
In case it is not immediately obvious, over the past decade Nvidia has been transforming itself from a component supplier into a complete platform provider. Such a move was not necessary – you can expect for AMD to be pretty gun shy about such a move after is acquisition of SeaMicro a decade ago – but it is consistent with the prevailing idea as Moore’s Law is slowing that every part of the stack has to be co-designed and co-optimized to wring the most performance out of a system.
There is no system without compute, networking, and storage together – this is a kind of hyperdependent trinity, if you will. So it is inevitable that any platform player will ultimately want to control all three aspects of the systems that they build, and control them at a deeper and deeper level, too. And the reasons have as much to do with real engineering as they do with financial engineering. And it is also inevitable that any platform builder will want to control the controllers that keep tabs on compute, networking, and storage.
Nvidia co-founder and chief executive officer Jensen Huang has been perfectly clear that he sees the GPU maker as a platform company, and said as much in an exclusive interview with us in the wake of the acquisitions of Mellanox Technologies in April 2020 (for $6.9 billion) and Cumulus Networks in May 2020 (for an undisclosed and much smaller amount), and as the ill-fated $40 billion deal to acquire Arm Holdings from SoftBank was just getting started. Nvidia did not need Arm to be a broader compute player, it just needs a CPU and the Arm-based, homegrown “Grace” CPU coming out next year will, we strongly suspect, be as innovative as Nvidia’s GPU compute engines have been since the first “Fermi” GPU accelerators were announced back in 2010.
On the control front, Nvidia developed its own Base Command data preparation and machine learning training run management software underneath AI Enterprise, which is a workflow for doing machine learning training and then creating inference models; it also created the Fleet Command orchestration and system management tool that Nvidia created to run AI Enterprise out at the edge. (Both of these debuted last year, and we covered both of them in detail here.) And earlier this year, Nvidia paid an undisclosed sum to get its hands on Bright Computing so it could weave its Bright Cluster Manager into the Nvidia stack.
We said at the time that we would not be surprised if Nvidia picked up one of the several makers of composable and disaggregated interconnect fabrics, such as GigaIO or Liqid, and frankly we thought Nvidia would start there because allocating GPUs in a flexible way is a real problem for a lot of customers and driving up efficiency for these expensive compute devices is as well. Ditto for NVM-Express flash, which is being disaggregated and composed on the fly as well to drive efficiencies and performance, but in a slightly different way.
This may indeed be part of the Nvidia plan, but today, with the acquisition of Excelero, one of several NVM-Express flash startups that has been pushing disaggregated and composable storage for the past several years, it is beginning to look like Nvidia wants to control its own block storage for HPC and AI applications and will be composing this to run across its Ethernet and possibly InfiniBand networks and very likely with DPUs based on a combination of Connect-X NICs, BlueField multicore Arm processors, and Nvidia GPUs and possibly on raw BlueField CPUs acting as storage node controllers instead of X86 processors. This latter bit is something that we saw Mellanox playing around with back at the Open Compute Summit in 2019 with its SNAP, which is short for Software-defined Network Accelerated Processing, for linking disaggregated flash storage to servers.
To add storage to the Nvidia stack, Nvidia could have acquired DriveScale before Twitter snapped it up, or even Lightbits Labs, which is another interesting vendor that is using NVM-Express over Fabrics to cluster storage. But instead, Nvidia opted to acquire Excelero, which we first talked about five years ago when it dropped out of stealth and first showed off its NVMesh flash clustering platform.
Excelero was founded back in 2014 in Tel Aviv, Israel, and subsequently moved its headquarters to San Jose, down the road from Nvidia, Intel, and other IT giants. Lior Gal, who headed up sales at DataDirect Networks for its content and media business for many years, is a co-founder and was chief executive officer for a number of years. Yaniv Romem, who was vice president of research and development of server hypervisor maker ScaleMP, was the company’s original chief technology officer and is now CEO after Gal. Ofer Oshri, who was also a core team leader at ScaleMP, is still vice president of research and development and Omri Mann, who apparently created the first antivirus software in the world and who did stint at ScaleMP, is still chief scientist. Kirill Shoiket, who lead the final architectures of XtremIO before EMC shelled out $430 million to take over the flash storage innovator, was brought in by Excelero to be CTO. Excelero raised four rounds of funding prior to and shortly after dropping out of stealth, and raised $35 million up through August 2018. Battery Ventures, Square Peg Capital, Qualcomm Ventures, and Western Digital Ventures all kicked in money as did some personal investors. Mellanox, and therefore now Nvidia, is an investor in Excelero as well. Considering how much cash has been sloshing around in the past four years, this is not that much fundraising.
The interesting bit about NVMesh is that while it is distributed block storage that can run file parallel systems like Lustre, SpectrumScale (GPFS), or BeeGFS that is used as scratchpad storage for traditional HPC simulation and modeling applications, when it comes to the unstructured and semi-structured data that is needed to train neural networks using machine learning, this overhead of a parallel file system can be avoided by having local nodes in the cluster mount the NVMesh from whatever file systems (often XFS) that are running on the nodes, giving the feel of a parallel file system without any of the headaches.
