

Among the emerging themes for 2019 in the datacenter, one of them is that NVM-Express is finding its place in the storage hierarchy. NVM-Express started out as an important interconnect inside of storage systems, but its extension across network fabrics is very likely going to have a more transformative effect on datacenters as it allows for storage to be disaggregated from compute, enabling the kind of disaggregation and composability that, thus far, only the biggest cloud builders and hyperscalers could afford to create for yourself.
This time around, non-volatile storage is truly going mainstream as flash is getting increasingly cheaper and the commercial grade NVM-Express over Fabrics (NVMe-oF) implementations that are coming to market are arguably better than what the hyperscalers and cloud builders started creating for themselves many decades ago. And in some cases, such as with Lightbits Labs, which is launching its first product after years of developing the NVM-Express over TCP/IP protocol, the very same people who created the ASICs and architectures for the vast flash farms at the hyperscalers have been working on the commercial grade stuff for the past couple of years.
Rather than run NVM-Express storage over Fibre Channel or InfiniBand or even Ethernet with RoCE (the implementation of the Remote Direct Memory Access, or RDMA, protocol created for InfiniBand that works with Ethernet), Lightbits Labs, which has just dropped out of stealth mode, decided from the get-go to cut out all of the special stuff and make NVMe-oF work over plain vanilla Ethernet using the TCP/IP protocol that is the backbone of the Internet.
This was a bold and perhaps counterintuitive choice, especially given the relentless focus on performance in the upper echelons of computing. But as Google and other hyperscalers have taught us, the tail latency is what kills you in the long run in a distributed computing system, so instead of focusing on using extreme bandwidth and the absolute lowest latency – things that are required for modern HPC and AI clusters – Lightbits Labs went the other way and implemented its own TCP/IP stack such that it offers the kind of performance you would expect from high speed networks but with more predictable latencies that, when all is said and done, give flash in network-attached storage servers that are remote from server nodes performance that is indistinguishable from directly attached flash storage inside of a server node.
This breaks flash free from the server, allowing for compute and storage to be scaled independently and on the scale of a datacenter, not just a rack or a row of iron.
This is an important distinction, Eran Kirzner, co-founder and chief executive officer at Lightbits Labs, tells The Next Platform. And Kirzner should know, since he was part of the team at PMC-Sierra that created the ASICs and software that helped several hyperscalers disaggregate their flash from their servers, and he worked with Kam Eshghi, who was senior director of marketing and business development for the first NVM-Express flash controller created by Integrated Device Technology, which was bought by PMC-Sierra. Eshghi went on to run business development for DSSD, the high performance flash appliance startup that was the first company to commercialize (with limited success) NVM-Express flash, a company that was bought by EMC because of its potential for HPC-style flash storage; DSSD became part of the Dell collective, never to be seen again.
Another co-founder at Lightbits Labs, Avigdor Willenz, has a long history in chips, starting out at networking chip maker Galileo Technology almost three decades ago (which was eaten by Marvell), who also did a stint at IDT, and who was a cofounder of Arm chip maker Annapurna Labs, which was bought by Amazon in 2015 to make its cloud division’s Nitro SmartNIC motors and now the Graviton Arm server processors. (Lightbits Labs was founded after the Annapurna Labs acquisition was done, back in early 2016.) Willenz is most recently chairman of the board and lead investor in AI chip maker Habana Labs. The third cofounder at Lightbits Labs, Muli Ben-Yehuda, who is the company’s chief technology officer, spent a decade at IBM Research in various roles relating to virtualization and storage and more recently was chief scientist at Stratoscale, a company that has mashed up a variant of hyperconverged storage with the OpenStack cloud controller.

Lightbits Labs current has 70 employees, with 63 of them working in engineering and with 15 patents pending. It is headquartered in Israel with offices in New York and San Jose, and as it dropped out of stealth this week, it said that it had completed its Series B round of venture funding from SquarePeg Capital and Walden International and strategic investments from Cisco Systems, Micron Technology, and Dell, for a total haul to date of $50 million.
“We have more than ten years of experience with NVM-Express,” says Kirzner. “NVMe over Fabrics came after direct attached NVM-Express, which was part of our team’s first product and which used PCI-Express switching internally, and worked over Fibre Channel and RDMA on Ethernet. But we found several problems with these approaches. First, nobody is going to open up the thousands or tens of thousands of servers that they have an put in SmartNICs to enable NVMe over Fabric. To get RoCE to really work, you need to customize the network, you need to add traffic engineering and you need to add a switch that supports the proprietary flow control. And it is more expensive. We wanted to create something that was less expensive and that could replace iSCSI, and we think NVMe over TCP/IP will be dominant.”
