

As GPU-accelerated servers go, Nvidia’s DGX-2 box is hard to beat. Its 16 V100 GPUs glued together with NVLink provides two petaflops of tensor floating point performance or 125 teraflops of double precision performance. Feeding those GPUs is as much as half a terabyte of stacked HBM2 memory that can deliver up to 16 TB per second. But if you want to connect multiple DGX-2 servers together and run I/O intensive workloads through that cluster, you’re going to need some additional hardware and software to make sure those GPUs aren’t starved for data.
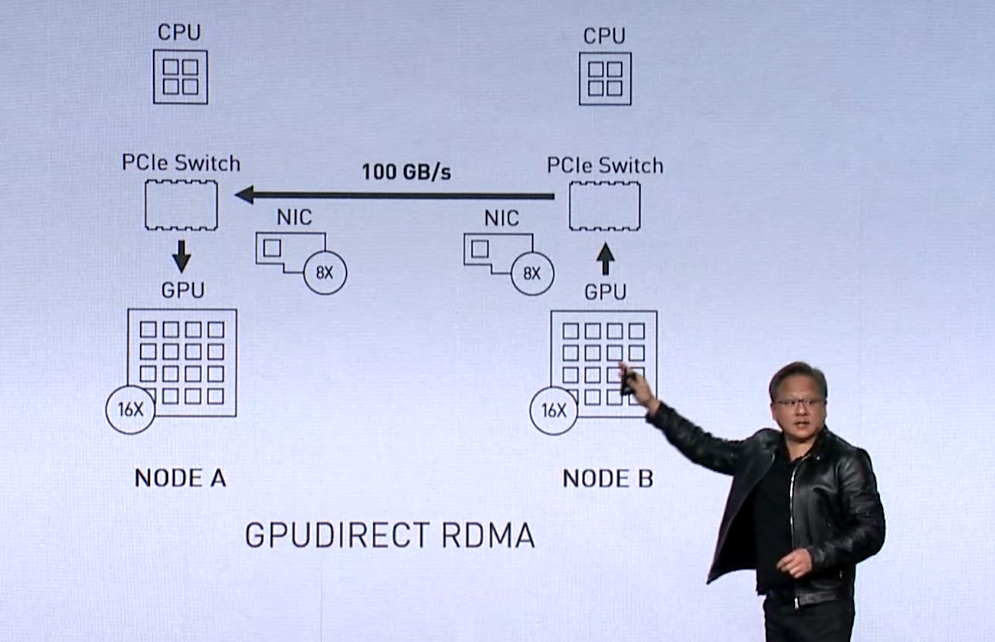
Basically, that’s because the DGX-2 was designed as a scale-up architecture, not a scale-out one. Which means there is an inherent data bottleneck getting in and out of that server. Fortunately some of the pieces needed to make a DGX-2 cluster deal with high levels of I/O already exist: Mellanox NICs, which provide the high performance network interface hardware and RDMA support; GPUDirect, an RDMA technology that supports a direct data path between GPUs and peer devices over PCI-Express; the Nvidia Collective Communications Library (NCCL), a package that provides optimized communication for multi-GPU and multi-node setups; and GPUDirect Storage, which establishes a direct path between GPU memory and storage. (Actually, GPUDirect Storage is currently only available to early-access customers and is slated to be more broadly available in the first half of 2020.)
The piece that was missing up until now was a software layer that brought all of these elements together and provided storage I/O acceleration for scaled-out GPU applications. At SC19 this week, Nvidia CEO Jensen Huang announced such a beast, which the company calls Magnum IO. Basically, it’s a software suite that provides an API designed to relieve the I/O bottleneck for these multi-GPU servers. According to Huang, Magnum IO is “one of the biggest things we’ve done in the last year.” The rationale for that statement is that few other technologies that they’ve developed recently are able to accelerate GPU-accelerated workloads to this degree – up to 20X in some cases.
The new software suite is aimed at data scientists and researchers who are dealing with large datasets use in artificial intelligence and other high performance computing applications. To help that along, Magnum IO interfaces with Nvidia’s CUDA-X software stack, which provide GPU acceleration across a wide range of commonly used AI and HPC packages.
As a practical matter, the external storage and file system has to hold up its end of the performance bargain as well. The initial storage partners include DataDirect Networks, Excelero, IBM Spectrum, Pure Storage, and WekaIO, which gives you some sense of the level of storage performance Nvidia has in mind. The general idea is to take advantage of non-volatile storage (NVM-Express, in particular), either standalone or in network fabrics.
At the hardware level, the requisite data bandwidth is delivered by equipping the GPU server with lots of fast NICs, in the case Huang described, using eight 100Gbps Mellanox adapters per DGX-2 server. Presumably, Magnum IO will work with other types of multi-GPU servers, given that Nvidia has listed Cray/HPE, Dell EMC, IBM, Lenovo, Inspur, Penguin Computing, Atos, and Supermicro, as Magnum IO OEM partners. Huang also mentioned they are looking at other NIC providers besides Mellanox, but it’s unclear who he has in mind.
The eight-NIC, DGX-2 setup that he used as an example supplies a whopping 100 GB/second of bandwidth to and from the server. “That bandwidth is of the order of the bandwidth of memories on CPUs,” Huang pointed out.
Magnum IO can also be layered underneath RAPIDS, Nvidia’s accelerated data science stack that we reported on last year. Conveniently, this set of software also supports multi-GPU, multi-node configurations. It’s already in use at a number of prominent HPC sites, including Oak Ridge National Lab, NASA, San Diego Supercomputing Center, and Berkeley Lab.
Applying Magnum IO to the TPC-H metric, a decision support benchmark used to measure query performance across 10TB databases, sped up execution by a factor of 20. On a real-world structural biology application using the Visual Molecular Dynamics (VMD) package, Magnum IO boosted runtime performance by 3X.
Magnum IO has also been used to accelerate the visualization of the Mars Lander, which Huang claimed as “the world’s largest interactive volume visualization.” In this setup, four DGX-2 servers, which are capable of streaming data at 400 GB/second, were used to ingest 150 TB of simulation data.

