

If you want to see what the future of the Kubernetes container management system will look like, then the closed source, homegrown Tupperware container control system that Facebook has been using and evolving since 2011 – before Docker containers and Kubernetes were around – might be a good place to find inspiration.
Not that Google’s internal Borg and Omega cluster and container control systems have not been a fine inspiration for Kubernetes, which was open sourced by Google five years ago. Rather than grab the Borg code, clean it up, and dump it onto GitHub, Google created Kubernetes from scratch in the Go programming language (which it also created) and fostered a community around – to great success. At this point, no one is going to get fired for choosing Kubernetes as the container orchestrator as the heart of the next platform built for applications.
But that doesn’t mean other hyperscalers, such as Facebook, have not run into problems at scale – and solved them – in ways that Kubernetes has not wrestled with or solved, even if Google has internally faced similar issues with Borg and Omega. The pity is that Facebook is not going to create an open source version of the Tupperware cluster and container controller, or the new Delos storage service that is underpinning the current iteration of the control plane in Tupperware, both of which were discussed at Facebook’s System @scale event late last week.
The Tupperware system is very precisely constructed to run Facebook’s application and data services and it would be difficult to create a generic version of the controller that could plug into and support the wide variety of services that run in the enterprise. The same was true of Borg and Omega at Google, and it has taken considerable effort to rewrite the core parts of Borg and Omega in Go and make it a generic cluster and container controller, and honestly, the Kubernetes platform is not done yet even if it has come a long way in five years.
And just to be clear, Chunqiang Tang, an engineering manager at Facebook who works on Tupperware and who was previously in charge of cloud automation research at IBM’s TJ Watson Research Center, tells The Next Platform that Facebook has no plans to take its learnings from Tupperware and then apply them and converge onto Kubernetes, as Google might someday do if it can. (Already, there are lots of Google services that run atop Kubernetes on Google Cloud Platform instead of on Borg/Omega on bare metal.)
While Facebook has no current plans to open source the Delos low-latency, pluggable API data store that is being used with Tupperware, Jason Flinn, a professor of computer science and engineering at the University of Michigan who worked on the Delos project with Facebook, hinted that this project started only a year ago and has only been used in production for about four months, so it is early in the cycle to be opening it up, even if it is a possibility in the long term.
The point is, right now the revelations on Tupperware and Delos at the Systems @scale conference can be used to inform and inspire other cluster and container management and storage subsystem efforts, both open and closed source. A MapReduce paper from Google in 2005 led directly to Yahoo creating Hadoop, after all.
We are as interested in the insights that Facebook can provide in running infrastructure at scale as in the technical details of the two sets of code. The insights are applicable to many, even if the code is applicable to only one.
In terms of scale, Tang says that Kubernetes cannot hold a candle to the scale of Borg/Omega and certainly not to Tupperware. When it was first rolled out, Kubernetes struggled to run on hundreds of servers, and a year later it broke through 1,000 nodes. Today, according to Tang, Kubernetes tops out at managing about 5,000 nodes. This is nowhere near the scalability of Borg or Tupperware. The physical clusters in a Google and Facebook datacenter span around 100,000 machines or so, and multiple datacenters comprise a region. At Google, these physical clusters are carved up into cells by Borg, which have in the past averaged around 10,000 nodes, but some scaled down to a few thousand nodes and others scaled up to as high as 50,000 nodes.
When Tupperware was originally conceived, Facebook though in terms of racks, clusters, and datacenters just like most datacenters did and it organized Tupperware around these constructs, which often had physical configurations that were difficult to transcend. Also back then in the early 2010s, Docker containers did not even exist (and would not be production grade for many years), so Facebook used chroot at first to sandbox applications so they could be run at the same time on one physical Linux server, just like Google had been doing for quite some time; as namespaces matured, Facebook also adopted these to provide a little more isolation between workloads. As you know, cgroups and namespaces, which were created by Google and donated to the Linux community, were the foundation of both Docker and Linux containers, and Facebook deployed Linux containers and extended them in one direction internally while Docker grabbed Linux containers and evolved them in a slightly different way. (That is an oversimplification, we realize.) Our point is, Facebook was a few years behind Google when it came to containerizing, and it eventually faced the same problems and solved them in a slightly different way. And that problem is that you cannot drive efficiencies by managing at the cluster level; you need to span datacenters and regions, ultimately.
