

While legacy monolithic applications will linger in virtual machines for an incredibly long time in the datacenter, new scale-out applications run best on new architectures. And that means the underlying hardware will look a lot more like what the hyperscalers have built than traditional siloed enterprise systems.
But most enterprises can’t design their own systems and interconnects, as Google, Facebook, and others have done, and as such, they will rely on others to forge their machines. A group of hot-shot system engineers that were instrumental in creating systems at Sun Microsystems and Cisco Systems in the past two decades have founded a company called DriveScale that is taking on this job, and rather than architecting a closed-box system they have come up with a way to break the hard link between compute and storage in clusters, and they are doing so in a way that will work with commodity servers and storage enclosures that enterprises are already using.
Setting the ratio of disk to compute inside of the nodes in a cluster is a big problem, and one that all organizations deal with. As applications come and go on the nodes in the cluster, they are stuck with whatever storage happens to be inside the node. This is not the way that hyperscalers build infrastructure. They have long since broken the link between compute and storage in their clusters and have set up massive networks with reasonably low latency and high bandwidth that can make any storage server with flash or disk running inside a datacenter with up to 100,000 systems look more or less local to any server one of those servers.
DriveScale is inspired by these hyperscalers and is doing a similar thing by busting storage from compute and then recomposing it on the fly through a mix of hardware and software, but is doing this recomposition at the rack level, an architectural choice that is more amenable to enterprise and the kinds of applications, scale, and budgets that they have. The DriveScale approach is akin to the composable infrastructure efforts that Cisco Systems has been espousing with its Unified Computing System M Series and Hewlett Packard Enterprise has begun with its “Thunderbird” Symphony line of machines, but is different in that it is focusing on storage virtualization rather than all components of the system as Cisco and HPE eventually want to do.
“Google and Facebook use lots and lots of network bandwidth to address this issue,” explains Gene Banman, CEO at DriveScale, which uncloaked from stealth mode recently and which is getting its first proofs of concepts out the door and talking about its funding and a partnership with contract manufacturer Foxconn. “They basically use commodity servers and have a fat tree or a Clos network that allows them to connect servers with disk drives anywhere in the datacenter, and they don’t care where the servers or storage are because they have this enormous amount of bandwidth across the datacenter. It is quite an expensive approach and not very enterprise friendly, and we think our approach is more efficient as far as giving storage and compute flexibility.”
Banman does not see these high-end hyperscalers as prospects for its DriveScale storage adapters, which allow for malleable configuration of disk enclosures with compute servers within a rack, but the startup does foresee that smaller service providers, cloud builders, and enterprises that want adjustable compute and storage for applications will benefit from the DriveScale approach and not have to replumb their networks as the hyperscalers have done. These hyperscalers have spent a fortune on 40 Gb/sec Ethernet networks over the past several years, and due to their explosive growth, they are now transitioning to 100 Gb/sec networks. The DriveScale rack-level storage virtualization does not require 40 Gb/sec or 100 Gb/sec Ethernet to work, and in fact Banman says it was designed explicitly to work fine with the 10 Gb/sec Ethernet switches that are now commonly deployed in enterprise datacenters.
The idea is that the DriveScale adapters, which act as a bridge between Ethernet ports on servers and storage enclosures using SAS protocols using a plain vanilla top-of-rack Ethernet switch, can allow any server to talk to any JBOD array.
This Is A Different Kind of Virtualization
With the server virtualization wave that swept through datacenters in the past decade, the main impetus was to use a software abstraction layer to allow the consolidation of multiple applications that were running on distinct physical machines, thereby driving up the utilization of machines. Over time, virtualized servers were able to be clustered and presented as a pool of resources, but the basic idea of cramming multiple, and very different, applications on a single machine remained unchanged just because machines were clustered to support high availability and load balancing.
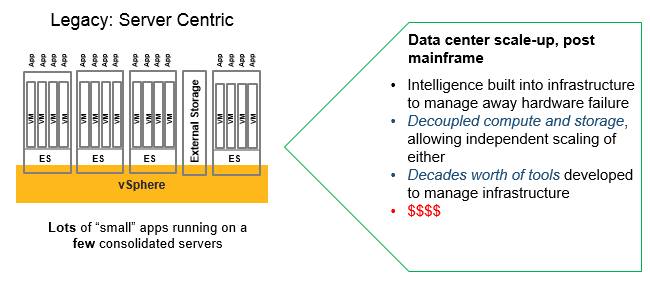
With this server virtualization approach, storage was decoupled from compute to a certain extent, which was also useful in that it allowed them to be independently scaled. But the physical server and its compute and storage configuration were still set in stone. Once you bought it, that was how the system was configured. And this was really a funky kind of scale up (fatter nodes for more virtual machines per system or for running heavier workloads) mixed with a loosely coupled kind of scale out that was more about the resiliency of the individual VMs than anything else.
What is needed in a modern cluster, argues DriveScale, is a means of allocating storage from a pool of disk drives that is dynamic and not tied to what is configured in any specific node. And on modern platforms, particularly those that do intensive analytics on massive datasets, there is a need to have storage scale up and down as the compute requires and to have that storage be as local as possible to that compute. This is actually driving up storage requirements in servers even as individual servers are getting stuffed with more and more cores.

