

When money is really no object, and the budget negotiations involve taking a small slice of your personal net worth of $7.5 billion out of one pocket and putting it into another, and you have the technical chops to understand the complexities of molecular dynamics, and have a personal mission to cure disease, then you can build any damned supercomputer you want.
So that is what David Shaw, former computer science professor at Columbia University and quant for the hedge fund that bears his name, has done once again with the Anton 3 system.
The Anton 3 processors, their interconnect, and the complete Anton 3 system, which were delivered last September to DE Shaw Research, the scientific and computer research arm of the Shaw empire, were on display at the Hot Chips 33 conference this week. The system is a shining testament to the co-design of hardware and software and finely tuning both for the modeling of very specific physical processes to better understand them.
DE Shaw Research has been pretty secretive about the three generations of Anton systems it has developed. But like a hyperscaler, every couple of years it gives a peek into the architecture. And it is always fascinating.
The current Anton team is just shy of 40 people, who design, build, test, and program this “fire-breathing monster for molecular dynamics simulations,” as Adam Butts, the physical design lead at DE Shaw Research, called the Anton 3 system. When you see the benchmark test results that pit the Anton 3, etched in seven-nanometer processes at Taiwan Semiconductor Manufacturing Corp, against its predecessors and the best GPU-accelerated supercomputers in the world, you will see that Butts is not exaggerating.
We can’t wait to see DE Shaw Research get on a proper cadence and push Anton 4 down to five nanometers and Anton 5 down to three nanometers. More importantly, we eagerly anticipate some architectural innovations that drive performance further with Anton 6 when the nanosheet transistor density bump we expect in a few years, maybe at two nanometers, runs out of gas. It would be nice if the cadence of chip rollouts was better than whenever the company got around to it, too. A two-year cadence would be great. Show ’em how it is done, Shaw.
That Anton exists at all, that David Shaw even bothered and has now funded three generations of custom supercomputers, is a testament to the enlightened self-interest that wealth can often bring. The innovation has been thoughtful and thorough, elegant and beautiful. But the pace of innovation has not been blistering; it’s not even a light sunburn. The Anton 1 chip taped out in 2007, five years later the Anton 2 chip came out, and it was another eight years until Anton 3 taped out last September.
And, perhaps more significantly, the Anton machines are not widely distributed, much less sold commercially. In Greek, the name Anton (which has its roots in the Roman name Antonius and the Italian name Anthony) means “priceless” or “of inestimable worth,” but we know the value of these systems. Particularly in a world that is living through a global pandemic and that is probably going to see such things more frequently from here on out. DE Shaw Research has one of each generation of Anton machines (at least) and the Pittsburgh Supercomputing Center has an Anton 2 machine, which we covered back in December 2016. That’s it as far as we know.
These Anton machines are so good at what they do they should be manufactured in the volume necessary to advance the sciences of biology and medicine. Period. And that could help fund future research in the Anton machines, making them independent of their creator’s cash flow. Shaw has the luxury of not needing to make a profitable company to support Anton supercomputers, but we do not have the luxury of not having more researchers benefit from the architecture he has spawned. Science is not supposed to be a toy for the rich, but a tool for the world. And it would be nice to have a powerful tool doing undeniably and unquestionably good things, which we can’t always say about the massive distributed computing systems here on Earth.
Inside The Anton Architecture
To understand how the Anton chips work, you have to understand what molecular dynamics simulations are doing a little bit, and Butts walked the Hot Chips crowd through the finer details. Given a soup of a set of complex molecules floating in a sea of water atoms, like this:

You start with initial conditions of location and velocity and using Newton’s laws of motion as well as the nature of the bonds between atoms and the interactions between atoms and molecules on each other with both near electrostatic and distant electrostatic force fields, you figure out how everything is affecting everything else and predict the motion of the collection of molecules. Easy peasy, right? And this is a simple example that doesn’t involve a more complex molecular machine (as elements of a cell certainly are) such as when RNA tickertape runs through ribosomes, which transcribe those instructions into actions that create proteins from amino acids.
