

Supercomputer-maker Cray has launched the ClusterStor E1000, a storage offering designed to serve the entire triumvirate of HPC workloads: simulations, artificial intelligence, and analytics. Although, the E1000 is derived from its ClusterStor antecedents, its enhanced design reflects Cray’s doctrine that its supercomputers, and even those of its competitors, will increasingly be running a mix of workloads, only one of which will be traditional simulations.
In fact, Uli Plechschmidt, Cray’s director of storage product marketing, recast the entire exascale era as a period characterized by the convergence of these high performance workloads, rather than one delineated by supercomputing at the level of exaflops or exabytes. Of course, in this revision, the “exa” prefix loses all its meaning. But let’s face it, that definition started to wobble a bit even last year after researchers began using Summit as an “exascale” supercomputer for deep learning codes.
Exascale computing, Plechschmidt explains, is “defined by not just classic modeling and simulations running on the supercomputer or HPC cluster, but also by methods of artificial intelligence, like machine learning, or big data analytics, all running business-critical workloads on one machine. Going forward, we are going to focus on artificial intelligence joining modeling and simulation because it’s the most disruptive workload from an I/O pattern perspective.”
The conviction that AI will be broadly adopted by the HPC customers likely led the Cray engineers to make solid state drives first-class citizens in the new ClusterStor offering. In a nutshell, the E1000 brings SSD storage, with its emphasis on random I/O, read dominance, and mixed file sizes, to HDD storage, and its strength in sequential I/O, write-intensity, and large file sizes, under unified control. While the previous-generation ClusterStor L300 had its L300N and L300F variants that provided a flash storage pool for IOPS acceleration, the E1000 offers a fully integrated design that manages hard disk and flash storage under the same namespace, along with a scheduler to promote and demote data across the two pools.

Cray is claiming that the E1000 offers the fastest storage in the industry – for both its HDD and SSD components. An all-flash E1000 rack, which uses NVM-Express drives, provides up to 1 TB/sec of throughput and 4.5 PB of usable capacity, with the expansion rack delivering 2 TB/sec and 4.6 PB. A disk-based rack offers up to 90 GB/sec of throughput and 7.5 TB of usable capacity, with the expansion counterpart delivering 120 GB/sec and 10 PB, respectively. You don’t need to buy an entire rack, however. An entry-level system starts at less than 60 terabytes delivering 30 GB/sec. Cray provides all the particulars below:
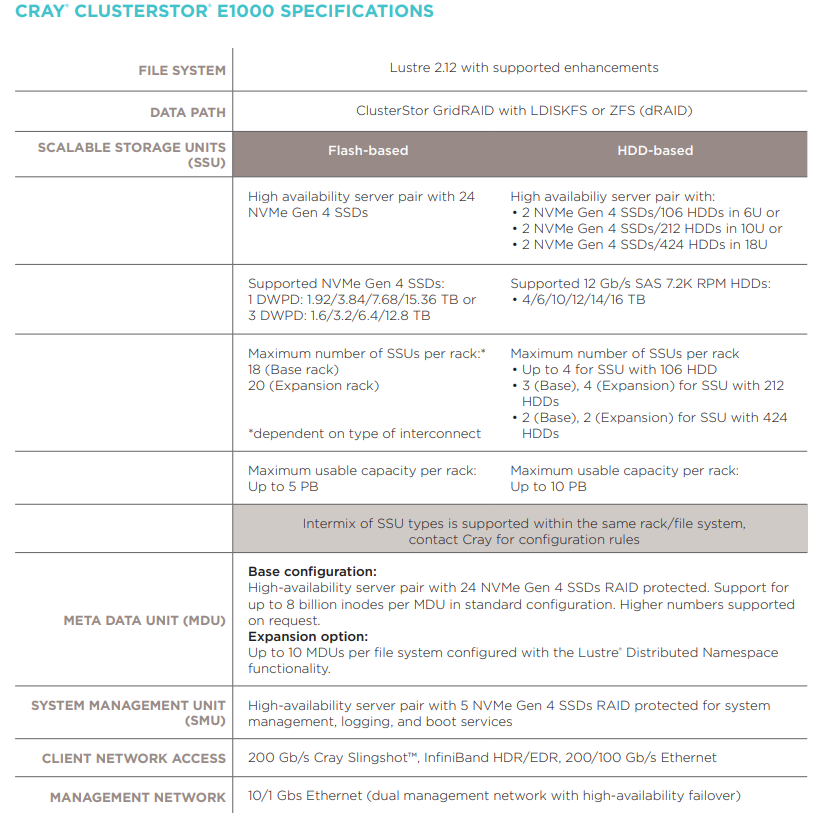
Cray is confident enough with the superiority of those numbers to make some explicit comparison’s with storage systems from rivals. In particular, the company says DataDirect Network’s EXAScaler all-flash ES400NV provides 77 percent less random read throughput and 140 percent less random write throughput that the E1000, while the DDN ES18K or ES7990 delivers 50 percent less read/write throughput. Likewise, IBM’s Elastic Storage Server provides 320 percent less throughput on its flash models, and 70 percent less on its disk models. Cray also claims Lenovo’s Distributed Storage Solution for GPFS provides 300 percent less throughput for its flash models and 230 percent less for its disk models. And none of those systems comes with automated services for data promotion and demotion across tiers.
This data promotion/demotion scheduling is performed through a new piece of software called ClusterStor Data Services, which provides three different methods: scripted tiering, scheduled tiering and transparent tiers. Only the scripted tiering will be supported at launch, with the schedule tiering added in the middle of 2020 and transparent tiering included in the first half of 2021. The scripted method gives the user direct control of data movement between the flash and hard disk tiers, while scheduled tiering adds automation to process by promoting data from disk to flash (and vice-versa) based on workload manager and user directives in the job script. Transparent tiering is completely automated, with all data staging controlled by software working behind the scenes.
Four high-profile E1000 deployments are already in the pipeline, associated with future “Shasta” supercomputer installations. The first one will be a 30 PB all-flash storage system for the “Perlmutter” NERSC-9 system, which is scheduled to be installed in 2020. The remaining three E1000s will be deployed in conjunction with the first three US exascale supercomputers purchased by the Department of Energy: the “Aurora” machine at Argonne National Laboratory in 2020, the Frontier machine at Oak Ridge National Laboratory in 2021, and the “El Capitan” machine at Lawrence Livermore National Laboratory in 2022.

