
In the modern distributed computing world, which is getting ever more disaggregated and some might say discombobulated, as every day passes, the architecture of the network in the datacenter is arguably the most important factor in determining if applications will perform well or not. All the servers in the world, with all of the speed and capacity that money can buy, won’t mean a thing if dozens or hundreds of servers cannot talk to each other across the datacenter at predictable speeds with enough bandwidth to push and pull data and latency that is low enough to keep it all in balance.
It is, therefore, a tricky thing to create a network that, as is the case with Facebook, ends up running what is a giant distributed PHP application (with lots of machine learning woven into it) that links together the timelines of 2.3 billion users across untold millions of servers stacked up in fifteen datacenters around the globe. And that network has had to evolve over time to meet the performance, resiliency, and cost targets that the social network’s business demands. Networking has been the fastest growing part of the overall IT budget at Facebook during the 10 Gb/sec and 40 Gb/sec generations of Ethernet, and that was not so much because bandwidth was constrained as both bandwidth and port counts on a switch ASIC were both constrained. But with the most recent generations of switch ASICs available on the merchant market, the port count and the bandwidth per port are both on the rise, and Facebook now has an unprecedented chance to flatten its networks, radically cut its costs, and still yield much better performance than it has been getting out of its prior generation of switches and fabric.
The key, as we have pointed out before, is not so much the bandwidth, but that the advent of switch ASICs that can drive 200 Gb/sec or 400 Gb/sec ports means that the number of ports per switch can be doubled or quadrupled compared to early generations of 100 Gb/sec switches, which were too hot, too expensive, and were port constrained. Rather than putting in fatter pipes, companies running at hyperscale are putting in fewer layers in their networks, cutting down hops along the fabric while at the same time spanning upwards of 100,000 servers and storage servers in a single fabric – the scale of a modern hypercale datacenter these days.
This high radix use of bandwidth – which is just a funny way of saying a switch maker takes the extra bandwidth enabled by Moore’s Law advances in chippery to make more ports at a set speed than the same number of ports at a higher speed – was something we talked about more than a year ago when Broadcom announced its “Tomahawk-3” StratusXGS ASIC, which can support 32 ports running at 400 Gb/sec or 128 ports running at 100 Gb/sec and when Arista Networks, the upstart switch maker that has rode the hyperscale wave better than any other networking company so far, rolled out its 7060X switches based on the Tomahawk-3 last October.
Back then, the high radix implementation of the Tomahawk-3 was theoretical, but at the OCP Global Summit in San Jose last week, Facebook showed how it was taking the theory and putting it into practice in the next generation of switches, called Minipack, and the fabric that works with it, called F16.
When Facebook opened up its first datacenter back in Prineville in 2011, it had custom servers and storage and was still using commercial fixed port switches at the top of server racks and commercial modular switches at the core; the word on the street was that Arista and Cisco Systems were the big suppliers of switches at the time, and these switches were not cheap by any stretch of the imagination and that is why networking was quickly becoming 25 percent of the overall datacenter cost and rapidly heading towards 30 percent. This was unacceptable to do at the scale Facebook needed, which is obvious enough, but it is also true that it is equally unacceptable to take the same approach at an HPC center or a large enterprise or a cloud builder, and the Clos leaf/spine networks that have subsequently come out of the hyperscalers and are becoming the dominant architecture for networking in the datacenter – and this is important, and what The Next Platform is obsessive about – scale down as well as scale up. The switch and fabric designs that are suitable for spanning 100,000 servers in a hyperscale datacenter can be used to affordably lash together hundreds, thousands, or tens of thousands of servers in the real world.
In that original Facebook topology, a pod of four cluster switches were cross-coupled to link together a pod of server racks; this was the management domain scalability of those commercial core switches (we don’t know how many ports they had) and that limited the size of a server pod and hence the way workloads were distributed across systems. With east-west traffic between machines dominating the network traffic, jumping across the pods added unacceptable latency for applications, which meant Facebook was partitioning applications and sharding them across pods. It was much better to have a network that could span the entire datacenter, and thereby link all of the compute and storage servers to each other, and also easily aggregate the datacenters within a region. (More on this in a minute.)