To move this simple problem from being “intractable to merely ridiculous,” as Butts put it, you do what all HPC simulations and models do, and what all science does. That is to make simplifications that can be mathematically described and then run through a massively parallel, super-fast set of transformation and matrix math engines that can do calculations the human brain can’t with any kind of speed or accuracy. There are probably a few people who can do a Fourier transform in their head, but we don’t know them, and they can’t do it all day at a rate sufficient to simulate a complex of a hundred atoms, much less the hundreds of thousands to millions that are necessary to do interesting stuff. Billions and trillions would be more useful in an exponential way, we think.
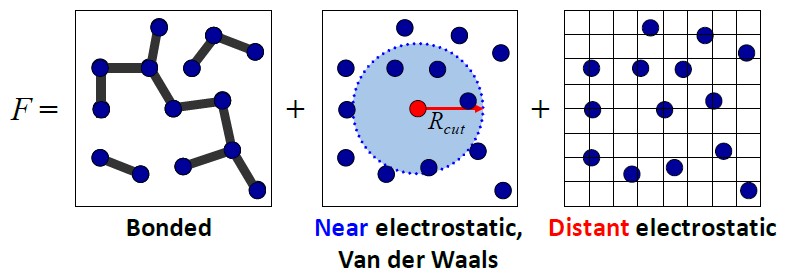
There are several different kinds of calculations that must be done to simulate collections of atoms and molecules, and they correspond to the kind of strong and weak bonding that happens between atoms. Atoms have electric charges, and the forces between them are proportional to product of their charges, subject to the inverse square law, which means that product has to be divided by the square of the distance between any two atoms. The force field is the sum of all of the pairwise interactions across these atoms, and the field is updated at a granularity of femtoseconds — quadrillionths of a second, or about the time it would take a single photon to traverse the length of a typical virus.
Atoms are also bonded together more tightly by chemical bonds and move through space and time, bending and folding and twisting in interesting ways. Between these extremes, you get near-range electrostatic forces that are somewhere between the distant electrostatic forces. The one we all know from high school chemistry is the Van der Waals force, where hydrogen atoms in one water molecule get cozy with an oxygen atom in an adjacent water molecule with a kind of stickiness that is, metaphorically speaking, magnetic. The Van Der Waals forces drop off quickly, and that means rather than do a truly impossible amount of quantum mechanical calculations you can do a rough field approximation over a short range for each atom in the molecules. Different parts of the Anton compute complex do different parts of these calculations, and up to 512 of these Anton processors — be it Anton 1, 2, or 3 — can be ganged up to simulate a fairly large number of atoms. With Anton 3, DE Shaw Research is up to 56,320,000 atoms, which is a factor of 239.1X more than the Anton 1 supercomputer could do and a factor of 13.8X better than the Anton 2 supercomputer could do.
With the move from the Anton 1 to the Anton 2, DE Shaw Research made some pretty big architectural changes. As well as moving from 90-nanometer chip manufacturing processes down to 40 nanometers, which allows the various compute elements on the architecture to increase by 2X to 5X, depending, SRAM memory on the chip increased by 8X and clock speeds for the compute elements increased by 1.7X to 3.4X. That’s how the simulated atom count per chip rose from 460 with the Anton 1 to 8,000 with the Anton 2. The Anton 2 chip was also bigger, at 410 square millimeters, by 37.1 per cent, and because of the larger chip and higher clock speeds, the Anton 2 weighed in at 190 watts compared to 30 watts for Anton 1.
No one can get around the laws of physics that govern chip design. But you can just grab the same levers and pull hard, which is what DE Shaw Research did with the Anton 3 chip. No more hanging back on mature chip processes, no more trying to be modest about power consumption. Butts and the rest of the DE Shaw team pulled out the stops, moving to a seven-nanometer process that allowed it to radically jack up the transistor count to 31.8 billion on a single chip while at the same time cranking the clocks by 70 per cent to 2.8 GHz, with a hope to push it up higher. The power consumption almost doubled to 360 watts, which is expected. Every compute engine we know of is creeping up the power with each successive generation. There is no other way to do this until we have a radically new kind of chip technology.