The reason why Hadoop and other analytics frameworks have become so popular is that they offer much cheaper storage of unstructured data compared to traditional data warehouses, but the tight linking of cores and disks in the clusters that run these frameworks often means that system administrators have to reject projects or they have to overprovision clusters with server nodes because they need more storage. This is wasteful, and Banman says that the DriveScale storage virtualization cards have been priced so that enterprises will be able to drive up the utilization on their clusters, buying the right amount of compute and storage for their workloads and being able to change it on the fly as workloads change. Moreover, they will be able to buy one or two types of minimalist compute nodes and maybe one or two different JBOD arrays and be able to cover all of their workload types on the cluster.

The DriveScale hardware implements what is called a rack-scale architecture, similar to those developed by Intel, Dell, the Scorpio alliance of Baidu, Alibaba, and Tencent, and the Open Compute Project spearheaded by Facebook are all working on in one form or another.
The secret sauce in the DriveScale setup is an adapter card that employs a Broadcom Ethernet controller, a Texas Instruments baseboard management controller, and an LSI Logic SAS storage controller. Four of these cards are plugged into a 1U chassis and hook into a 10 Gb/sec Ethernet switch in the rack to bridge between SAS-based JBOD storage arrays and dual-port Ethernet adapters on the servers. The DriveScale software stack includes a storage agent that runs in the Linux operating system user space of each server and that presents the JBOD capacity allocated to that server as if it were directly attached to the machine like local storage, even though it is hooked to it over Ethernet. The DriveScale stack also runs a management server to configure these agents and allocate storage in the fly to servers in the cluster, and also has a call home feature that can collect metadata and send it back to DriveScale to help the company learn about optimal configurations for specific machines and workloads and feed recommendations, fueled by machine learning systems that DriveScale has built, back to its customers. With its first few handfuls of customers going into production now, DriveScale is just starting to collect this metadata and Banman says that most customers are happy to allow for the collection of this data.
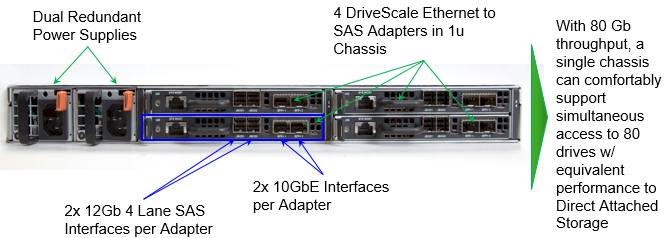
The DriveScale architecture decomposes and recomposes the storage within a single rack, and does not span multiple racks because the 10 Gb/sec switches that enterprises currently use in the racks do not have enough bandwidth or low enough latency (typically) to support the multiple hops that would occur between a server and a virtualized JBOD somewhere down the row of racks. This could change over time as faster Ethernet switching goes more mainstream.
The DriveScale stack seems to be reasonably priced, considering what it does and how much money it might save companies that are currently overprovisioning the storage on their cluster nodes. Each DriveScale adapter card costs $6,000 to acquire, and then there are annual subscription fees tied to the software stack that run to $2,000 per server linked to the adapters and $20 per disk spindle. The adapter card has two 10 Gb/sec ports, and a single DriveScale appliance offers 80 Gb/sec of aggregate bandwidth that Banman says is sufficient to drive about 80 disk drives at the same performance as local drives attached to servers.
In benchmark tests, DriveScale took servers equipped with two Xeon E5-2650 v1 processors with 64 GB of DDR3 memory and a dozen SAS disks in a JBOD array. In one case, it linked to the JBOD array using an LSI SAS 3008 host bus adapter and in another it linked using its DriveScale adapter and then fired up the TestDFSIO Hadoop throughput benchmark test on both machines. Here is how the machines stacked up:
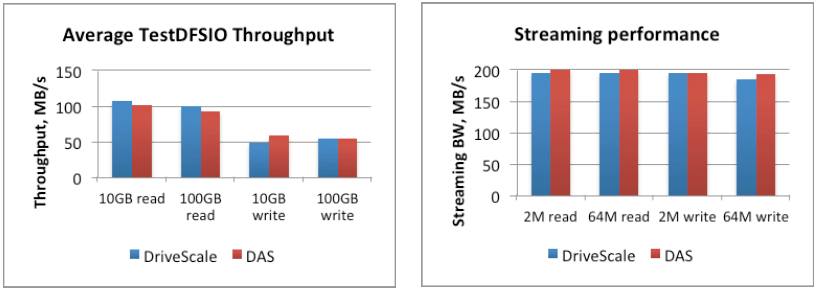
