

Multi socket servers have been around since the dawn of enterprise computing. The market and technology has matured into 2-socket x86 and multi core highly integrated processors. In this piece, I hope to answer some questions about how we landed here and what is the likely future.
Large symmetric multiprocessor systems (SMP) once ruled the enterprise, much like the dinosaurs roamed the earth. This was required due to many factors (1) process technology only allowed single core CPUs (2) large scale networks did not exist, or at least were not economically viable (3) applications were oriented around terminal – mainframe experience. These factors prevented the notion of large scale out systems and applications like we have today. As those factors changed, enterprise started to shift from large SMP machines to scale out systems of moderate socket counts (2 & 4 socket predominately). Process technology and large networks disrupted the economics and continued to where we are today with scale out 2-4 socket with many-core CPUs.
But why did we stop at 2-4 socket systems? Why have we not made the last transition to 1-socket? There have been several reasons in the past, but I’m not sure they are valid anymore. As we made the transition from mainframes to scale out, the CPUs were single core, and the cost economics of sharing north bridges, south bridges, and memory controllers made a ton of sense. With the dawn of multi core and the integration of memory controllers there was still a valid argument to share IO devices, south bridge, PSUs, fans, etc.
But today we are entering the era of high power, highly integrated many-core CPUs and the argument to share what’s left – IO, PSU, fans, etc is becoming very weak. In fact, it is leading to power and performance challenges. The CPUs today and moving forward are equal in power to 2 to 4 of the CPUs of the past – we are talking 250W+ CPUs with 32 cores and higher power/core count in the future. This has led to the demand for more memory, more NVMe drives… and thus more power per U. Each socket has so much performance (many cores) you really should *not* share IO between sockets, in fact doing so negates performance – read on. Years ago, in our high volume 2U server the top PSU was 750 Watts and now we have standard PSU offerings up to 2400 Watts – our power per U has gone up 3x. This is leaving racks half empty and data center hot spots.
Dual socket servers are creating performance challenges due to Amdahl’s law – that little law that says the serial part of your problem will limit performance scaling. You see, as we moved to the many core era, that little NUMA link (non-uniform memory access) between the sockets has become a huge bottle neck – basically we have entered an era where there are the too many cooks in the kitchen. With 28, 32, 64 or more cores on each side trying to reach across the NUMA link to share resources like memory, and IO, not to mention cache coherency traffic, the socket size is blowing up. In order to keep the IO and memory bandwidth per core above water, there is a fight for NUMA link pins – and remember, more pins equals more power. For a balanced system though, the priority is core memory bandwidth first, then core IO bandwidth, and then lastly NUMA bandwidth – so we have a growing problem in multi-socket systems and it is the last priority to get pins. As an example, in a 2-socket system, the bandwidth to IO off CPU0 vs CPU1 can drop 25% while the latency can go up 75% during stress vs native traffic from CPU0 to the IO. See figures 1, 2, 3 – in figure 2 higher is better (bandwidth), while in figure 3 lower is better (latency). In this test we simply used STREAM to drive increasing stress and then measured network bandwidth and latency from CPU0 and CPU1.