With the new F16 fabric, the once-modern fabric that was first deployed in 2014 in Facebook’s Altoona, Iowa, called simply Data Center Fabric, is being deprecated and is now referred to as the Classic Fabric. The F16 fabric gets around some of the limitations of the Classic Fabric, and a lot of those limitations really come from being able to pump four times as many 100 Gb/sec pipes out of a switch port as was possible at an affordable price and within a certain thermal envelope more than four years ago. At that time, Facebook was using 100 Gb/sec switching sparingly, for the network backbone across datacenters in a region and as the backbone between regions, with 40 Gb/sec networking at the leaf and spine layers down to the servers and storage servers that support its applications.
This shift in 2014 was when Facebook developed its own switch hardware for the first time, the Wedge top of rack (leaf) switch and the 6-pack core/spine switch, which was created out of modular Wedge 40 slices. The Wedge switch had 16 ports running at 40 Gb/sec plus a “Group Hug” microserver. The 6-pack modular switch had a dozen of these Wedge boards in a modular system, with eight of them providing 128 downlinks to the Wedge leaf switches and four of them being used to create the back-end, non-blocking fabric between the Wedge modules in the spine switch. The basic pod of networking with the Classic Fabric was a cluster of four spine switches that fed into a series of 48 leaf switches, creating many paths between the leaf switches in the pod and equally importantly enough extra ports in the spine switches to jump across pods almost as easily. It was this hardware that provided the foundation for the Classic Fabric that interlinked all of the servers in a Facebook datacenter to each other. Here is what that Classic Fabric looked like:
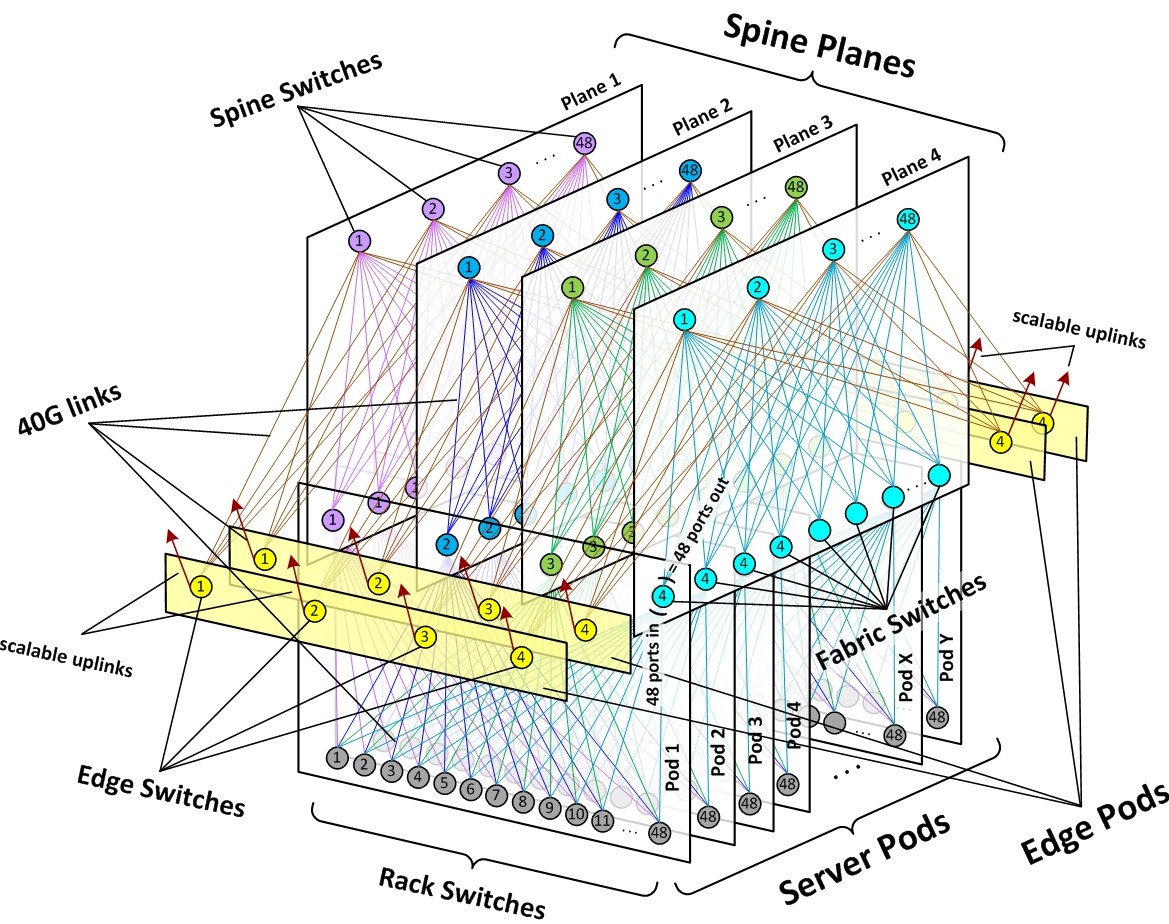
The neat trick is to organize the spines in planes of 48 ports, which reach down into the pods through the leaf switches. In the original Classic Fabric, Facebook was using 40 Gb/sec ports on the spine switches down to the leaf switches and then splitting the leaf switches down to 10 Gb/sec ports on the servers, which is how it could create a network that could span up to 100,000 compute and storage servers in a single instance of the fabric. What is also significant, but perhaps not obvious from the chart above, is that the fabric had edge network pods, capable of delivering 7.68 Tb/sec of bandwidth to the router backbone used by Facebook to connect its regions together and users to the datacenters as well as for inter-datacenter communications within a region.
