

It is a given that high performance computing systems of any kind are going to need high performance storage to keep them fed. But every workload and every dataset are different, and machine learning workloads and related AI analytics jobs have some special needs that are going to be unfamiliar to many IT organizations that nonetheless have lots of experience with high performance storage of one kind or another.
That is why storage cannot be an afterthought for those designing and acquiring what are very expensive machine learning systems that these days are dominated by GPU accelerators and InfiniBand networking from Nvidia. Without the right storage – and the right approach to integrating it into systems like Nvidia’s DGX-A100 systems and their analogs from OEMs and ODMs – a lot of that investment in compute could end up going up the chimney because the storage can’t keep up.
Nvidia has created reference architectures that include the CPUs, the GPUs, the local storage, and the networking used to hook the CPUs and GPUs in separate enclosures to each other using InfiniBand network interface cards and their Remote Direct Memory Access (RDMA) for both CPUs and GPUs. These reference architectures for its POD and now SuperPOD systems have been the building blocks for its own Saturn-V, DGX SuperPOD, and now Selene hybrid AI/HPC supercomputers – as well as those machines that have been built as clones of them by customers. They go into very fine detail about precisely how the compute elements must be interlinked for machine learning to work well. But there is only a dual-port ConnectX-6 NIC running Ethernet at a top speed of 100 Gb/sec to link the DGX-A100 systems to external storage.
This seems insufficient to VAST Data, particularly given the nature of AI workloads in contrast to HPC workloads. And so VAST Data has been working with Nvidia to do something about it, and that is to interleave its own flash-based Universal Storage arrays into the same high-bandwidth, low latency interconnect – eight ports per server running at 200 Gb/sec HDR InfiniBand speeds for each DGX-A100 node – that is employed to lash the compute resources together.
“We are tackling the issue that many customers are facing,” Daniel Bounds, the new vice president of marketing at VAST Data who joined the company last fall after stints steering servers at Hewlett Packard, Dell, and Cisco Systems in the past two decades, running EMC’s storage sales into service providers, and then moving to AMD head up the marketing for that company’s return to datacenter compute. “We have gotten compute density to a fantastic point with GPUs and FPGAs, and specifically with the DGX-A100 system with GPUs. There are awesome opportunities with computer vision, natural language processing, and volumetric data capture as these datasets grow and grow. But you don’t want to throttle or cripple the underlying storage system.”
Nvidia has not talked much about its storage for the Saturn-V, DGX SuperPOD, or Selene systems, and part of the reason, we think, is that everyone is still trying to figure out the best way to do storage for AI clusters. These systems have had a fair amount of local flash storage on them, which is suitable for some workloads, but which is going to be insufficient for AI training jobs that are going to involve tens to hundreds of petabytes of data – or even more.
To be specific, there are two 1.92 TB NVM-Express M.2 flash sticks for redundant operating system images, and then four 3.84 TB NVM-Express flash drives, for a total of 15 TB of data capacity. Across a network of dozens to hundreds of machines, that’s hundreds of terabytes to maybe a few petabytes of data capacity spread out over the DGX-A100 cluster.
That’s not a lot. And it is really not a lot considering the nature of AI data versus HPC data, which we have discussed before at The Next Platform. HPC clusters take a relatively little bit of data – megabytes to terabytes – and use it as initial conditions in a simulation or model that has a tremendous amount of output – on the order of hundreds of gigabytes to tens of petabytes for big machines these days. AI is the exact opposite in that a tremendous amount of data is run through a self-refining training algorithm, which fine tunes itself with some nips and tucks here and there, to create an inference model that is essentially a summary algorithm that new data is poured through. In this sense, it boils all of the data off, just leaving a kind of structure for new data to pass through to be identified in some fashion.
The thing is, there are ensembles of AI training that are averaged together to come up with better inference models, and there are new frameworks and algorithms that are also being used to refine the models. And of course, there are new types of data as well as new data that is added to the training regimen, all to make the model ever-increasingly better. Training is never done, all data is always needed and is always growing, and so the storage can be stressed like crazy in an AI cluster – and it only keeps getting worse if the pipes to storage are not wide enough or fast enough.
