

Things get a little wonky at exascale and hyperscale. Things that don’t matter quite as much at enterprise scale, such as the cost or the performance per watt or the performance per dollar per watt for a system or a cluster, end up dominating the buying decisions.
The main reason is that powering and cooling large aggregations of machines soon costs a lot more than acquiring the iron, and this makes some machines themselves untenable financially and physically. For the HPC centers of the world, the lack of energy efficiency means not having enough budget to cover the costs of the system, and for the hyperscalers and public cloud builders, it means not being able to compete aggressively with on-premises equipment sold to the masses and not being able to garner the high operating profits that the shareholders in the public clouds and hyperscalers expect.
It all comes to the same. To get a handle on how the energy efficiency in the HPC sector has changed over time and how future exascale-class systems are expected to improve upon this curve, AMD commissioned Jonathan Koomey, formerly a research associate at Lawrence Berkeley National Laboratories (a job he had for nearly three decades), a visiting professor at Stanford University, Yale University, and the University of California at Berkeley, and an advisor to the Rocky Mountain Institute for nearly two decades, to do some analysis along with Sam Naffziger, a Fellow at Hewlett Packard, Intel, and now AMD for many cumulative decades who worked on processor designs and power optimization, to crunch the numbers on HPC systems in the twice-yearly Top 500 supercomputer rankings.
The resulting paper, which was just published and which you can read here, ultimately focused on the performance and energy consumption of the top system. If you extract that data out, you find that there are really two performance curves in the past two decades – one where the performance doubled every 0.97 years on average between 2002 and 2009 and another where the performance doubled every 2.34 years – not the average of 1.35 years if you just slapped a line down on the whole dataset from 2002 through 2022, where the expected 1.5 exaflops “Frontier” system being built by Cray and AMD for Oak Ridge National Laboratory will fit on the performance line. Here is what the data looks like:
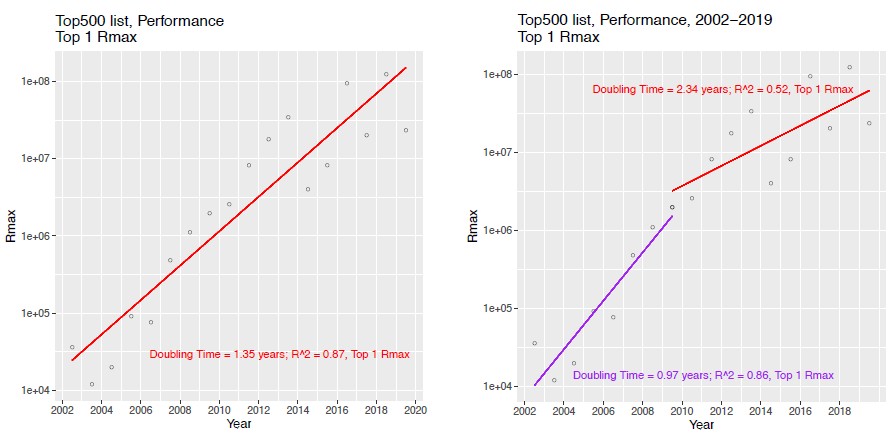
Now, here is what the performance and efficiency curves look like just for the machines installed from 2009 through 2022, including the estimate for Frontier, which is expected to be the highest performing supercomputer in the world at the tail end of that dataset. Take a look:
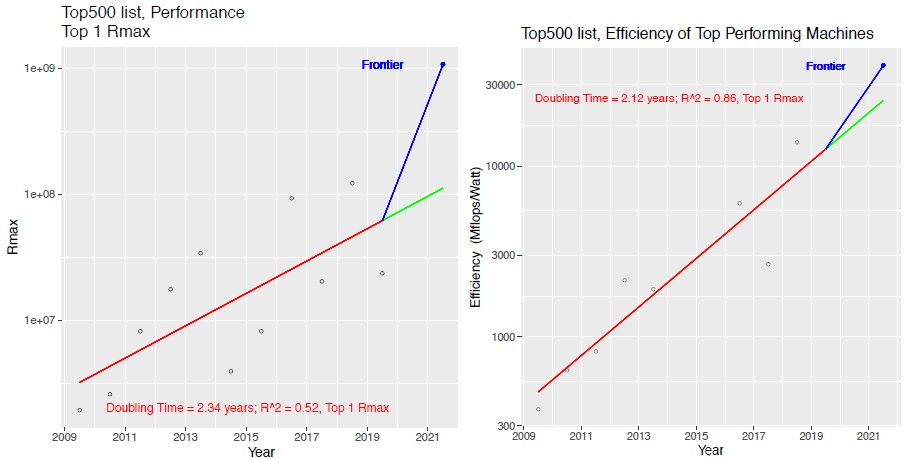
The performance of the Frontier system at double precision floating point is known at 1.5 exaflops, but the energy consumption of the system and therefore the performance per watt has some pretty big error bars on it right now because these have not been divulged. All that Cray has said is that the machine would have in excess of 100 cabinets. Cray has said that the “Shasta” cabinets on which Frontier will be based have 64 blades per cabinet.