These days, Tupperware does not think in terms of racks, clusters, and datacenters, but provides an abstraction layer that spans multiple datacenters across a region, which could be several hundreds of thousands of physical servers, or that sometimes spans multiple regions around the globe. Tupperware has evolved from an operational tool managing clusters to an intentional one, where programmers deploying applications at Facebook say simple things like Deploy this application to run in different datacenters within the Prineville region or Deploy this application across the Prineville and Lulea datacenters and Tupperware figures it all out based on the availability of iron. This is not serverless computing – which is an idiotic term as far as we are concerned – as much as it is system adminless computing, which is the ultimate end goal of all datacenters, if you want to be honest about it. (The system admins don’t, unless they plan to be the one remaining Site Reliability Engineer employed by their company)
That cluster management barrier was a big one for Facebook to crack, and it did it with a tool called Resource Broker, which allowed the social network to schedule maintenance on clusters by moving work from one cluster to another by loosely coupling clusters to their schedulers. Resource Broker also kept tabs on the capacities and availabilities of all of the servers in the Facebook fleet.
Once the link between the Tupperware scheduler and the physical clusters was broken, things started to ease up a bit. Now, within each region or across regions, the scheduler work is sharded and each shard manages a subset of the jobs running across Tupperware, but the key thing is that all of these shards are aggregated to present a single view of all of servers, containers, and workloads under management. Interestingly, Tang says that the allocator inside the Tupperware scheduler that is responsible to allocating containers to servers under its management is powerful enough to handle an entire Facebook region without sharding. (That doesn’t mean that Facebook doesn’t shard the Tupperware work for other reasons.) There is a Tupperware daemon on each server, which brings up and tears down containers, which are created using a homegrown format in the BTRFS file system and managed by systemd.
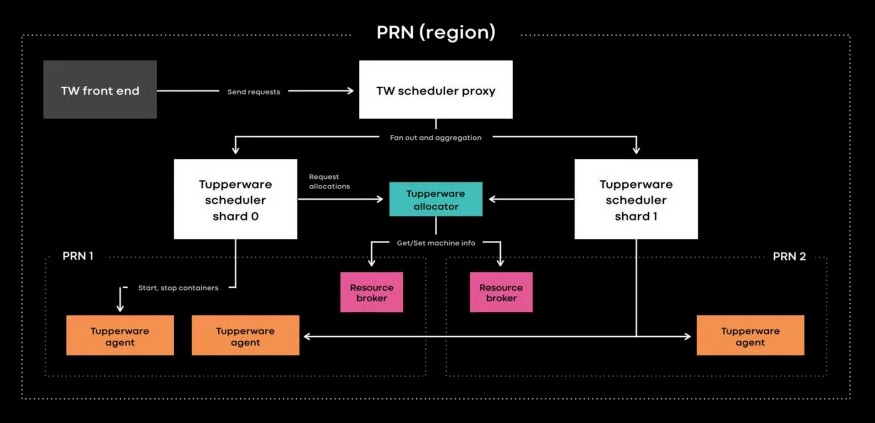
Here is the fun bit. Facebook has been on the spearpoint of the move to single-socket servers, notably with the “Yosemite” microservers that are widely deployed to run infrastructure software at Facebook. Here the effect of this. Each Facebook datacenter now has more physical servers as it might otherwise have with more standard two-socket machines, and that puts more load on Tupperware, and Moore’s Law is increasing the cores and therefore the number of containers that each node can support. Hence, the need to shard the Tupperware work, but the desire to keep the interface to Tupperware a single pane of glass.