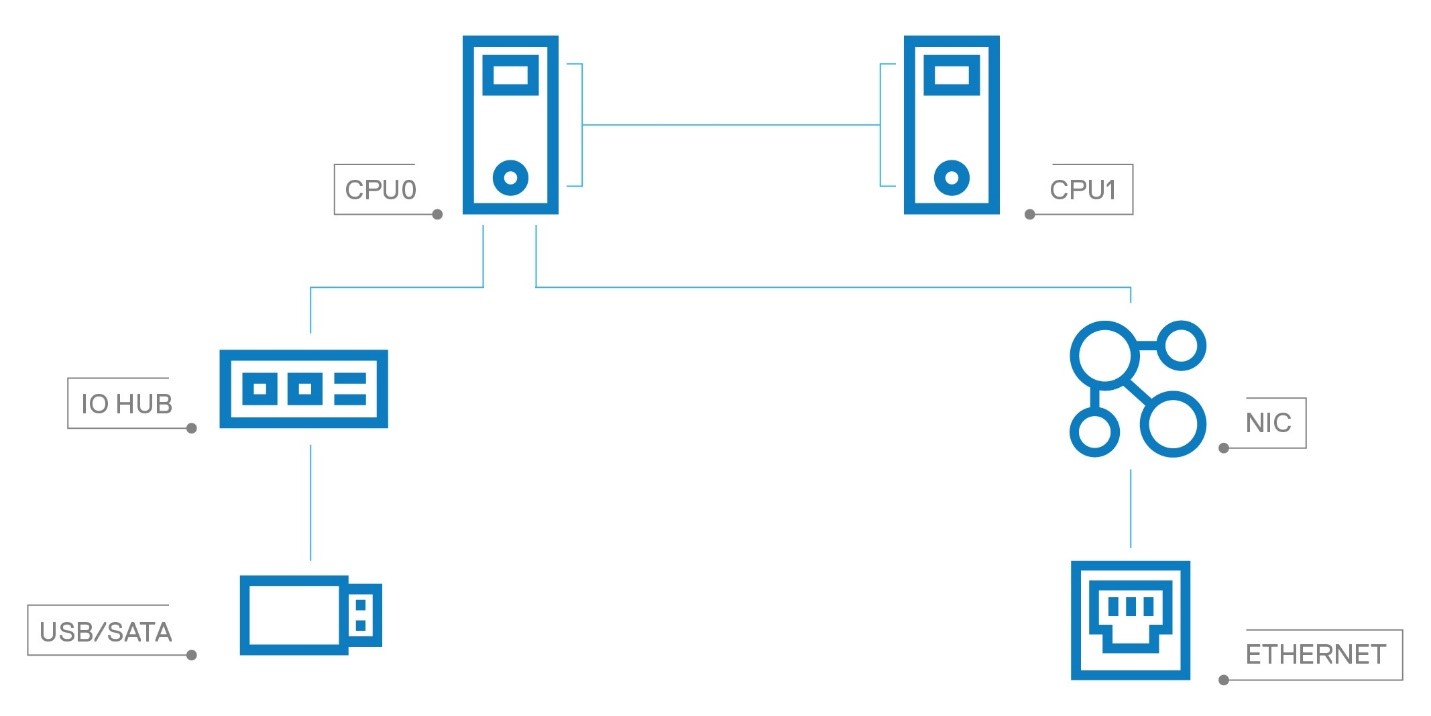
Figure 1: Typical 2 socket server
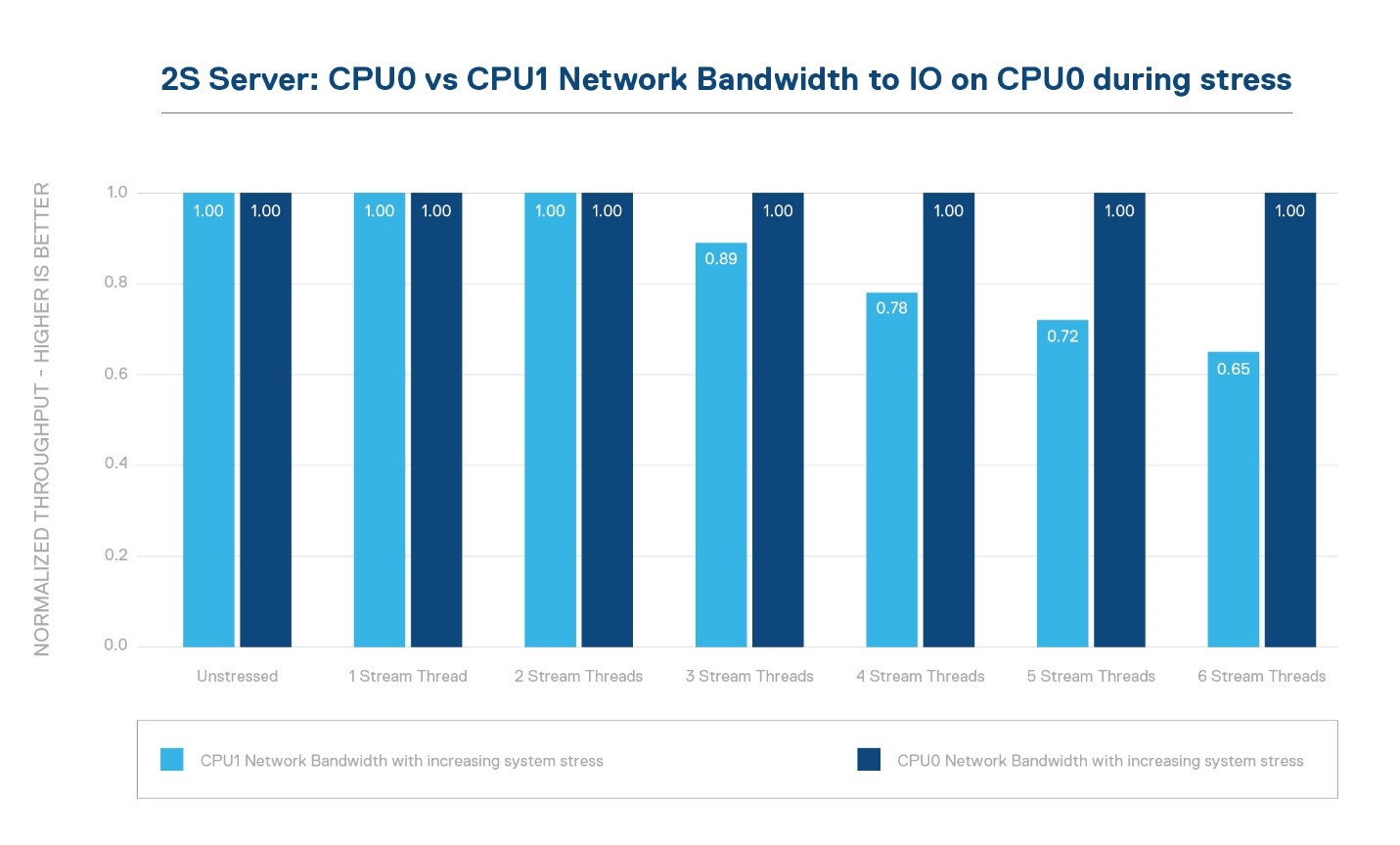
Figure 2: Network Bandwidth comparison from CPU0 vs CPU1
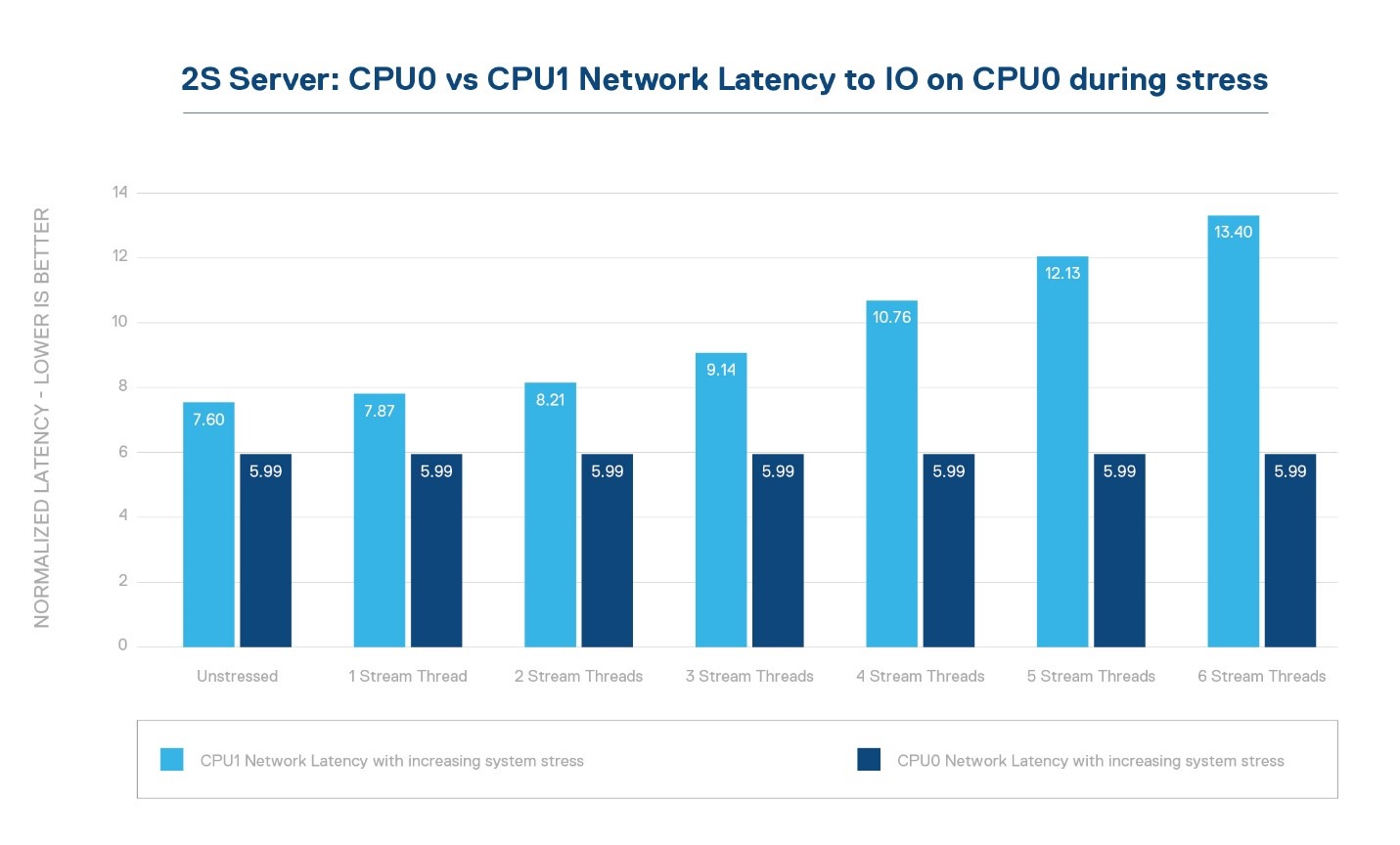
Figure 3: Network Latency comparison from CPU0 vs CPU1
Have you ever had strange application performance issues that look networking related? The perceived networking problem may not be a networking problem but rather a network bandwidth/latency issue created inside the server as shown above.
Another point to consider, Figure 4 shows the per core metric (memory/IO bandwidth, core count, cache size, etc) from 2003 through 2018. What you’ll notice is that at the per core metric view, memory bandwidth and IO bandwidth per core have been falling since mid-2011. And keep in mind this does not factor in the IPC (instructions per clock) improvements of the cores from 2003 through 2018. To fix this we need more pins and faster SERDES (PCIe Gen4/5, DDR5, Gen-Z), 1-socket enables us to make those pin trade-offs at the socket and system level.