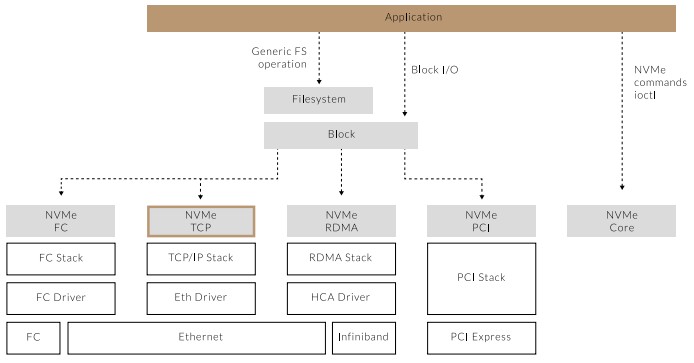
The comparison to the DSSD D5 array, which Kirzner hints at above is apt. The architectures of the D5 array from DSSD and the hardware and software stack from Lightbits Labs are similar in many regards and quite different in important ways.
The flash modules in the D5 array, which was a block device that can have file systems loaded on top of it, had an out-of-band control plane running on Xeon processors and had a massive PCI-Express switching mesh in the center, delivering 10 million IOPS with an average latency of under 100 microseconds, which was accomplished by chopping out anything extraneous in the storage and network stacks. This was up to 3X to 10X lower latency than other flash arrays could deliver three years ago when the D5 was announced. That control plane did garbage collection and wear leveling across the entire pool of flash in the device at the same time, not on an individual flash module basis, and servers hooked into the D5 array with fast network pipes in a similar manner to a traditional SAN. The D5 did not have de-duplication or data compression – it was all about maximizing performance.
The LightOS storage stack is inspired by many of these ideas, but turns it all inside out. Flash storage is still aggregated in storage servers that run the software stack, which includes a distributed Global Flash Translation Layer, the kind of microcode that is usually etched into a controller for a single flash module and that virtualizes a pool of flash SSDs enclosed in a series of storage servers attached over an Ethernet network to be treated as a single pool of storage. Rather than only scaling to one or two racks, as was the case with NVM-Express over Fibre Channel or RDMA, the NVM-Express over TCP/IP implementation that Lightbits Labs has cooked up can provide disaggregated flash storage across tens of thousands of nodes with a maximum of five or six hops across the network in under 200 microseconds. That may be twice as slow as the DSSD D5, but it is probably going to be one or two orders of magnitude cheaper. So that is a fair trade.
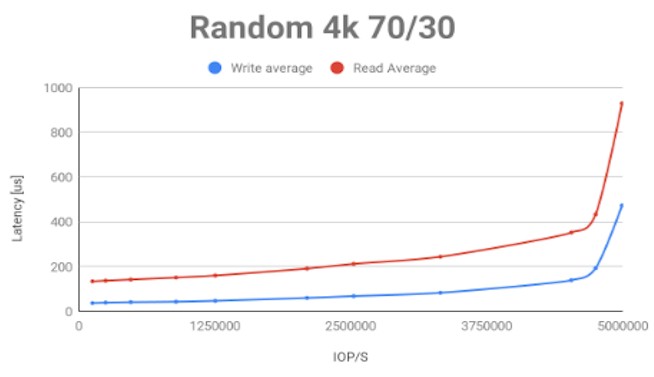
“The write latencies being below 200 microseconds is super important for logging, time series databases – any intensive application that has a lot of updates,” explains Kirzner. “Think about a hyperscaler that has to monitor every click of ever user, tons of information, and then they do a ton of analytics on that. Our writes are below 400 microseconds, and the other nice thing in these curves is that they stay flat all the way, and even when you hit 5 million IOPS, you are still below 1 millisecond.”