In an HPC system, by stark contrast, periodic checkpointing of the state of the simulation needs to be done and the final simulation and its visualization needs to be dumped, en masse, to storage. Hence the need for a parallel file system as well as massive data storage capacity.
While it is possible to graft a parallel file system onto an AI system to get capacity and bandwidth and sort of run an HPC system in reverse, trying to pump all of this data into the server nodes and their respective individual GPU memories so they can chew on it to do machine learning training, VAST Data wants to do something better. And better than just grabbing a modestly sized flash array and sticking one on each of the two 100 Gb/sec Ethernet ports on each DGX-A100 server node. VAST Data wants to embed its Universal Storage inside of the compute network so all of the data can be shared by all of the GPUs at the same time with multipathed, RDMA access using a plain vanilla NFS protocol that makes it all look like local storage to the DGX-A100 nodes.
VAST Data and others have tried supporting AI workloads on those storage ports, and Jeff Denworth, vice president of products at the company, says that by switching to the compute network, VAST Data can deliver about 35 GB/sec of storage bandwidth using Nvidia’s reference architecture benchmark test suite into a single DGX-A100 node and still leave room for the compute network to do its thing connecting DGX-A100 nodes together so the GPUs across nodes can share data as they chew on it. And when support for GPUDirect Storage is layered on top at some point in the near future, Denworth says VAST Data should be able to drive this number even higher. VAST Data did not test how this Nvidia reference architecture would do on just the two 100 Gb/sec storage ports on the DGX-A100 system, but given the relative bandwidths and the support for RDMA on both sets of NICs, it is reasonable to think it might be on the order of 4 GB/sec to 5 GB/sec.
The bandwidth increases for storage running on the compute network are, according to initial tests done by VAST Data and Nvidia, linearly scalable, meaning that as DGX-A100 nodes are added to a cluster, the bandwidth rises directly with the node count. Like this:
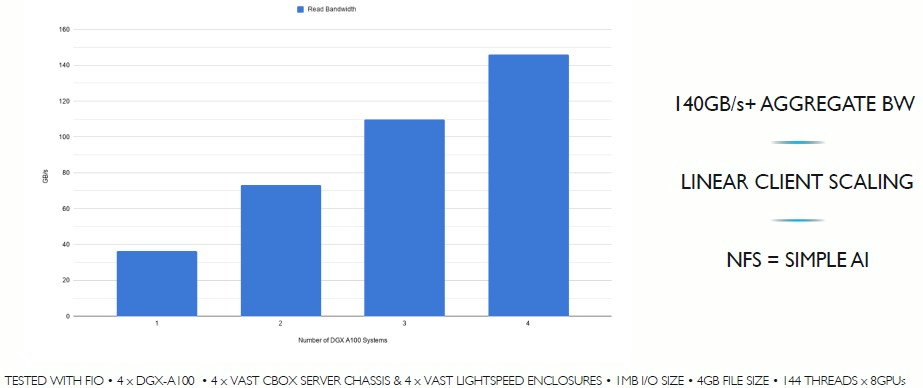
It is hard to read the numbers and words on this chart, so that is GB/sec of read bandwidth on the Y axis and number of DGX-A100 systems scaling from one to four on the X axis.
Not having the compute and storage traffic bump heads on that eight-wide InfiniBand NIC pipe coming out of the backend of the DGX-A100 systems is important. There is an aggregate of 200 GB/sec of peak theoretical bandwidth on that network. There’s plenty of room for compute, and thanks in large part to something fortunate about clustered AI machine learning training frameworks and perhaps for HPC workloads, too.
“If you think about parallel distributed computing, very rarely are you doing storage I/O and MPI interchange at exactly the same time,” explains Denworth. “This makes it possible to have both processes co-exist on the same fabric without it being a nailbiter.”
VAST Data and Nvidia have been working on using the compute interconnect for storage for the past six months or so. Others will no doubt try to follow suit, and it will be interesting to see how successful they are in this approach. We think this is the way all AI and HPC systems will do big storage. We will note that when Cray created its “Slingshot” Ethernet switch ASIC, which has dynamic routing and congestion control built into the “Rosetta” ASIC itself, one of the things that Cray was trying to do was put the storage directly on the same network as the compute, which eliminated a whole network layer and its cost and complexity as well as boosting the performance of the storage and increasing its integration with the compute engines in its Shasta systems. Hewlett Packard Enterprise, we expect, will soon be emphasizing this combined storage-compute network, particularly if VAST Data and Nvidia get traction with the idea.


The Great Danes Get A Supercomputer For AI And Maybe HPC
To AI or to not AI, that is not even a question in 2024. And to need sovereign AI is also not a question. Which is the main reason that we see country after country, and large multinational companies, investing in AI infrastructure in a way that we never did …

Mainstreaming Fast Flash Clusters For Fun And Profit
One of the common themes – and one could say even the main theme – of The Next Platform is that some of technologies developed by the high performance supercomputing centers (usually in conjunction with governments and academia), the hyperscalers, the big cloud builders, and a handful of big and …

Nvidia Will Be The Next IT Giant To Break $100 Billion In Sales
Here is a history question for you: How many IT suppliers who do a reasonable portion of their business in the commercial IT sector – and a lot of that in the datacenter – have ever broken through the $100 billion barrier? Three. To be precise: IBM broke $100 billion …
Be the first to comment