NVMesh can run over many different protocols and fabrics – plain TCP/IP, NVM-Express over Fabrics, InfiniBand, or Ethernet with RoCE v2 – to access flash storage on the network and make everything look local to all of the nodes in a cluster. The secret sauce that Excelero has come up with is called the Remote Direct Drive Access (RDDA) protocol, which is a means of talking directly to NVM-Express flash devices in a node without going to drivers on the CPU. Much as InfiniBand RDMA and Ethernet RoCE allow two network cards to chat with each other and access CPU or GPU main memory without going through the CPU driver stack, or NVM-Express allows CPUs to access flash without going through the PCI-Express driver and using the SCSI protocol to access flash. The RDDA protocol has been patented and only adds 5 microseconds of latency overhead to access remote flash over the network compared to accessing it locally in a node. The NVMesh storage software can run on premises on standard servers with flash and can also be run on the public cloud on flash-based instances to create virtual flash arrays. And, importantly for Nvidia, the Excelero stack has been tuned to work in conjunction with Nvidia’s Magnum IO storage acceleration software layer, which debuted in November 2019.
You might think that, given the amount of unstructured data that drives machine learning training, that the amount of object storage versus block storage on the system would be much larger. But if you look at the 760-node first phase of the Research Super Computer (RSC) system that Meta Platforms just acquired from Nvidia, there is 175 PB of FlashArray block storage from Pure Storage but only 10 PB of FlashBlade object storage; there is also a 46 PB “caching cluster” that sits somewhere in the architecture, and we strongly suspect this is disk-based archives of datasets and not production storage. That primary storage will grow to in excess of 1 exabyte of capacity, and Nvidia no doubt saw how much dough is going to Pure Storage in this deal – analyst Aaron Rakers at Wells Fargo estimates the storage for RSC will contribute $30 million to Pure Storage’s coffers.
When we wrote this, we had not realized that Nvidia had late last week acquired SwiftStack, and commented here that we would not be surprised if Nvidia decided it also needs object storage to complete the storage software set for AI and HPC. We suggested that MinIO was an obvious choice, with Ceph controlled by Red Hat and therefore by IBM. Ceph is also an option, of course, as were a number of other object storage options (including the actually acquired SwiftStack). And Mellanox also has a stake in WekaIO, and if Nvidia thinks it needs a parallel file system that works pretty good for HPC and AI workloads, it may take a shining to acquiring that company, too. And that would largely complete the datacenter storage picture. That would be the last piece.
Nvidia is not just buying Excelero to make money, either, but to also better co-design the full Nvidia HPC and AI stack. A lot of the integration of the Nvidia hardware and software with Excelero NVMesh has already been done, as you can see here:
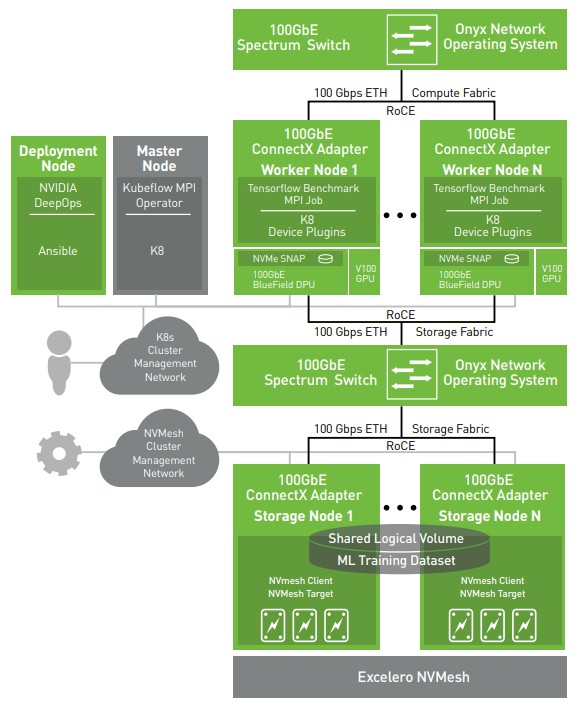
As we have pointed out earlier, there is no reason that the storage controller on each storage node has to be an X86 server. A BlueField-powered DPU motor could do the trick provided it had enough PCI-Express lanes to link out to NVM-Express flash. And in the longest of runs, Nvidia could use a Grace Arm server CPU as a storage node controller motor if it needed more oomph. The point is for Nvidia to own more of its stack and to boost the volumes of the devices it has etched by its foundry partners.

Ongoing Saga: How Much Money Will Be Spent On AI Chips?
Everybody knows that companies, particularly hyperscalers and cloud builders but now increasingly enterprises hoping to leverage generative AI, are spending giant round bales of money on AI accelerators and related chips to create AI training and inference clusters. But just you try to figure out how much. We dare you. …
How Much Can Dell Profit From The AI Wave?
For most of the generative AI revolution thus far, the big original equipment manufacturers, or OEMs, have been sidelined as Nvidia and now AMD have done direct allocations of their GPU compute engines to hyperscalers, cloud builders, and other lighthouse customers. But if the second AI wave is going to …
Blackwell Is The Fastest Ramping Compute Engine In Nvidia’s History
With the months-long blip in manufacturing that delayed the “Blackwell” B100 and B200 generations of GPUs in the rear view mirror and nerves more calm about the potential threat that the techniques used in the AI models of Chinese startup DeepSeek better understood, Nvidia’s final quarter of its fiscal 2025 …
“So, don’t be surprised if Nvidia devices it also needs object storage to complete the storage software set for AI and HPC.” Perhaps you should read your own publication:
https://blocksandfiles.com/2020/03/05/nvidia-acquires-swiftstack/ 🙂
Well, I missed that one. So thanks, but it just proves I was right in principle, and a parallel file system is the only missing piece.