Together they amount to well over an exabyte of capacity. But Cray is hoping that customers of more modest means will purchase the new ClusterStor as well. After all, there are probably only going to be a few hundred exaflop-capable machines installed over the 5 to 10 years, and even though these would likely be paired with super-sized storage systems, Cray is aiming for a broader base of customers.
As Plechschmidt outlined, even smaller HPC clusters at a university or at a commercial business running these heterogenous workloads would qualify as an exascale systems and would be well-served by the E1000. And these machines need not even be Cray systems. In addition to supporting Shasta’s native Slingshot network, the new ClusterStor is capable of talking over InfiniBand and Ethernet. And as we mentioned before, the E1000 can be purchased in sub-rack increments.
Whether the E1000 can draw in such customers remains to be seen. But with Cray now under the HPE umbrella, it seems more likely now that these systems will have a clearer path to these kinds of buyers. We’ll know soon enough. The E1000 is going to be available starting in first quarter of 2020.

HPE Creates Its Own AI Stack For Large Enterprises
While the hyperscalers have been running AI workloads against vast datasets in production for a decade and a half, many large enterprises have lots of data they think is relevant but they are not at all experiences with AI and the system requirements it has. That’s where companies like Hewlett …

Even As Bandwidth Needs Explode, Ethernet Spending Is In Recession
No one like the R word, but we don’t shy away from data and calling it like we see it. And from what we can see from the most recent market research coming out of IDC, the Ethernet switch market has been in recession for two quarters now and very …
HPE Is Also Having Trouble Making Money With AI Servers
Hewlett Packard Enterprise has always been more interested in providing a choice of compute engines compared to Dell, which was the underdog in servers for a long time. Now, HPE is the underdog in general purpose serving but thanks to the acquisitions of SGI and Cray is the dominant supplier …
Cray’s performance claims for the ClusterStor E1000 should be taken with a grain of salt.
The previous ClusterStor L300 had similar performance claims (link 1 below) that its customers (link 2, sides 67 and 68 ) and its own benchmark engineers (link 3) could not come close to even halfway achieving. The last presentation (link 3) also shows the significant performance drop-off ClusterStor experiences as the Lustre file system fills, a “feature” neither IBM Spectrum Scale (with scatter) or Panasas PanFS has.
And Cray’s competitive claim that “none of those systems comes with automated services for data promotion and demotion across tiers” leaves NextPlatform readers (and hopefully such a knowledgeable reporter) familiar with IBM Spectrum Scale’s well known Information LifeCycle Management (ILM) automated tiered storage management facility, dubious of all Cray’s other competitive comparisons.
And what does “320 percent less throughput” actually mean?
https://www.seagate.com/files/www-content/product-content/xyratex-branded/clustered-file-systems/_shared/datasheets/seagate-clusterStor-l300-datasheet-11-06-15.pdf
https://www.hpc.kaust.edu.sa/sites/default/files/files/public/Seagate_Best_Practices-2017.pdf
http://wiki.lustre.org/images/1/18/Wed07-KaitschuckJohn-PaF_LUG2017v2.pdf