We think that Cray will be able to get two or four compute complexes, each with one single custom “Genoa” Epyc 7004 processor and four custom Radeon Instinct GPU accelerators, onto a single blade. As we showed with some very rough, back of the drink’s napkin math when talking about the “Aurora” A21 machine being built by Intel and Cray for Argonne National Laboratory and the future Frontier machine, our best guess is that the Frontier machine will have 25,600 nodes in total, with the CPU having 3.5 teraflops of its own FP64 oomph and the Radeon Instincts having 13.8 teraflops of FP64 performance each, and if you do the math, that works out to 1.5 exaflops. Depending on how densely Cray can pack this, it could be 200 racks at 150 kilowatts or 100 racks at 300 kilowatts. Cray has only said it is more than 100 cabinets, but our point, the cabinet density is not going to change the number of nodes or the performance or the performance per watt. At four nodes per blade and a low 150 watts for the CPU and maybe 200 watts to 280 watts for the GPU, you can play around and get below that 300 kilowatt threshold per rack for the raw compute with some room for memory, flash, and “Slingshot” interconnect. You could go half as dense with 200 racks and free up some space and just try to cram maybe 150 kilowatts to 180 kilowatts per rack, with more headroom for storage and networking, and still ne in the range of 30 megawatts to 36 megawatts for the whole machine.
These are all conjecture, of course. So take it in that spirit.
What is interesting to ponder is how the performance curve is bending way up on the top supercomputer thanks to Frontier, but look at how hard it is to bend that performance/watt curve up. Perhaps Cray and AMD will do better than we all expect for Oak Ridge when it comes to energy efficiency.
After reading this paper, we had a little chat with Koomey and Naffziger.
Timothy Prickett Morgan: I think the trend lines for the Top 100 machines are reasonable and the top machine is definitely representative. I get the idea that you’re putting a data point in the ground for Frontier and it is definitely starting to bend the curve back up the way we’d like to see it. An all CPU machine, if someone built an exascale one, would probably be on the order of 80 megawatts.
Sam Naffziger: AMD takes the energy efficiency of all our compute solutions seriously and one of our goals is to deliver significant – and leadership – generational efficiency gains, measured as joules per computation or performance per watt, whatever your metric watt. That’s why we partnered with Jon Koomey, to extract on the supercomputing front the efficiency trends have been going on, and we found that there really was very little work done on this. The first thing to understand was what are the trends? And then that sets a baseline for what we want to achieve going forward. We want to do at least as well in efficiency gains despite the headwinds of Moore’s Law challenges and other impediments.
Jonathan Koomey: So there there’s a couple of key points on the efficiency side. First, we are using Linpack, which we all know is ancient and not terribly representative of actual workloads. But still, one of the techniques for getting faster processing is to do special purpose computing. For a specific workload, you design a computer – or a set of systems – to focus on just that workload. That’s one way you can break out of the constraints that we have faced over the last 15 or 20 years. As long as that workload is sufficiently large and sufficiently homogeneous, you can design a device that will do much, much better than a general purpose computing device for that specific task, and we can still do this.
Now, the other way to attack the problem is through co-design — and we talk about that in the paper as well. There’s a reference in our paper to Rethinking Hardware-Software Codesign that controlled for a silicon process dies and as part of that analysis, the researchers found by applying this co-design process – integrated analysis and optimization of software and hardware together – that they were able to get a factor of 5X to 7.6X improvement in efficiency beyond what a conventional design approach would lead to. So if you optimize the system, you could do much, much better than a simple compilation of existing processors using standard interconnects and other things. But again, it requires some knowledge of workloads. It requires a systematic process of optimization.
TPM: One thing that I found interesting – and IBM has been banging this drum with its Bayesian optimization and cognitive computing efforts – is that the best kind of computing to do only that which you really need. Figuring out what part of the data to choose or what kind of ensembles to do is the hard bit. And if you do that, then you might not need an exascale class computer to get the same answer you would have otherwise. I think we need to get the right answer per watt, and this is how we ought to be thinking about it. It is not just about exaflops. Answer per watt and time to answer are just as important.
Sam Naffziger: This goes back to Lisa Su’s talk at Hot Chips last year. There are a number of those system level dimensions which accelerate time to answer around the cache hierarchy, the balancing of memory bandwidth, the node and internode connectivity, the CPU and GPU coherency – all of which are part of the Frontier design. And it’s the combination of all those that accelerate the algorithms. What you are talking about with IBM should be the next step.