Before diving into the details of the Anton architecture, here is a nice summary table that describes the three different Anton chips:
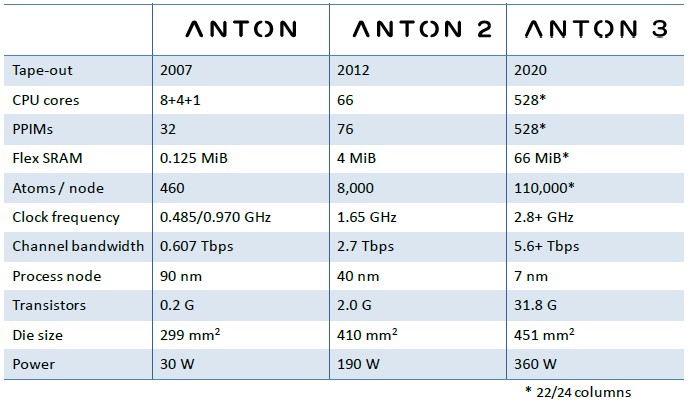 If you squint at this table, you can see Anton 4 at five nanometers in 2022, Anton 5 at three nanometers in 2024, and Anton 6 at two nanometers in 2026, with chiplet architectures doing interesting stacking to really drive performance. Beyond that, it is out of the range of our bifocals …
If you squint at this table, you can see Anton 4 at five nanometers in 2022, Anton 5 at three nanometers in 2024, and Anton 6 at two nanometers in 2026, with chiplet architectures doing interesting stacking to really drive performance. Beyond that, it is out of the range of our bifocals …
To understand Anton 3, you really need to understand Anton 2, which Butts reviewed for the sake of the Hot Chips audience and which was by far the best machine at doing molecular dynamics simulations in the world. Until Anton 3, of course. Anyway, here’s the die shot and block diagrams for the elements of the Anton 2 chip:
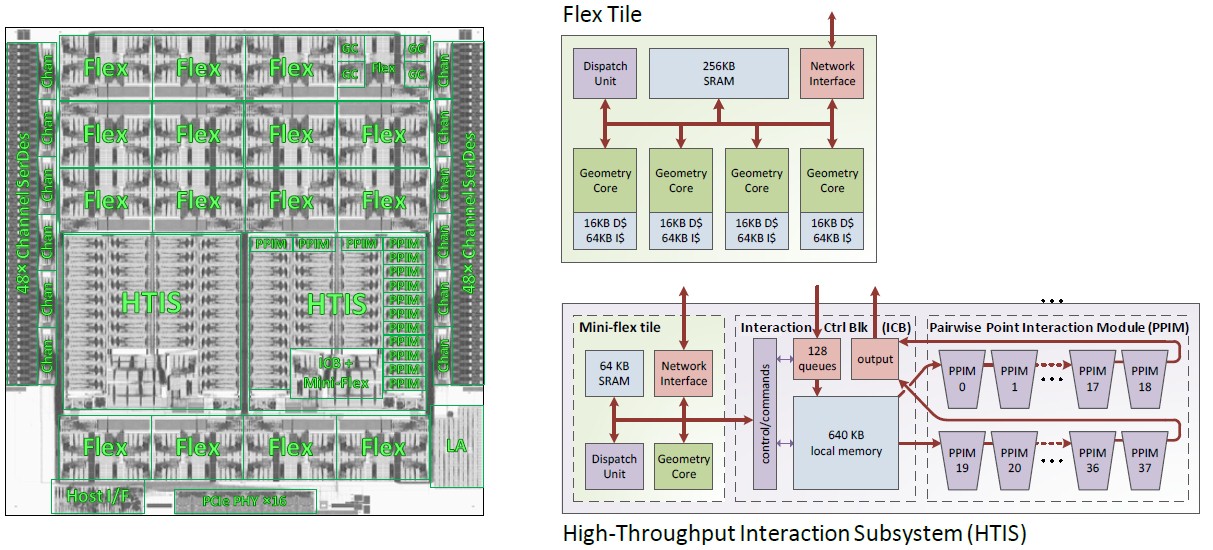
There are two kinds of computational elements in the Anton 2 chip. The Flex Tile looks like a multicore CPU, but its Geometry Cores, or GCs, are designed specifically to run the vector geometric computations that occur frequently in molecular dynamics code. In Anton 2, the Flex Tile had four GCs and there were a dozen Flex Tiles for a total of 48 GCs on the die. Each GC had L1 data and instruction cache, plus a shared L2 cache and a dispatch unit for allocating work and a network interface to link to other elements of the Anton 2 chip.