Two years later, Facebook was moving on up to the 100 Gb/sec ASICs in the Wedge 100 leaf switch in early 2016 and to the Backpack spine switch in late 2016, which is a modular version of the Wedge 100 as was the case with 6-Pack spine switch and the Wedge 40. In this case, there were eight Wedge 100s used as line cards and four of them used as the non-blocking fabric inside the switch, which provided 128 non-blocking ports running at 100 Gb/sec per spine switch. Facebook has been gradually doing a global replace of the 6-Pack switches with the Backpack switches in its fabric and also replacing the Wedge 40s with the Wedge 100s, but the basic architecture of the Classic Fabric has not changed until now.
With the F16 fabric that is being rolled out in Facebook’s datacenters now, the network is being radically expanded as pressure at the top and the bottom of that Classic Fabric is mounting and as Facebook is expanding the number of datacenters it hosts in a given region. At the bottom of the fabric, there are increasing bandwidth requirements as applications make use of video and other services that need high data rates, and there is pressure at the top as Facebook expands across three datacenters in a region and wants to move it on up to six datacenters per region. (Fully loaded, this implies that the current 15 datacenters at Facebook could, in theory, house 9 million servers.)
In designing its Minipack spine switch and the F16 fabric that will make use of it, Facebook made an important decision, and that was not to switch to 400 Gb/sec ports on the fabric because the optics on the cables for such connections consume too much power today and they are not going to come down fast enough to keep the network from consuming a lot more power. So instead, Facebook decided to keep 100 Gb/sec ports, using established CWDM4-OCP optics, on the devices and instead quadruple the number of ports across the fabric and down into the rack to therefore quadruple the amount of bandwidth into and out of the racks. It is an interesting design choice, and once again shows that hyperscalers are always looking at the balance between performance and cost, rather than performance at any cost as HPC centers with capability class supercomputers often do.
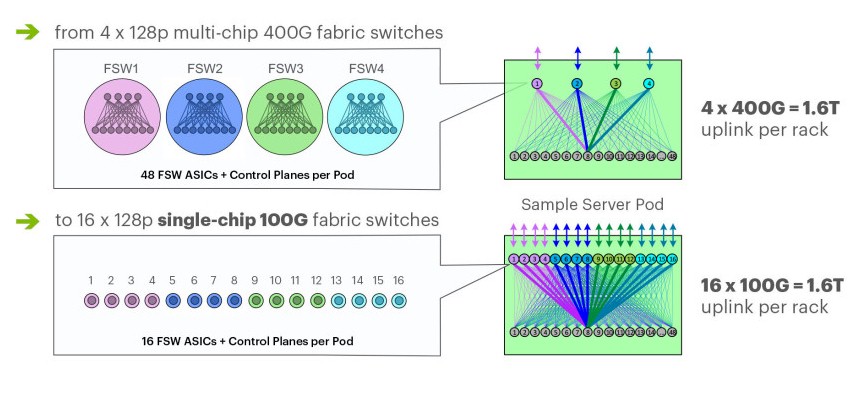
This choice had a number of effects, which once again made the network simpler, flatter, and less costly. The new F16 network can keep the Wedge 100 leaf switches right where they are and continue to use them, stretching their economic life. (There are few servers that need more than 100 Gb/sec of bandwidth into them, and many of these ports are chopped down to 25 Gb/sec with shared I/O across “Yosemite” microservers in the Facebook server fleet anyway.)