TPM: The beautiful thing about IBM’s approaches is that they work on Frontier or any other system. It has nothing to do with the architecture. I happen to believe we are going to have to do all of these things. My concern in the past couple of months is if we keep doing what we are doing, it is going to take 100 megawatts to 120 megawatts and $1.8 billion dollars to create a 10 exaflops supercomputer. We can argue whether or not we should even worry about that number. But that’s the curve we’ve been plotting, and there’s no way any government agency is going to come up with that kind of money. So kudos to AMD and Cray and Oak Ridge for bending that curve down the other direction, and for everyone else who will do innovation on this front.
Jonathan Koomey: What you’re pointing to is that the focus on brute force is leading to diminishing returns and that we have to get a whole lot more clever in how we accomplish the tasks that we want to accomplish. And that means focus on workloads and understanding exactly how to do them in the most efficient way. But it’s I think this is it’s kind of pulling us back from a very simple view of performance in computing and making people – it’s forcing people to understand that there’s there is a real difference. We shouldn’t be talking solely about this kind of brute force, general purpose compute capacity – it’s a much more complicated question than what people have assumed thus far.
TPM: Unfortunately, though, some HPC centers have to build machines that can do many things because they are so expensive that can’t be one workload workhorses. It’s great that a machine that can do modern HPC can also do AI, and it’s great that you might be able to mix them together. But had it not been for that happy coincidence of AI needing GPU acceleration to do training and possibly inference now too, some of these big HPC machines might not have gotten built.
Jonathan Koomey: I think that we’re going to see a lot more innovation on the software side. The folks at the University of Washington are working on approximate computing for certain kinds of problems, like face recognition and other applications where you don’t need to solve every single bit of a problem with every bit of data. You can do things that are approximate and that get you use to get you to your end point with much less compute and with approximately the same fidelity. Tt’s that kind of change on the software side that I think is going to yield some big benefit.
Sam Naffziger: That’s what we’re seeing in the machine learning training space as we’ve moved from 32 bits down to 16 bits and now to be down to bfloat16. We are trading the dynamic range versus precision to get good enough answers significantly more cheaply. There’s a lot of interest in the HPC community around exploiting that bfloat16 format for actual high performance computing workloads and getting good enough precision relative to FP64, but getting an answer much more cheaply.

The Once And Future FPGA Maker Altera
Back in 2015, when we were launching The Next Platform, a lot of stuff was going on all at the same time, which is part of the zeitgeist that we were tapping into and that we wanted to chronical upon and participate within. And Intel was front and center of …

AMD on Why Chiplets—And Why Now
Moore’s Law is not just a simple rule of thumb about transistor counts, it’s an economic, technical, and developmental force—and one strong enough to push some of the largest chipmakers to future-proof architectural approaches. That force pushed some of AMD’s lead architects to reroute around the once-expected cadence of new …
AMD Flexing Spartan FPGA Muscles In Clouds And At Edges
The edge is continuing to become a place where IT infrastructure vendors need to be, and that includes chip makers, all of whom have strategies to push their silicon to where the data is increasingly being generated and needs to be stored, processed, and analyzed. AMD, armed with the technology …
If you exclude the outliers mid 2012 and mid 2017 there is actually no bending of the curve towards Frontier but it would be pretty straight up from the others.
On the napkin calculation: 280W for ~14TF would not be especially attractive given that two years ago with V100 you had 250W for ~7TF on TSCM 12nm already. From 2017 to 2022 only a doubling in energy efficiency from acceleration would really not be the right direction.
As you discussed in the interview, silicon will only get us that far, I don’t expect significant curve changes from it (unless you include bad outliers to pull the baseline down). It’s software – what is processed when, but also where and how that will determine the energy efficiency. I expect many machines larger than their power limit when considering Linpack (showing up below their HPL capability on Top500) but still maximizing actual application throughput through energy aware software.
I’d really like to see AMD’s/Cray’s Epyc CPU/processor direct to GPU(Instinct) xGMI/Infinity Fabric interfacing topology compared/contrasted directly with IBM’s/OpenPower’s/Nvidia’s Power9/10 direct to Nvidia’s Tesla GPU accelerator interfacing via the NVLink topology. And that’s AMD’s main competition for Direct Attached CPU to GPU/Accelerator interfacing via proprietary interfacing IP(Infinity Fabric versus NVLink). AMD is currently behind IBM/Nvidia in offering that sort of direct attached CPU to GPU/Accelerator interfacing to the general server market.
Currently AMD is mostly offering PCIe interfacing for CPU to GPU interfacing and PCIe is not as integrated into the fabric of AMD’s products to the degree that the Infinity Fabric is. Both AMD’s Infinity Fabric and Nvidia’s NVLink IP are more deeply integrated for features like cache coherency between processors as PCIe signalling is mostly external to any processor’s core functionality.