But there is another mission at work here. Ultimately, Facebook wants to be able to manage its entire fleet from one pane, and that is going to require a lot more sharding of Tupperware work and similar sharding of storage related to workloads on the Facebook network. Thus far only about 20 percent of the servers it has installed are included in this giant shared pool of resources, but ultimately Facebook wants to be able to use its global resources whenever and wherever they are available and stop thinking in terms of datacenters and regions at all.
Here is another interesting observation. The way that Borg thinks about workloads, there is online work and batch work, and the main job of the scheduler is to fill in spare capacity with batch work (like MapReduce data analytics jobs) until the online work (such as filling search engine requests) requires more capacity. So these two types of work are interleaved on systems, scaling up and down their usage side by side as need be to drive up utilization.
Facebook takes a different approach and thinks at the raw server level. First of all, with microservers, the amount of raw compute in each server node is smaller, so there is less to carve up than with a two-socket machine (that is changing with the high core counts in the AMD “Rome” Epyc processors). At Facebook, programmers are taught to code in such a way as to use all the capacity they can in a server. At night in each region, when News Feed, Messenger, the web front end, and other tiers of the application are not being used heavily, the server nodes in a region do all kinds of batch work such as MapReduce analytics and statistical machine learning. (Not everything is deep learning requiring GPUs, after all.) So rather than having to worry about how much of online or batch work to deliver to different containers on each physical server with Resource Brokers, Facebook just allocates either batch or online work to each server and makes sure it runs full out to get the most value out of the IT spend. This is an interesting distinction between Google and Facebook, where the container is really more of a deployment mechanism than a workload isolation tool.
There is one other area where Facebook is claiming bragging rights over Kubernetes aside from scale, and that is in managing stateful applications – such as the databases and datastores behind Facebook, Instagram, Messenger, and WhatsApp, which includes ZippyDB, ODS Gorilla, and Scuba – as opposed to stateless applications – such as the Web and PHP servers that comprise the front end of Facebook’s applications. The Tupperware controller has a service added on to it called TaskControl that looks at the dependency of applications on maintaining a stateful link with their storage and then decides, based on those needs, how to deploy containers running those applications and update and move them as necessary without breaking that stateful link and thereby corrupting or crashing the application. TaskControl works in conjunction with a data service called ShardManager, which makes decisions about data placement and replication in the Facebook network. This is all done automatically, without programmers having to fuss with it.
Control At Scale Takes Storage At Scale
As you might imagine, managing the data for the control plane in Tupperware and other Facebook services is a big job, and to that end Facebook was talking about Delos, a new replicated storage system that is being deployed in control planes in the Facebook stack that could end up being the architecture ultimately used for file and object storage.
Up until Delos was created, data used in the various control planes for Facebook’s software were stored in all different kinds of ways, some using MySQL, some using ZooKeeper, some using other key-value stores or databases. Like most companies, every unique application seems to require a unique datastore or database, with its own API, performance, fault tolerance, and deployment methodologies. These storage systems for control planes often have to be designed from scratch and rewritten each time a new set of features are added to those control planes. This is a pain in the neck, and the wallet.
So, Facebook threw out monolithic storage system design with Delos, Flinn tells The Next Platform.
“The idea behind Delos is we’re building a storage system around the novel abstraction of a reconfigurable, virtual, distributed share block, and this allows us to meet a lot of the unique goals of the control plane,” explains Flinn. “So you have the standard things for highly reliable storage: It has to be highly available, it has to be strongly consistent. It also has to have a fairly rich API, with things that look like relational queries with secondary indices, with a little bit of query planning and complex predicates. It also has to run on a wide variety of hardware, our latest and greatest machines with their best storage for sure, but it also should run on older machines that might be co-located with the services that it happens to be providing metadata to. And then finally the biggest requirement for this, in my mind, and one of the unique things that Delos offers, is that it has to have zero dependencies and it really is designed to sit at the bottom of the stack. This simplifies things like bringing up a new datacenter, recovery, and so on.”