On the tests, the DriveScale approach was able to sustain 156,000 IOPS for reads and 164,000 IOPS for writes across a four-card chassis, and this was without a lot of tuning, according to Banman. The incremental latency added by the DriveScale adapters over real SAS adapters was around 205 microseconds for reads and 184 microseconds for writes. The adoption of flash-based SSDs to JBODs, which DriveScale is working on, will drive up IOPS and the overhead is small enough to not negate the latency benefits of those SSDs. Banman hints that other parts of the cluster infrastructure could be similarly decomposed and recomposed, and SSDs seem like the next logical step as do accelerators such as FPGAs and GPUs.
As for software stacks, DriveScale is focused initially on Hadoop clusters but is planning to expand support out to NoSQL data stores, OpenStack clouds, traditional HPC clusters and their own simulation and modeling applications. Basically, any distributed application can be brought onto this infrastructure.
Converged Infrastructure Morphs To Composed
The people behind DriveScale have been thinking about scale-up and scale-out infrastructure for a long time. The company was founded in March 2013 by Tom Lyon and Satya Nishtala. Lyon, who is chief scientist at DriveScale, was employee number eight at Sun Microsystems and among other things worked on the SunOS variant of Unix and Sparc processor design. Nishtala, who is chief technology officer at DriveScale, was the lead designer for Sun’s workstations and workgroup servers as well as its storage line.
Lyon and Nishtala worked for Banman at Sun, who was general manager of desktop systems at Sun back in the day, and significantly were both founders of the Nuovo Systems spin-out that created Cisco’s UCS platform and then was spun back into the networking giant as it planted its flag in the server space in early 2009. Duane Northcutt, vice president of engineering at DriveScale, was a hardware architect at Sun and also vice president of technology at Kealia, one of a number of companies created by Sun co-founder Andy Bechtolsheim that was brought back into Sun in 2004 to give it the Opteron-based “Constellation” server and storage platforms. Sun co-founder Scott McNealy and Java creator James Gosling are advisors to DriveScale as well, rounding out the Sun connections.
DriveScale raised $3 million in seed funding and has just closed another $15 million from Pelion Venture Partners, Nautilus Venture Partners, and Foxconn. Interestingly, Foxconn is not only an investor in DriveScale, it is the manufacturing partner for the DriveScale adapters and appliances and is one of the early customers, using it to virtualize the storage in its own clusters. DriveScale has 18 employees and has about a dozen proofs of concept running with another two dozen prospects at the moment. Ad serving company AppNexus, which has more than 1,300 nodes across multiple Hadoop clusters, will be using DriveScale to consolidate those clusters.

Cisco Fights The Merchant Network Chip Makers On Their Own Turf
There is nothing wrong with buying a compute, storage, or networking appliance where the ASICs and software both come from the same supplier. There is, however, something wrong with this being the only choice and that is what the long battle to break open the switch by the hyperscalers and …

Big Iron Will Always Drive Big Spending
Starting way back in the late 1980s, when Sun Microsystems was on the rise in the datacenter and Hewlett Packard was its main rival in Unix-based systems, market forces compelled IBM to finally and forcefully field its own open systems machines to combat Sun, HP, and others behind the Unix …

Mixed Results For The Datacenter Thundering Thirteen In Q4
We have been tracking the financial results for the big players in the datacenter that are public companies for three and a half decades, but starting last year we started dicing and slicing the numbers for the largest IT suppliers for stuff that goes into datacenters so we can give …
Be the first to comment