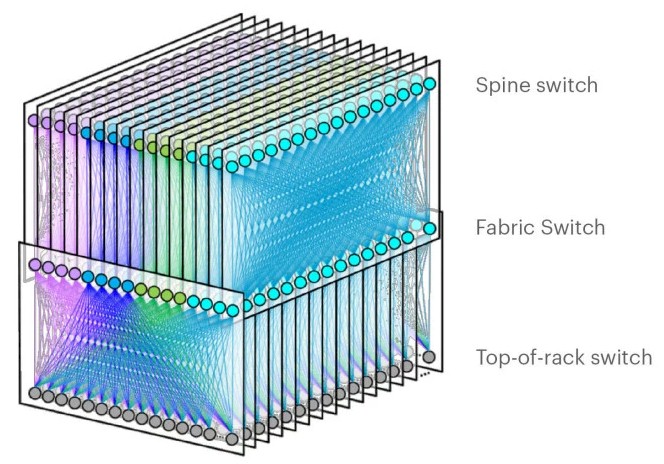
The F16 fabric topology is a bit different in that Facebook is scaling up the spine planes, which were built using sixteen 128-port 100 Gb/sec fabric switches instead of the four 128-port 400 Gb/sec switches – this is Minipack – you might have been anticipating. The spine switches are also based on the Minipack switch, which is a kind of hybrid between a fixed port and a modular switch. (More on that in a moment.) So with F16, each server and storage rack is connected to sixteen different planes, delivering that 1.6 Tb/sec of aggregate capacity into and out of the rack. Here is what that F16 fabric looks like:
These changes cause a radical reduction in the amount of silicon across Facebook’s network infrastructure without sacrificing bandwidth and without getting too far out on the cutting edge of optical transceivers and cables. To illustrate this, here is the comparison between the what Facebook could have done using the Backpack spine switch goosed to 400 Gb/sec based on the Tomahawk-3 ASIC and the existing Wedge 100 leaf switches based on the Tomahawk-2 ASIC and the actual F16 fabric using the Minipack spine and Wedge 100S leaf switches (a slightly improved Wedge 100S that came out last year) based on a mix of Tomahawk-3 (Minipack) and Tomahawk-2 (Wedge 100S) ASICs:
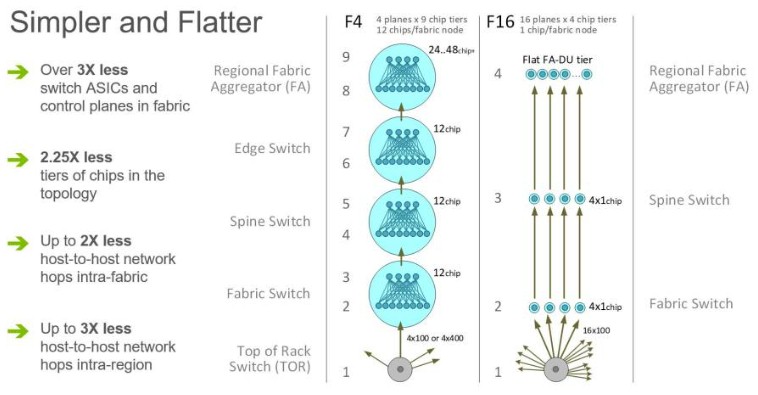
This is the key thing about this F16 network fabric, and one that everyone should pay attention to. There is a whole lot less silicon and a whole lot less hopping around the fabric to get from any one server in a region or datacenter to another server in a region or datacenter. Facebook network engineers Alexey Andreyev, Xu Wang, and Alex Eckert explained it very clearly:
“Despite looking large and complex on the schematic diagrams, F16 is actually 2.25 times flatter and simpler than our previous fabric. Counting all intra-node topologies, our original fabric consisted of nine distinct ASIC tiers, from the bottom tier (TOR) to the top of the interbuilding network in the region (Fabric Aggregator). The number of network hops from one rack to another inside a fabric ranged from six hops in the best case to 12 hops in the worst. But with small-radix ASICs, the majority of paths are of the worst-case length, as the probability of hitting the target that shares the same front-panel chip is low in a large, distributed system. Similarly, a path from a rack in one building to a rack in another building over Fabric Aggregator was as many as 24 hops long before. With F16, same-fabric network paths are always the best case of six hops, and building-to-building flows always take eight hops. This results in half the number of intrafabric network hops and one-third the number of interfabric network hops between servers.”