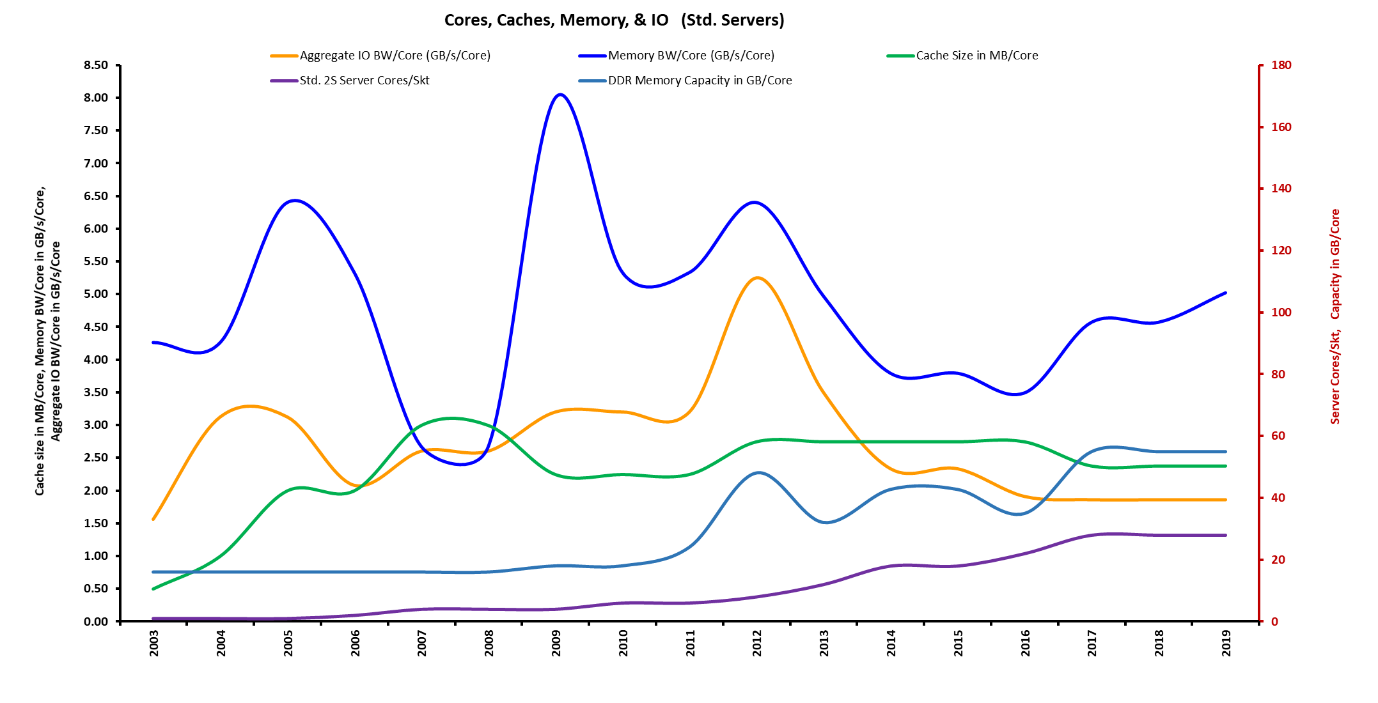
Figure 4: Standard 2S metrics per core
Why has this happened and why now? Like I said it really comes down to Amdahl’s law, or too many cooks in the kitchen, and the pin count struggle. So, what do we do? Many in the industry, especially the high performance minded, work around the problem a couple of ways: (1) establish manual affinity of the applications you care about the most to the socket with the IO, or (2) double up on NICs and avoid the problem. When you think of cloud native in the future and 1000s of containers, affinity control is not a long-term answer. And if you fix the problem with dual NICs you’ve essentially soft partitioned a 2-socket server into 2 1-socket systems – and received nothing in return other than a bunch of NUMA link pins, a larger socket, higher power (2x NICs) and higher cost (2xNICs) … to avoid the problem.
