

If hyperscalers, cloud builders, HPC centers, enterprises, and both OEMs and ODMs like one thing, it is a steady drumbeat of technology enhancements to drive their datacenters forward. It is hard to reckon what is more important: the technology or the drumbeat, but it is painfully obvious when both fail and it is a thing of beauty to watch when both are humming along together.
Broadcom, a company that was founded in the early 1990s as a supplier of chips for cable modems and set-top boxes, started down the road to datacenter switching and routing in January 1999 with its $104 million acquisition of Maverick Networks, and followed that up in September 2002 with a $533 million acquisition of Altima Communications. Broadcom was already designing its own ASICs for datacenter networking gear, but these were for fairly simple Layer 2 Ethernet switches, and Maverick was working on higher-end, beefier ASICs that combined Layer 2 switching and Layer 3 routing functions on the same device. Altima made networking chips that ended up in networking devices sold mostly to SMBs, but gave Broadcom more networking customers and a broader engineering and patent portfolio to pull from.
Broadcom got serious about switching when blade servers took off in the datacenter in the early 2000s, when the hyperscalers were not even really megascale yet and when the public cloud was still just a bunch of talk about utility computing and grid computing. It unveiled its first mass produced collection of chips for building 10 Gb/sec Ethernet switches – which did not even have codenames, apparently – out of nine chips. In 2007, the “Scorpion” chip provided 24 ports running at 10 Gb/sec or 40 Gb/sec and 1 Tb/sec of aggregate bandwidth, and the merchant silicon business was off to the races as the hyperscalers were exploding and Amazon had just launched its public cloud a year earlier. The $178 million deal in December 2009 to take control of Dune Networks, which still carries on as the “Jericho” StrataDNX line of deep buffer switches, was pivotal for the company’s merchant silicon aspirations and coincides with the rise of the hyperscalers and cloud builders and their particular needs on their network backbones.
The “Trident” family, which really ramped up merchant capabilities compared to the captive chips made by the networking incumbents such as Cisco Systems, Juniper Networks, Hewlett Packard (3Com), and Dell (Force10 Networks), came out in 2010, aimed mostly at enterprises that needed more features and bandwidth than the Jericho line could provide but that did not need the deep buffers. The “Tomahawk” line debuted in 2014, which stripped out features that hyperscalers and cloud builders did not need (such as protocols they had no intention of using) but which included more routing functions and larger tables, and lower power consumption made possible by 25 GHz lane speeds that Google and Microsoft drove the IEEE to accept when it really wasn’t in the mood to do that initially.
Broadcom has been advancing all three families of silicon with a pretty steady cadence. The Jericho 2 chip, rated at 9.6 Tb/sec of aggregate bandwidth and driving 24 ports at 400 Gb/sec with deep buffers based on HBM stacked memory, was announced in in March 2018 and started shipping in production in February of this year. With the Trident 4 ASIC unveiled in June of this year, Broadcom supported up to 12.8 Tb/sec of aggregate bandwidth and using PAM-4 encoding to drive 25 GHz lanes on the SERDES to an effective speed of 50 Gb/sec per lane and able to drive 128 ports at 100 Gb/sec or 32 ports at 400 Gb/sec. The Trident 4 chip weighed in at 21 billion transistors and is a monolithic device etched in 7 nanometer processes from fab partner Taiwan Semiconductor Manufacturing Corp.

Believe it or not, the Trident 4, which was the fattest chip in terms of transistor count we had ever heard of when it was unveiled this year, was not up against the reticle limit of chip making gear. But we suspect that the Tomahawk 4 announced this week is pushing up against the reticle limits, with over 31 billion transistors etched using the same 7 nanometer processes. The Trident 4 and Tomahawk 3 chip from January 2018 were pin compatible, but they had an equal number of SERDES. With the doubling up of SERDES with the Tomahawk 4, there was no way to keep Tomahawk 4 pin compatible with these two prior chips. But, there is hope for Trident 5. . . .
The Tomahawk line has come a long way in its five years, as you can see:

The original Tomahawk 1 chip from 2014 was etched using 28 nanometer processes from TSMC and had a mere 7 billion transistors supporting its 128 “Long Reach” SERDES running at 25 GHz using non-return on zero (NRZ) encoding, which has two levels of encoding to encode a bit per signal. The Tomahawk 1 delivered 3.2 Tb/sec of aggregate bandwidth, which was top of the line five years ago. With the PAM-4 encoding added with recent switch ASICs, you can have four signals per lane and encode two bits of data, driving up the effective bandwidth without increasing the clock speed above 25 GHz. This is how the Tomahawk 3, Trident 4, and Tomahawk 4 have been growing their bandwidth. The SERDES count on the die has also been going up as processes have shrunk, with the Tomahawk 4 doubling up to 512 of the “Blackhawk” SERDES, of which the Tomahawk 3 had 256 implemented in 16 nanometers, thus delivering a doubling of aggregate bandwidth across the Tomahawk 4 ASIC to 25.6 Tb/sec.