The heart of this new F16 fabric is the Minipack switch, which Facebook says will consume 50 percent less power and space than the Backpack switch it replaces in the network. The ports on the Minipack come in sleds with eight ports, which are mounted vertically in the chassis, like this:

Here is a schematic of the Minipack switch with a little more detail:
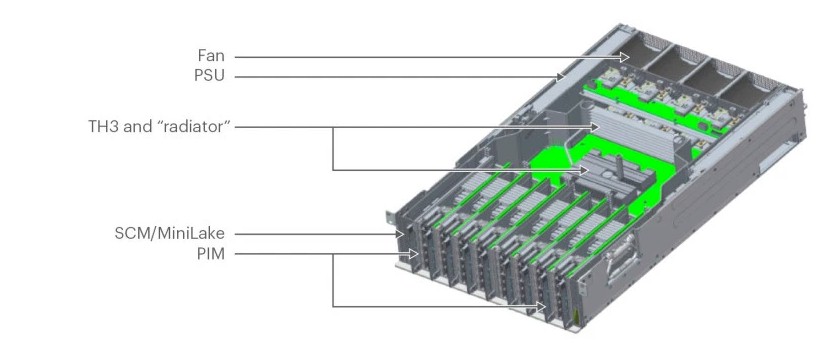
Minipack is not, strictly speaking, a fixed port switch, which generally has one or more ASICs in a box and the ports soldered onto the front, or a modular switch, which has a fabric backplane and then modules with individual ASICs and their ports that plug into to make what looks like a virtual fixed port switch. Facebook wanted a modular design that allowed it to add port cards as necessary, but still have them all backed by a single Tomahawk-3 ASIC. The interesting thing about this different modular approach is that Facebook is using reverse gearboxes to bridge the gap between 100 Gb/sec cable optics that support NRZ encoding and the Tomahawk-3 ASIC communication SerDes, which support PAM4 encoding. The Minipack port sleds will also support legacy 40 Gb/sec cables, current 100 Gb/sec cables, as well as future 200 Gb/sec or 400 Gb/sec cables that will run natively with PAM4 encoding when these become cost effective.
Arista Networks and Marvell are both creating clones of the Minipack switches right out of the chute, and Facebook has gone to Edge-Core Networks to make its own Minipacks and is also working with Arista for some units. They can all run Facebook’s homegrown FBOSS network operating systems, but will also be available using other network operating systems, depending on the vendor. The funny bit according to Omar Baldonado, manager of the network team at the social network, is that explained in his keynote on the F16 fabric and the Minipack switch is that a proof of concept manufacturing run at Facebook is larger than the production run at switch makers like Arista. So it needs multiple suppliers not just for production, but also for testing.
The Minipack switch is not just used in the fabric and spine layers of the Facebook fabric, but is now also being deployed in the Fabric Aggregator layer, called HGRID, which now has enough bandwidth and a lower number of hops that Facebook can link together six datacenters in a region, like this:

There are not many enterprises that need 600,000 servers all lashed together in a giant region. But every enterprise wants to have a network that costs less and scales better. And Facebook has shown, once again, how it might be done and has fostered an open ecosystem where companies can take its designs and commercialize the hardware to let the rest of the world benefit from its engineering.

A Hackathon To Battle The Coronavirus Pandemic
Public-private partnerships are common when responding to national or international crises and the current coronavirus pandemic that is expanding around the globe is no different. The tech industry is in the middle of it, with vendors donating millions of dollars to various private and non-profit organizations and governmental agencies, as …
Pushing PCI-Express Switches And Retimers To Boost Server Bandwidth
Things would go a whole lot better for server designs if we had a two year or better still a four year moratorium on adding faster compute engines to machines. That way, we could let memory subsystems and I/O subsystems catch up and get better utilization of those compute engines …

The Once And Future Federated Database
There are many different schools of thought when it comes to databases, which is one of the reasons that we launch our inaugural event focused solely on database technologies this year. But if you had to sum it up, it would look a bit like the following. After deploying a …
Be the first to comment