There is another answer –1-socket servers could rule the future – and here’s why.
Robert’s top 10 List for why 1-socket could rule the future.
- More than enough cores per socket and trending higher
- Replacement of underutilized 2S servers
- Easier to hit binary channels of memory, and thus binary memory boundaries (128, 256, 512…)
- Lower cost for resiliency clustering (less CPUs/memory….)
- Better software licensing cost for some models
- Avoid NUMA performance hit – IO and Memory
- Power density smearing in data center to avoid hot spots
- Repurpose NUMA pins for more channels: DDRx or PCIe or future buses (CxL, Gen-Z)
- Enables better NVMe direct drive connect without PCIe Switches (ok I’m cheating to get to 10 as this is resultant of #8)
- Gartner agrees and did a paper. (https://www.gartner.com/doc/reprints?id=1-680TWAA&ct=190212&st=sb).
Let’s take this one by one with a little more detail.
There are more than enough cores per socket and trending higher – does anyone disagree? And if you look at all the talk of multi-chip packaging, more core per socket is the path till we figure something new, and move away from the Von Neuman Architecture.
Replacement of underutilized 2S servers – again, an easy one; why have a 2-socket system with 8-12 cores per socket when you could replace with single socket 24+ core and not degrade performance below what you paid.
Easier to hit binary channels of memory, and thus binary memory boundaries (128, 256, 512…) – if we free up pins we can more easily stay on 2,4 or 8 channels of memory and not have to deal with those odd 3, 6, 9 channels. This will reduce the situations where we either don’t have enough memory (384) or too much (768) when we needed 512. These are binary systems after all.