The key idea behind Delos is that the state of data – what is called materialization – is separated out from the ordering and durability aspects of the storage, and that more complex logs with various levels of fault tolerance or replication can be built up from relatively simple logs. Like this:

The VirtualLog can switch modes, operating in one SimpleLog format after another while still maintaining state at the higher materialization level, which is how relational, key-value, file system, and other APIs are exposed to the outside world. The beautiful thing about this is that the lower levels of the storage system can be completely changed without breaking the upper API layer, which means two things: A storage system can have multiple, concurrent personalities and it the different layers can be updated independently from each other as needed.
The first use case for Delos was to create a relational system called DelosTable, which was slide underneath the Tupperware Resource Broker and replaced the customized ZKLog system that Facebook had created from the open source Zookeeper project that is part of the Hadoop stack. At first Facebook shimmed the DelosTable to run atop ZKLog, and then after four months it was able to swap out this ZKLog layer with a native SimpleLog format, based on the LogDevice system that Facebook open sourced a while back – on the fly in the production Tupperware environment. Here are the performance profiles for each different log format running Tupperware’s Resource Broker:
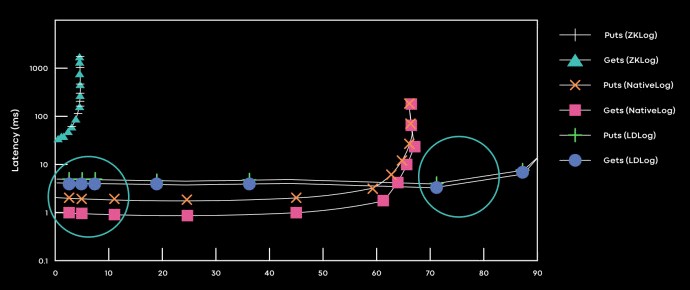
“We dynamically switch between the disaggregated LogDevice ordering layer and the converged native log ordering layer based upon latency SLAs,” Flinn explained in the Delos post. “We choose the converged implementation (which uses fewer resources and has no critical-path dependency) when a latency SLA can be satisfied, and we switch to the disaggregated implementation when the latency SLA is violated.”
Obviously, there are huge benefits in reduced latency and higher throughout with the LogDevice format and even the NativeLog format over using ZKLog, which benefits the Tupperware control plane. And when the next idea comes along, it will be relatively easy to snap it into Delos and push performance or scalability even further.


Google Teaches AI To Play The Game Of Chip Design
If it wasn’t bad enough that Moore’s Law improvements in the density and cost of transistors is slowing. At the same time, the cost of designing chips and of the factories that are used to etch them is also on the rise. Any savings on any of these fronts will …

Docker Helped Invent Containers, And Is Now Reinventing Itself
Containers are still the hot new technology in the datacenter to some, but many of the pieces and parts that eventually would find their way into today’s container platforms have long-since been used by enterprises and developers thanks to Docker. The company, which was founded a decade ago, pulled those …

Datacenter Infrastructure Report Card, Q3 2023
It is hard to keep a model of datacenter infrastructure spending in your head at the same time you want to look at trends in cloud and on-premises spending as well as keep score among the key IT suppliers to figure out who is winning and who is losing. And …
Moore’s Law has less to do with the “density” problem than the technology, the development pattern itself. By not having to run an Operating System for each instance of an application by default you can now run dozens if not hundreds of applications on a single host (node). If clock speed and transistor count hadn’t changed in the last 10 years we’d still have the problem of failure domains and workload density.
How does the TaskControl service (i.e. “maintaining a stateful link with [containers’] storage…”) differs from Kubernetes’ StatefulSets and PersistentVolumes.
Facebook was forced to create its own technology for adjusting and managing billions of its users. Facebook has its own in-house tools manufactured as open source. Open source plays a fundamental role in Facebook’s mission to build a strong community and bring the world closer. Facebook’s open-source programs encourage others to release their sources as open-source while working with the community to support open source projects.
Where is tupperware now, why there is no fingerprint of it on the web at all