With these types of Magnum IO-orchestrated applications in mind, Nvidia developed a reference architecture of sorts, which Huang referred to as a “supercomputing analytics Instrument.” In its initial form, it consists of a DGX-2 server outfitted with eight Mellanox 100Gbps NICs and 30 TB of NVM-Express storage. Nvidia doesn’t appear to be selling such a system at this point (at least, no pricing was offered), although presumably one could assemble such a system without too much trouble. Again, we think the assumption here is that Nvidia’s OEM partners will pick up on this and offer their own versions.
These systems won’t come cheap – a single unadorned DGX-2 server retails for $399,000 — but if you’re looking for scale-out GPU-acceleration and you have big datasets to ingest, this could fit the bill. We expect Nvidia will be talking a lot more about these technologies in the future.


One On One With Jensen Huang: Nvidia, The Platform Company
While a lot of ideas are ancient, some are relatively new and can come from only a modern context. Platform is one such concept, and given what we care about here at The Next Platform, it bears some analysis as we consider the company the Jensen Huang, co-founder and chief …
Nvidia Picks Up The Pace For Datacenter Roadmaps
Heaven forbid that we take a few days of downtime. When we were not looking – and forcing ourselves to not look at any IT news because we have other things going on – that is the moment when Nvidia decides to put out a financial presentation that embeds a …

Thinking Outside Of The Box With The Jupiter Supercomputer Datacenter
The concrete has been poured and the first containers that will house the exascale-class “Jupiter” system at Forschungszentrum Jülich in Germany are being lifted into place for the modular datacenter that will be the home of the massive machine. These days, given the complexities and densities of compute, power, and …
Be the first to comment