The Tomahawk 4 is a monolithic chip, like prior generations of Broadcom StrataXGS and StrataDNX, chips, and Broadcom seems intent in staying monolithic as long as it can without resorting to the complexity of chiplets. Even if smaller chips tend to increase yields, adding two, four, or eight chiplets to a package creates assembly and yield issues of their own. Some CPU suppliers (like AMD and IBM) have gone with chiplets, but others are staying monolithic (Intel, Ampere, Marvell, HiSilicon, Fujitsu, and IBM with some Power9 chips), and there are reasons for both.
When it comes to networking, Peter Del Vecchio, who is the product line manager for the Tomahawk and Trident lines at Broadcom, monolithic is the way to go.
“We have seen some of our competition move to multi-die implementations just to get to 12.8 Tb/sec,” Del Vecchio tells The Next Platform, and the obvious one there is the “Tofino2” chip from Intel (formerly Barefoot Networks). “Just for the benefits of power and performance, if you can keep all of the traces on a single piece of silicon, that definitely provides benefits. And that is why we wanted to stay with a monolithic design for this device.”
Having a fatter device means eliminating hops on the network, too, and also eliminating the cost of those chips and the networking gear that has to wrap around them. If you wanted to build a switch with 25.6 Tb/sec of aggregate networking bandwidth using the prior generation of Tomahawk 3 ASICs, you would need six such devices, as shown below:
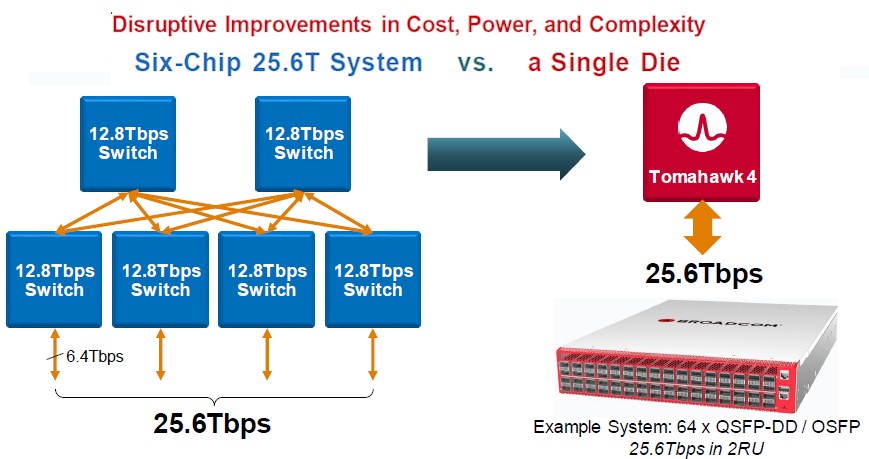
It takes six devices to connect 256 ports using the current Tomahawk 3 chip, assuming that half the bandwidth (6.4 Tb/sec) of the bandwidth on each ASIC is used for server downlinks running at 100 Gb/sec (64 ports) and half the bandwidth is aggregated and used as uplinks to the next level up in the modular switch (we presume it would be 16 ports running at 400 Gb/sec). It takes four of those first-level Tomahawk 3 ASICs to create 256 100 Gb/sec downlinks plus two more to cross connect the four chips together in a non-blocking fashion with two paths across the pair of additional Tomahawk 3 ASICs. This architecture adds two more hops to three-quarters of the port hops (some of them stay within a single switch ASIC), so the latency is not always higher than with a single chip, but the odds favor it. If you cut down on the number of second level ASICs, then you might get congestion, which would increase latency.
Now, shift to a single Tomahawk 4 ASIC, and you can have 256 100 Gb/sec ports all hanging off the same device, which in the case of the prototype platform built by Broadcom will be a 2U form factor switch with 64 ports running at 400 Gb/sec and four-way cable splitters breaking each port down into 100 Gb/sec ports. Every port is a single hop away when any other port across those 256 ports, and according to Del Vecchio, the cost will go down by 75 percent at the switch level and the power consumption will also go down by a factor of 75 percent.