Lower cost for resiliency clustering (less CPUs/memory….) – this is an easy win, thinking about 3 node HCI clusters, we need a 3rd node to be a witness essentially. If this was deployed with 1-socket systems, we only need 3 CPUs instead of 6.
Better software licensing cost for some models – while ISV licensing varies, some license by socket and some by core count. Gartner did a paper – Use Single-Socket Servers to Reduce Costs in the Data Center – which showed about a 50% licensing cost reduction for VMware vSAN. I would not count on ISV licensing models as long-term reason though, ISVs tend to optimize licensing models over time. If I were an ISV, I would license by core with a multi socket kicker due to increased validation/testing as you scale beyond a single socket.
Avoid NUMA performance hit – IO and Memory – I think I pretty much covered that above in the graphs. Data and facts are hard to ignore. Keep in mind, we need flat NUMA per socket CPUs to get this ideal result. Avoiding NUMA can also eliminate a potential application performance problem inside the server that looks like a networking problem.
Power density smearing in data center to avoid data center hot spots – this is an interesting area to think about and may not register for all enterprises. Due to power per rack U rising as explained above, we are creating hot spots and less than full racks. Not to mention server configuration limitations – how many times have you wanted A+B+C+D+E in a server and found it was not a valid configuration due to power and/or thermals? If we break a 2-socket server apart we can get better configuration options of NVMe drives, domain specific accelerators, etc… and then spread the heat out across more racks – aiding in better utilization of the power and cooling distribution in a data center.
Repurpose NUMA pins for more channels of: DDRx or PCIe or future buses (CxL, Gen-Z) – this is an easy win and you can see the results in the Dell PowerEdge R7415 and R6415 already. AMD EPYC provides this flexibility and Dell EMC was able to provide this advantage to our customers.
Enables better NVMe direct drive connect without PCIe Switches (ok I’m cheating to get to 10 as this is a result or #8) – this is a direct repercussion of repurposing NUMA links and exactly what we did on the PowerEdge R7415 and R6415 to allow high count NVMe drives without added cost, power, or the performance impact of PCIe switches.
Gartner agrees: Gartner did a paper – Use Single-Socket Servers to Reduce Costs in the Data Center.
So, there you have it, a bit of history, some computer architecture fundamental laws at play, the results of some testing and finally a top 10 list of why I am bullish on the future of 1-socket servers.

Point #11: To avoid wasted sockets! I read recently that most two-socket servers that are purchased by enterprises only ever have one of the sockets populated with a CPU, and this is true of all of the servers at my (tiny) workplace. Why buy a two-socket server and then not use a socket? Because, historically, single-socket servers been wimpy and have lacked redundancy features such as dual PSUs, which is why we did this.
Very interesting article! I predict an evolution to a “per-core” license model (instead of the current predominant “per-socket” model) for all the software companies all over the world! 🙂
A lot of enterprise software has long been licensed per core, for precisely this reason.
Taking the AMD EPYC as an example, this is a multi-modular chip design. The single processor has 4x 8 core dies within it, each with its own memory channels assigned, effectively it has 4x NUMA nodes within a single processor. The problem is that you are seeing the same issues with this design as you are in a traditional 2 socket systems with regards to NUMA, as any communication between the modular 8 core dies to non-local memory has to go across the infinity fabric and therefore causes latency. The problem is compounded by the fact that the multi-chip 8 die chips and associated memory (aka the NUMA node) is quite small so NUMA is more common than on a 2 socket system that is using more cores.
I can see this improving with ROME, as the die cores increase to 16 and the NUMA nodes increase. Within virtual environments especially this is something to be aware of where large VM’s are being employed
Rome is scheduled to have 8, 8 core Die/Chiplets fabbed on TSMC’s 7nm node and one GF fabbed 14nm I/O die that hosts all the memory controllers and external I/O SERDES. So the entire topology of Epyc/Rome is a bit different from those first generation Epyc/Naples Zen/Zeppelin Dies that each came with 2 local memory channels on each Zen/Zeppelin die.
So the NUMA topology of Epyc/Naples and that Zen/Zeppelin Die was more NUMA on the MCM while the Epyc/Rome Zen-2 micro-arch based MCM will go back to a single 14nm I/O die that hosts the memory channels and a UMA topology.