The High Throughput Interaction Subsystem, or HTIS, was designed to do the pairwise point interaction processing between two particles to reckon the force between them. There were two HTIS blocks on the Anton 2 chip, each with 38 Pairwise Point Interaction Modules, or PPIMs, and a Mini Flex Tile to handle I/O for each block of PPIMs.
“We rely heavily on 32-bit fixed point operations, and vector forms of those,” explained Brannon Batson, a peer of Butts on the hardware design and engineering team who took questions after the session. “But in our specialized arithmetic pipelines, we are all over the place. There are places where we have 14-bit mantissas with five-bit exponents. There are places where we are in log domain. Since we are doing unrolled pipelines, we trim and prune precisions very carefully on a stage-by-stage basis, based on a very careful numerical analysis. And that’s where a lot of our value proposition comes from in terms of computational density.”
The Anton 2 chips linked together with a pair of 48 channel SerDes, which run at 15Gb/sec.
With the Anton 3 chip, the chip designers at DE Shaw Research broke down the PPIM processing into two classes: near distances where the Van Der Waals force prevails, versus far distances where the normal electrostatic forces can be averaged out over greater areas and require less computation. So the PPIM was carved up into one big math unit and three small ones, and this effectively doubled the calculation rate of the pairwise force calculations at a normalized clock frequency. Add in high clocks and more compute elements, and the throughput of the Anton 3 device is obviously a lot more than with the Anton 2 chip.
With the Anton 3 chip, the compute elements were all concentrated down to a single core tile, each with two modified PPIMs and two GCs plus a new chip that calculated the force of chemical bonds. The GCs had 128KB of L2 cache each instead of a giant shared L2 cache, and this L2 cache segment fed directly into a PPIM block. A pair of GC/PPIM blocks were put on a tile (a logical one, not a physical one), and the tiles are connected in a mesh network using an on-chip router. Like this:
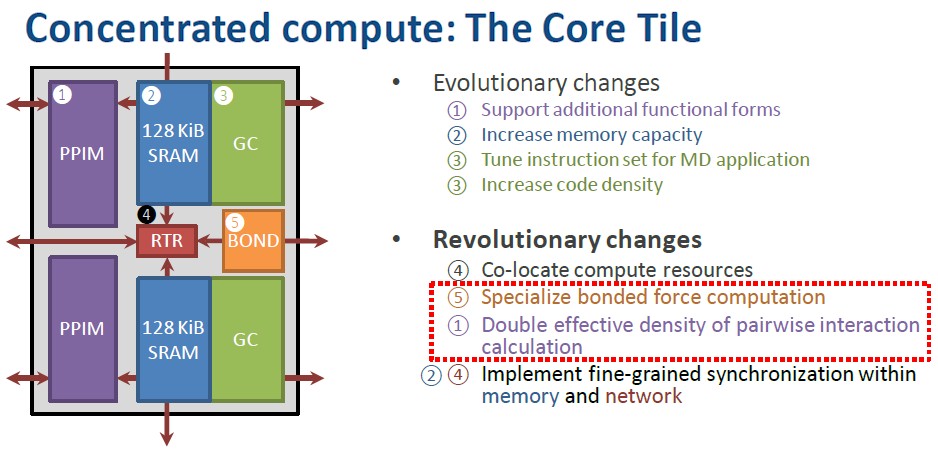
Communication inside the chip is done on the mesh and outside of the chip is now done through a collection of edge tiles (again, this is a monolithic die and that is a logical tile, not a physical one). The edge tile looks like this:
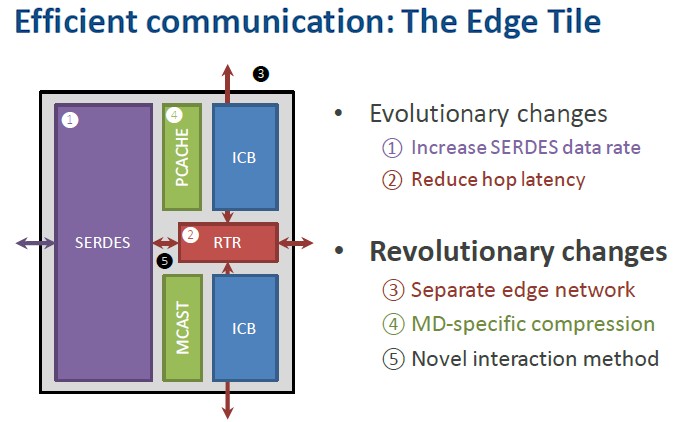
The bandwidth on the communications array has been quadrupled over Anton 2, first by adding compression techniques specific to molecular dynamics, which gives a factor of 2X improvement in effective bandwidth and then by literally clocking the SerDes by another 2X to 30Gb/sec using NRZ encoding. Switching to PAM4 encoding would get that to 60Gb/sec in a next-generation machine, and boosting it to a native 60Gb/sec and then using PAM4 encoding to get to 120Gb/sec is probably something that needs to be considered for future Anton machines.