Broadcom is not providing specific pricing for its chips, and it is an incorrect assumption that Broadcom will charge the same price for the Tomahawk 4 as it did for the Tomahawk 3. On the contrary, with these improvements, we expect that Broadcom will be able to charge more for the ASIC (but far less than 2X of course) – probably on the order of 25 percent to 30 percent more for that 2X increase in throughput and reduction in latency.
Speaking of latency, here is another chart that Del Vecchio shared that put some numbers on the latency decrease using servers chatting with an external NVM-Express flash cluster:
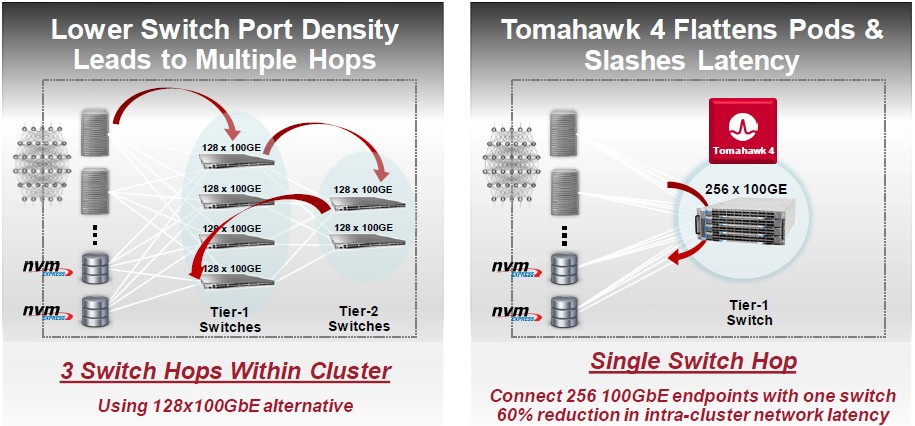
In this case, the flash cluster gets twice as many endpoints running at 100 Gb/sec and the latency between the servers and the disaggregated NVM-Express flash servers drops by 60 percent. (Exact latency numbers were not given by Broadcom, and neither is price or watts per port on any of its ASICs or die size or watts for any of the ASICs.)
Let’s think about this for a second. The CPU business has been lucky to double the number of cores every two to three years, and in many cases has not really done this. (Intel’s “Cascade Lake-AP” doubled up processors sort of count, but not really given the wattages.) So that means you can get a little less than 2X the performance in the same two-socket machine every two to three years. There will be exceptions, when a lot of vendors can double up within one year, but this will not hold for the long term.
What Broadcom is doing here is cutting the number of chips it needs to provide a port at a given speed by a factor of 6X every two years. Not 2X every two to three years, but 6X every two years like clockwork. Even if every successive chip gives you 30 percent more money, you need to sell 4.X more chips to get the same revenue stream, which means that your customer base has to be more than doubling their port counts at a given speed, or doubling up their port speed, or a mix of both, every year for the money to work out for the chip maker like Broadcom. This is a much rougher business in this regard than the CPU business for servers. But clearly, the demand for bandwidth is not abating, and despite intense competition, Broadcom still has dominant share of the bandwidth sold into datacenter networks, as it has had for the better part of a decade.
Carving It Up
That 25.6 Tb/sec of aggregate bandwidth on the Tomahawk 4 chip can be card up in a number of ways, including 64 ports at 400 Gb/sec, 128 ports at 200 Gb/sec, and 256 ports at 100 Gb/sec. It takes cable splitters to chop it down by a factor of two or four, and you might be thinking: Why stop there? Why not 512 ports running at 50 Gb/sec or even 1,024 ports running at 25 Gb/sec and really push the radix to the limits and also create a massive muscle of network cables coming off each port? The answer is you can’t because to keep the chip size manageable, Broadcom had to limit the queues and other features to a maximum of 256 ports. The cutting down of physical ports with splitters is not free. So, for instance, supporting 100 Gb/sec ports requires more queues and buffering. Which is why you don’t see ports split all the way down to 10 Gb/sec natively on the chip, although you can get a 100 Gb/sec port to negotiate down to 40 Gb/sec or 10 Gb/sec and throw the extra bandwidth out the window.
In a certain sense, a modern CPU, whether it is monolithic or comprised of chiplets, is really a baby NUMA server crammed down into a socket and it takes fewer and fewer servers in a distributing computing cluster to reach a certain number of cores, the unit of compute performance more or less. Similarly, with every new generation of switch ASICs, vendors like Broadcom are able to eliminate layers of the network by constantly doubling up the number of SERDES on the device, and thus allowing for whole layers of the network to be eliminated – assuming of course you want a non-blocking network as hyperscalers and cloud builders do. And as we have shown above, the increasing bandwidth and radix of each generation of device allows for each “network cluster” – for that is what a modular switch and a full-blown Clos network spanning a hyperscale datacenter is, after all – to have fewer and fewer nodes for a given port count.