There are advantages and disavantages to both UMA and NUMA but apparently it’s a bit simpler for on some Non Linux OS to not have to manage NUMA compared to Linux which has less issues with managing the NUMA Topology.
Epyc/Rome on the Zen-2 micro arch and that 14nm I/O die topology meant that all memory accesses on Epyc/Rome will be a 1 hop far accesses to the 14nm I/O Die so there will be some change in initial latency compared to the older Epyc/Naples Zen/Zeppelin Die Topology that had 2 memory channels on die that could be accessed locally.
What Epyc/Rome will offer is loads more Cache espically in the L3 cache sizes per Epyc/Rome Die/Chiplet and per CPU core. So much more L3 cache and less overall Cache Miss rates on Zen-2 on that Epyc/Rome UMA Topology.
And the one nice thing about Epyc/Rome’s new Topology is that the 14nm I/O die can be improved upon without having to do an whole new 7nm Die/Chiplet Tapeout. So AMD could bring some incremental improvements to the 14nm I/O die and that can be abstracted away by the hardware on the 14nm I/O die with the 7nm Die/Chiplets none the wiser regarding whatever abstractions are managed by any newer I/O die’s hardware/firmware.
And Yes there is the possibility of adding more 8 core die chiplets, ore more cores per Die/Chiplet with Epyc/Milan on 7nm+/6nm(TSMC has announced a 6nm Process) for AMD’s Zen-3 micro-arch based offerings.
There is also the possibility of some L4 cache on that 14nm I/O die also. But if not for Epyc/Rome then maybe for Epyc/Milan and something similar to IBM’s Centaur chips that offer L4 cache in an effort to fruther reduce the need for the more coatly and latency inducing system DRAM accesses. So more ability to hide any latency inducing memory accesses with an extra layer of cache memory being located on the I/O die.
So any disadvantages that may appear on Epyc/Rome on Zen-2 regarding that 14nm I/O Die and the UMA topology will be mostly ameliorated by larger L3 cache sizes and the more then doubling of the Infinity Fabric V2’s total effective bandwidth per IF lane.
The exact nature of all of Epyc/Rome’s features sets will have to wait for the product’s final release as there are still things remaining to be revealed that are still currently under NDA. Just remember that cache memory is all about latency hiding as is SMT and other buffers on modern microprocessors.
Most common server workloads may not be as single processor thread dependent as compared to some workstation workloads but more cache sure helps for those workloads that are single processor thread dependent where there is some memory access topology that’s not as local as it once was.
If the entirety of your code resides in some level of cache as opposed to system DRAM then that slower system DRAM is not as much of an issue. Data is usually the part that requires on average a bit more memory than most code but that can be less of an issue if the data can be requested in advance of being needed by the processor as in staged in some cache level programmatically. L4 cache really helps there also with data staging and each level of cache offers more chances to hide latency in the background and keep the processor cores operating at fuller capacity for longer periods of time.
“2400 Watts – our power per U has gone up 3x” – Surely this is peak power?
2400W is the faceplate rating of the power supply.
Nice article. I’m on the fence. I understand the attractiveness of the position which may be easier to take than bringing most IT shops up-to-par on how to even make sure the PCIe cards are slotted optimally.
The elephant in the room is whenever you break apart these systems, you are trading what may be a pvNUMA constraint, on a motherboard, for a much bigger pNetwork constraint. If the servers are designed correctly AND the workload is large enough, then those pNUMA links will outperform (in terms of shear latency alone) almost heavily networked ethernet (not IB) connections. The reason I’m flagging this is b/c it’s a tough sale to entrenched networking teams who either have no clue about the real impacts of latencies or choose to ignore it anyways.
Consider when an application is containerize and those containers scattered over datacenter the size of a football field vs in a a limited number of 2S or 4S setup – you do the hopping and distance math. For a latency sensitive app with millions of frams-per-second, it’s an immediate issue. For a throughput sensitive app, it’s still an immediate issue. Combine them as in AI, ML and Analytics and well now we have a still bigger gotchas to overcome beyond making sure the pNUMA boundaries are understood. Look at what NVidia’s did with AIRI / DGXn to better understand what they are avoiding.
I’m still sleeping on the article… Cheers!