for a second. The SW26010 was rated at 3.06 teraflops peak and ran at 1.45 GHz. If you did a die shrink on this chip from 28 nanometers and then increased the cores by 50 percent and then doubled up the vector width to 512-bits, while keeping the clock speed the same, then you would create a device that delivered 9.2 teraflops. But this SW26010-Pro chip delivers 14.03 teraflops, and so the clock speed must have increased by 52.7 percent to 2.22 GHz to reach that performance level.
Add it all up, and the 105 cabinet system tested on the BaGuaLu training model, with its 107,250 SW26010-Pro processors, had a peak theoretical performance of 1.51 exaflops. We like base 2 numbers and think that the OceanLight system probably scales to 160 cabinets, which would be 163,840 nodes and just under 2.3 exaflops of peak FP64 and FP32 performance. If it is only 120 cabinets (also a base 2 number), OceanLight will come in at 1.72 exaflops peak. But these rack scales are, once again, just hunches.
If the 160 cabinet scale is the maximum for OceanLight, then China could best the performance of the 1.5 exaflops “Frontier” supercomputer being tuned up at Oak Ridge National Laboratories today and also extend beyond the peak theoretical performance of the 2 exaflops “Aurora” supercomputer coming to Argonne National Laboratory later this year – and maybe even further than the “El Capitan” supercomputer going into Lawrence Livermore National Laboratory in 2023 and expected to be around 2.2 exaflops to 2.3 exaflops according to the scuttlebutt.
We would love to see the thermals and costs of OceanLight. The SW26010-Pro chip could burn very hot, to be sure, and run up the electric bill for power and cooling, but if SMIC can get good yield on 14 nanometer processes, the chip could be a lot less expensive to make than, say, a massive GPU accelerator from Nvidia, AMD, or Intel. (It’s hard to say.) Regardless, having indigenous parts matters more than power efficiency for China right now, and into its future, and we said as much last summer when contemplating China’s long road to IT independence. Imagine what China can do with a shrink to 7 nanometer processes when SMIC delivers them – apparently not even using extreme ultraviolet (EUV) light – many years hence. . . .
The bottom line is that NRCPC, working with SMIC, has had an exascale machine in the field for a year already. (There are two, in fact.) Can the United States say that right now? No it can’t. The United States is counting on its exascale machines to be more energy efficient – Frontier and El Capitan for sure, we shall see with Aurora – but we have no idea how computationally efficient any of these future machines really are.
Like many of you, we are eager to find out. This competition drives architectures.
One last thing. The BaGuaLu model on the OceanLight machine had 96,000 nodes running for a total of 37.44 million cores, and that was able to do the 14.5 trillion parameters. If you move to FP16 or BF16 precision, that works out to 29 trillion parameters, and if you scale across all the nodes that would fit in 160 cabinets, that gets you to 49.5 trillion parameters at FP16 or BF16. It is not clear how to get to the 174 trillion parameters that the BaGuaLa paper talks about without adding support for INT8 and INT4 data formats. By our math, that would be 198 trillion parameters at INT4 – still well shy of the 500 trillion parameters that GraphCore is shooting for with its “Good” supercomputer in the next few years.

If I understand correctly each CPU has ~14 TFLOP/s FP64 and 307.2 GB/s of memory bandwidth. Comparing with an NVIDIA V100 we find ~8 TFLOP/s FP64 and 900 GB/s of memory bandwidth. So twice the FLOP/s and one-third the bandwidth for an overall FLOP-to-byte ratio which is ~1/6th that of a GPU. Comparing with the Fujitsu A64FX (~3.1 TFLOP/s and 1 TB/s of bandwidth) the ratio is ~1/15. Given that many HPC codes are memory bandwidth bound (ML applications excluded) and things are no longer as impressive.
Bandwidth and usability may not win you first place on the TOP500, but they will help when it actually comes to doing science. This is something the US arguably learned after Roadrunner and to a far lesser extent Titan. Intel and NVIDIA have both been very good here recently (Intel improving L2 cache sizes and introducing HBM on upcoming Xeon’s and NVIDIA since Volta where they dramatically improved the cache hierarchy and microarchitecture).
“The SW26010-Pro is rated at 14.03 petaflops at either FP64 or FP32 precision and 55.3 petaflops at BF16 or FP16 precision.”
Did you mean teraflops?
Yes. Thanks for the catch.
How similar is the Shenwei SW26010-Pro to a DEC alpha with vector extensions?
Is there an assembler reference guide (in any language) available?
I wonder if the processor will ever be available outside China or if that is impossible due to unlicensed use of patents and other intellectual property. In either case, it would be interesting if QEMU could be made to emulate it.