Here is the die shot of the Anton 3 chip, with zooms of the edge tile and the core tile:

There are two columns of twelve edge tiles, left and right of the chip, and there are 24 columns of core tiles that are twelve cores high for a total of 288 core tiles. That’s 576 GCs and 576 PPIMs in total for the Aton 3, versus 48 GCs and 76 PPIMs for the Anton 2. For yield purposes, only 22 of the 24 columns of compute tiles are activated on the first stepping of the Anton chips, so there is a latent 8.3 per cent performance boost in the Anton 3 over current performance levels if yields on the seven-nanometer processes can be improved so the whole chip works.
The several process shrink jumps DE Shaw Research made really allowed this Anton 3 beast to have a lot of compute and communication engines crammed in.
Here is what the Anton 3 node looks like:
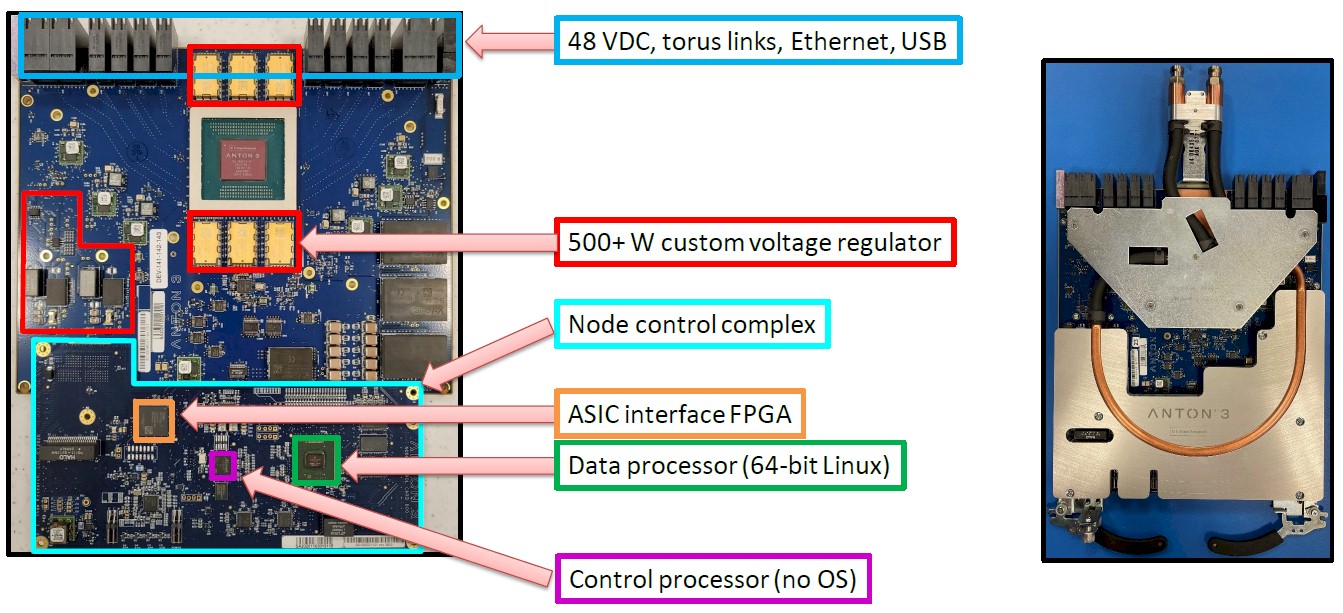
The nodes are hanged up in a chassis with a backplane and interlinked in a 3D torus network using electrical signaling internal to the chassis.

