

The Open Compute Project started by Facebook nearly five years ago is in many respects a tier one server maker a tier one server maker that just so happens to have multiple manufacturers etching motherboards and bending metal instead of one. And while that may seem like a lot of time in the computer business, those five years represent only two generations and systems and storage and the first generation of switches that bear the OCP label and espouse its open hardware philosophy.
The OCP ecosystem is now has hundreds of companies – including end users, component suppliers, and system makers – that have thousands of people participating in the open hardware effort, and it is expanding out from the hyperscalers like Facebook, Rackspace Hosting, and Microsoft to financial services and telecommunications companies that have embraced the concept and are installing systems.
While the precise size of the OCP footprint in the datacenters of the world remains relatively small, the analysts at IDC reckon that by 2020 almost half of the servers sold into hyperscaler accounts will be based on OCP designs, and presumably OCP hardware will make its way into enterprise and HPC datacenters in a trickle down fashion from there. The telco and service provider segment spends a lot of dough on infrastructure, as do financial institutions, so seeing these organizations embrace open hardware first after the hyperscalers is not surprising. This is the natural path that technology advances often take.
Goldman Sachs and Fidelity Investments have been on the OCP vanguard, and Goldman Sachs has said publicly that since last summer, more than 80 percent of the servers it has installed in its datacenters are based on OCP designs. More recently, datacenter operator Equinix has spearheaded an effort to standardize on OCP servers, storage, and networking inside of its datacenters for its myriad telco and service provider customers, and the top tech brass from AT&T, Verizon, Deutsche Telekom, and SK Telecom came on stage at the summit last week to explain that they were aggressively adopting OCP hardware as they moved from dedicated network appliances to software-defined networking systems as they build out their next generation datacenters.
Just like competitors have lined up behind Linux and other open source software, competitors are getting behind OCP hardware or, in the case of the Chinese hyperscalers Baidu, Tencent, and Alibaba, creating their own standard. But before too long, they may join the OCP effort, too. As we already reported, Google has joined the open hardware project, and Microsoft joined two years ago and contributed its own server designs to the cause, giving it a supply chain for those machines that is much larger than the one Facebook created for itself by launching the OCP effort in the first place. As Microsoft explained to The Next Platform ahead of the summit, about 90 percent of the servers it installs these days are OCP compliant, and Rackspace told us that about half of the systems backing its cloud services (both virtualized and bare metal) are based on OCP designs, and it expects to hit somewhere around 80 percent to 85 percent in the coming years. Apple joined OCP last year – or more precisely admitted that it had done so, and if could have joined a lot earlier – and is rumored to be thinking of building its own infrastructure. With Amazon Web Services getting about 10 percent of its revenue stream from Apple, such a move would be a big hit to the AWS public cloud – perhaps enough to even compel AWS to join the OCP.
This, of course, was the effect that Facebook was looking for back in 2009 when it started designing its own servers, storage, and datacenters.
Adopting OCP does not mean literally having to adopt the OCP Open Rack and its 21-inch form factor, and in fact Goldman Sachs and Fidelity are using modified 19-inch racks and variants of Facebook server designs that fit in them, and Google is joining expressly to get a 48 volt, 19-inch rack standard into all datacenters that will benefit itself as well as others. (We think Google may eventually contribute server designs, too, for goodwill and practical engineering reasons.) ODM vendors such as Quanta and WiWynn are taking OCP motherboards and adapting them for 19-inch servers, and so are OEMs like Hewlett-Packard Enterprise, which is manufacturing the machines that Rackspace is putting underneath its next generation of OnMetal cloud servers. (We will cover these separately.)
“I think this will build a lot more momentum at the grassroots level among a much broader set of industries,” said Jason Taylor, president and chairman of the Open Compute Foundation and the vice president of infrastructure at Facebook, during his keynote referring to the 19-inch servers. While Facebook changed the rack size for good reasons, it could turn out that the 19-inch rack is more resilient than the social network thought, and the volume could all shift back in that direction.