Equally importantly, the tail latencies for reads and writes are pretty low. Here is what the distribution looks like for reads and writes using the “canonical” queue depth equals one setting:
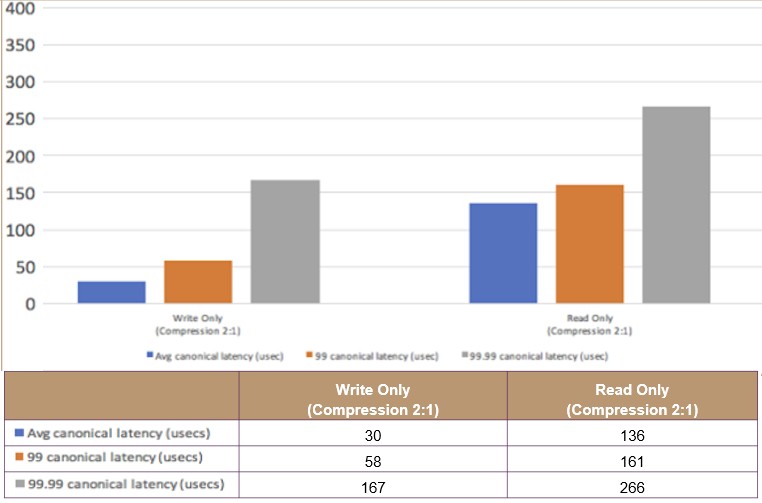
The average speed of 30 microseconds for a write and 136 microseconds for a read is pretty good for the TCP/IP stack, and the latency does not drift up too badly for the 99th percentile or the 99.99th percentile, either. (We wonder if the spike comes at the 99.999th percentile, though?)
The important thing about the LightOS stack is that in addition to virtualizing the flash storage pool across networked storage servers, the Global FTL embedded within it provides many of the services that were missing in the D5 array. These include thin provisioning of storage volumes, so you only provision what you use, as well as data compression to crunch data and get more out of the flash capacity; typically a 2:1 compression with the datasets Lightbits Labs is tackling. The Global FTL stack also has sophisticated wear leveling techniques so even low-cost, low endurance flash devices, such as those emerging based on QLC flash, can be used reliably, and also has erasure coding that runs at line rate for data protection and quality of service partitioning to ensure consistent latency and IOPS for workloads as well as multi-tenant isolation. RAID data protection within a storage server is also supported for the truly (and often justified) paranoid.
With all of these features, Kirzner says that the LightOS setup can drive up flash utilization to 70 percent to 80 percent of capacity and IOPS, compared to about 30 percent to 40 percent for alternatives, and when you add in that it is just running over Ethernet and doesn’t require any changes in the server adapters or switches, this is a big cost savings. The LightOS stack does require a specially tuned TCP/IP stack that runs in the user space in Linux on the storage servers, parts of which have been open sourced and parts of which will be sold under enterprise support contracts.
The LightOS NVM-Express over TCP/IP stack is going to be made available in a number of different ways, but completely open source code is not one of them. (Lightbits Labs has to make a living, too.) The software will be licenses on a per node or on a capacity under management basis, and for those customers who want to offload the processing from their storage servers so they can embed other functions on them and use their Xeon or Arm cores to do that work, Lightbits Labs has dumped parts of the LightOS code onto an FPGA card that can slide into the storage server to accelerate data de-duplication and erasure code routines as well as speed up the proprietary TCP/IP stack and the Global FTL for the flash pool. This is called the LightField card, by the way, and Kirzner won’t say if it is an Intel or Xilinx FPGA under the covers. (You have a 50-50 chance of being right with your guess, and I am guessing Xilinx.) About half of the customers who have been testing the LightOS stack so far have been going with the LightField accelerator card, but interestingly, no customers using AMD Epyc processors have done so because they feel like they have the extra cores to burn on the CPUs in their storage servers. Customers can build their own storage servers, or buy a preconfigured one, called a LightBox, from Lightbits Labs. Our guess is that Dell and Cisco iron are supported for the preconfigured iron, considering that they are investors.
All we know is that one OEM is already certified and shipping LightOS on their systems, but Kirzner can’t reveal who it is. More will no doubt follow, and maybe one or two might get out a checkbook and snap up Lightbits Labs before someone else does.

Storage Is Going Have To Deal With Clouds And Edges
While on-premises datacenters are strategic to large enterprises, and will be for the foreseeable future, hybrid clouds and the edge are also an increasingly important part of the IT platform portfolio. But the road out of the datacenter and into the future with clouds and edges is not always an …
Excelero Storage Deal Gives Nvidia A Nearly Complete HPC/AI Stack
In case it is not immediately obvious, over the past decade Nvidia has been transforming itself from a component supplier into a complete platform provider. Such a move was not necessary – you can expect for AMD to be pretty gun shy about such a move after is acquisition of …

Mainstreaming Fast Flash Clusters For Fun And Profit
One of the common themes – and one could say even the main theme – of The Next Platform is that some of technologies developed by the high performance supercomputing centers (usually in conjunction with governments and academia), the hyperscalers, the big cloud builders, and a handful of big and …
The D5 was an object store – with one of the many supported objects being a Block.