And here is what that 3D torus interconnect looks like all cabled up:
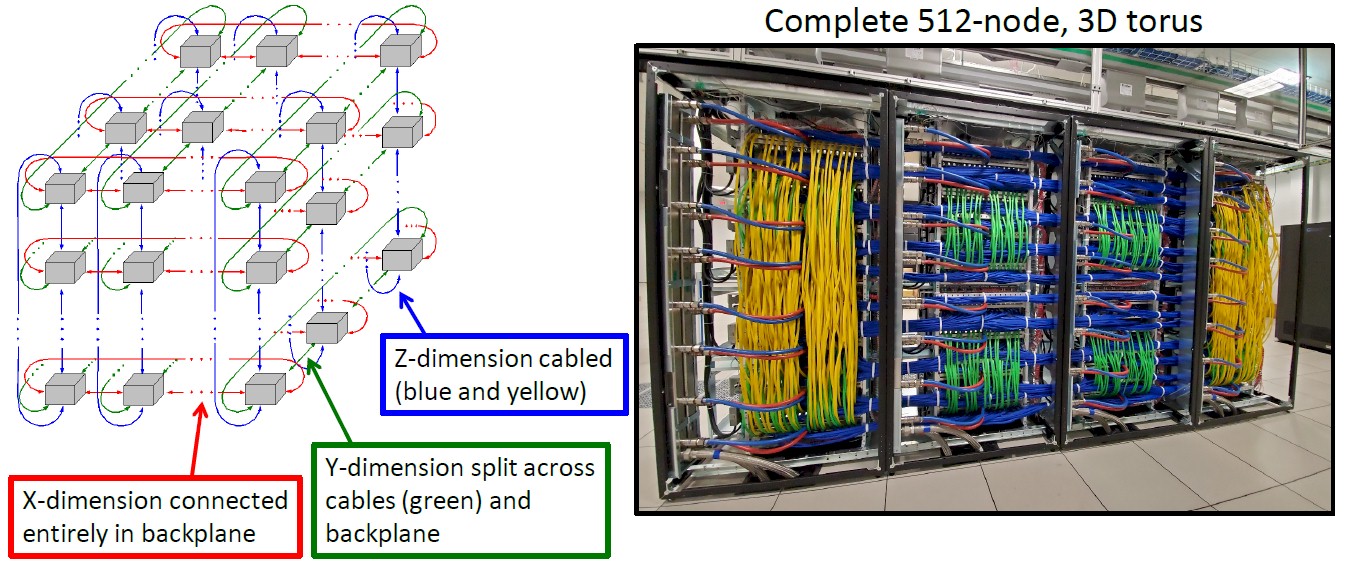
The whole shebang is water cooled and can handle 500 watts of power per node using 65 degree Celsius water, weighing in at 100 kilowatts per rack and 400 kilowatts across the entire system. The Anton systems are not designed to scale beyond 512 nodes — at least not now. But that could change in the future as these other levers — process, packaging, core innovation, and such — start running out of gas.