The architecture of the Tomahawk 4 chip is very similar to that of the Tomahawk 3, and while you might not be aware of it, there were 1 GHz Arm processor cores on both switch ASICs to run some firmware and do telemetry processing, plus some other Arm cores on the SERDES to run their own firmware. (A switch chip is a hybrid computing device these days, too, just like an FPGA or DSP generally is.) The Trident 4 and Tomahawk 4 ASICs have four of the Arm cores for running the telemetry and instrumentation, twice that of their respective predecessors.
The buffer size on the Tomahawk 3 was 64 MB, and we presume that it is at least double this on the Tomahawk 4, but Broadcom is not saying.
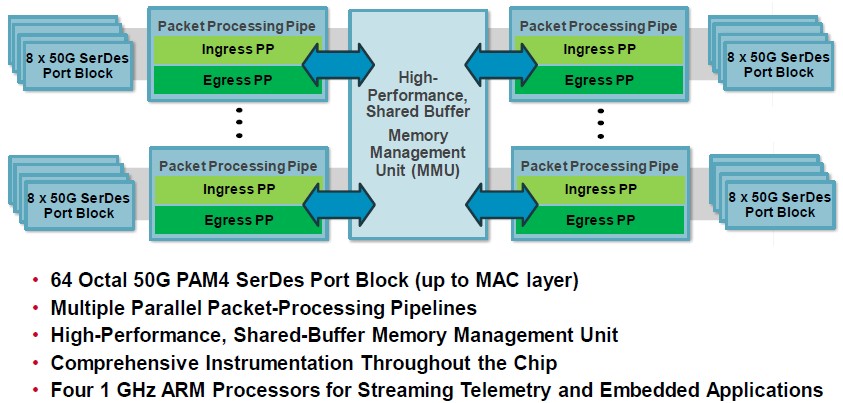
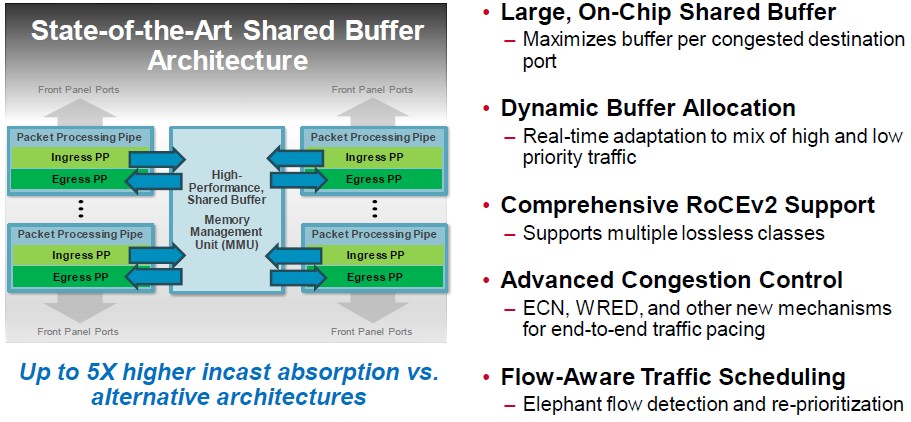
The thing to remember about the hyperscalers is that their packet processing pipelines are not that complicated, but their need to have a lot of telemetry and instrumentation from their networks is vital because with 100,000 devices on a datacenter-scale network, understanding and then shaping traffic is the key to consistent performance.
So the Broadcom networking software stack includes in-band telemetry, real-time SERDES link quality meters, a way to see into all packet drops, flow and queue tracking, and detection of microbursts and elephant flows.
Perhaps equally importantly for hyperscaler and cloud builder customers, Broadcom is documenting and opening up each and every API used with the Tomahawk, Trident, and Jericho families of chips. Among other things, this will help these companies, which by and large create their own network operating systems, better support them, but it will also allow for open NOS initiatives (such as ArcOS from Arrcus) to more easily port their code and support it on Broadcom chips. The OpenNSA API documentation is a superset of the OpenNSL API library that maps to the Broadcom SDK, which was previously available. It is the whole shebang, as they say.
The Tomahawk 4 chip is sampling now and production will be ramping fast, with Del Vecchio expecting as fast of a ramp or faster than was done with the Tomahawk 3 or the Trident 4. So expect Tomahawk 4 devices next summer.




Be the first to comment