Add it all up, and Anton is still the molecular dynamics machine to beat. Check this chart out:
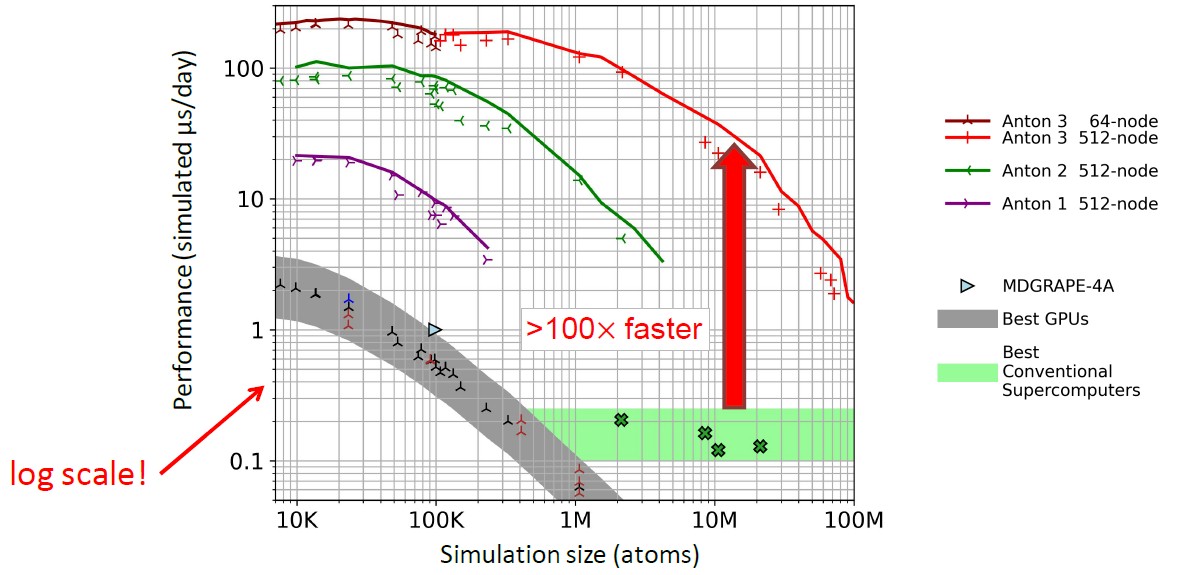
The performance metrics compare Anton machines to x86 servers with Ampere A100 GPU accelerators running the Desmond molecular dynamics application created by DE Shaw Research. Other machines in the chart are running various MD programs and are shown just to illustrate the enormous advantage that the Anton systems have with their very specific hardware and co-designed software and hardware approach.
Performance for MD workloads interplays the number of atoms simulated and the number of microseconds of molecular interactions simulated given a 24-hour day of processing at the wall time for the system under test. If you do more atoms, your simulation elapsed time for the molecular interactions goes down for a set wall time. If you do fewer atoms, you can simulate more time. The chart above shows the interplay of these factors running MD code.
“On a chip-for-chip basis running the Desmond code, the Anton 3 chip is around 20X faster than the Nvidia A100,” explained Butts. “That is not to pick on Nvidia. The A100 is a tremendously capable compute engine. Rather, this illustrates the tremendous benefit we achieve from specialization. As a point of historical interest, a single chip Anton 3 supports almost the same maximum capacity as the Anton 1 supercomputer with 512 nodes. Moreover, it is actually faster over most of that range while consuming just one-fiftieth of the power.”
Butts said that the Anton 3 represents the first time that a single-chip system could be useful in the field for researchers. The molecular simulation that Butts showed of the interaction of molecules with the now-famous spike on the SARS-CoV-2 virus fits on a single Anton 3 node and has an order of magnitude better performance than an A100 GPU running the same code. This Anton 3 machine can simulate milliseconds of time over 100,000 atoms with just 64 nodes over the course of a work week.
Which brings us back to the point we started at: Get this into the hands of more people.


The Bespoke Supercomputing Architecture That Stood the Test of Time
In the history of computing, there has been an endless push and pull between the need for general-purpose versus fine-tuned custom systems and software. While general purpose will, by nature, prevail on leadership-class HPC, the work done in meticulous world of ASIC design, system and software optimization filters into architectural …
The Evolution of NAMD: A Scalability Story from Single-Core to GPU Boosted
On today’s episode of “The Interview” with The Next Platform, we take a look at the evolution of the NAMD molecular dynamics and how the introduction of GPU computing upended performance expectations and set the stage for new metrics now that the Volta GPU architecture will be available on large …
A MapReduce Accelerator to Tackle Molecular Dynamics
Novel architectures are born out of necessity and for some applications, including molecular dynamics, there have been endless attempts to push parallel performance. In this area, there are already numerous approaches to acceleration. At the highest end is the custom ASIC-driven Anton machine from D.E. Shaw, which is the fastest …
Scaling up production to sell single Anton 3 chips in GPU like form factor could revolutionize current research for the many researchers who don’t have Anton 2 grants.