 Ironically, it may be easier to change the size and shape of storage (which sets the dimensions in a rack more than any other factor) than it is to change the size of racks – particularly for companies that use co-location facilities and do not build their own datacenters like Facebook does. And this will be even more true as Facebook itself starts using co-location facilities, as Jay Parikh, another vice president of engineering at Facebook, said the company was doing during his keynote. Facebook can’t build a massive datacenter and span the world, so it has to revert to co-los and that will probably mean a 19-inch rack standard.
Ironically, it may be easier to change the size and shape of storage (which sets the dimensions in a rack more than any other factor) than it is to change the size of racks – particularly for companies that use co-location facilities and do not build their own datacenters like Facebook does. And this will be even more true as Facebook itself starts using co-location facilities, as Jay Parikh, another vice president of engineering at Facebook, said the company was doing during his keynote. Facebook can’t build a massive datacenter and span the world, so it has to revert to co-los and that will probably mean a 19-inch rack standard.
The big change that Facebook is projecting for its own datacenters this year is not with servers, but with networking.
“The trend in in networking over the last six years is too big to ignore,” Taylor explained. “It is absolutely crazy how much bandwidth you can get for about the same cost as what you paid six years ago compared to today. Six years ago, you would be building racks with 1 Gb/sec uplinks and 1 Gb/sec to the server and today it is completely cost efficient to deploy 40 Gb/sec networks and 100 Gb/sec networks. This is a 20X increase in the amount of networking you can provide per server in only six years. And that needs to affect every aspect of your infrastructure. If you are building file storage systems, all of that needs to be disaggregated. You need to take advantage of this exponential gain in networking and the amount of bandwidth per dollar that you can give your infrastructure. It kills me, but locality for anything having to do with networking in terms of disk or even flash is starting to become a thing of the past. For the next ten years, we are entering a phase where you really don’t have to worry about how much networking bandwidth you have within a datacenter and software and systems designs need to be taking advantage of it.”

The company has donated its Wedge 100 switch design to the OCP, which was unveiled late last year, and Taylor said that later this year it would start deploying these 100 Gb/sec devices in its massive Clos networks in one of its more recent datacenters, and Taylor said that by January 2017, its entire network would be operating at 100 Gb/sec speeds.
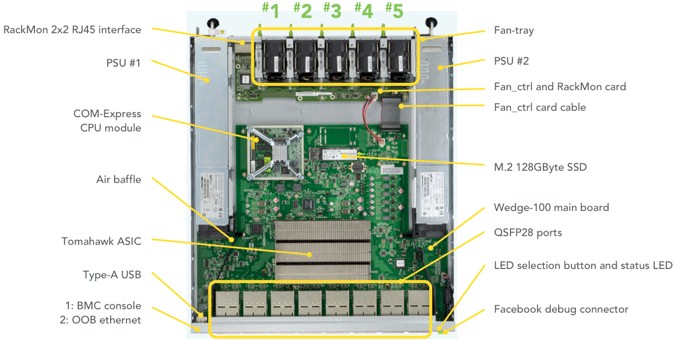
Last year, Facebook had not disclosed what switch ASICs and auxiliary CPUs it is using inside of the Wedge 100 switch, but this week it said that the initial implementation was based on Broadcom’s “Tomahawk” ASIC, which supports 25G Ethernet protocols running at 25 Gb/sec, 50 Gb/sec, and 100 Gb/sec speeds. The Wedge 100 is being equipped with splitter cables to link to the two different types of servers in use in its more recent datacenters that we have profiled separately – a four-way splitter to link to 25 Gb/sec ports on its two-way Xeon E5 “Leopard” servers and a two-way splitter to link to the 50 Gb/sec ports on the Yosemite microserver enclosures. The Wedge 100 is being manufactured by Accton, the same ODM that is making Hewlett-Packard Enterprise’s Altoline rack switches.
Breaking Up And Reassembling
The basic concept of Facebook’s system design is to keep breaking down components of compute, storage, and networking and then re-aggregating them in interesting ways.
“There is a struggle between being flexible and efficient, and these two things are always in tension, and it is a good tension if you can manage it carefully and how you think about your infrastructure,” explained Parikh.
The building blocks that Parikh talks about are, of course, the Open Compute product line, which is in generation two and looking ahead to generation three, probably more or less concurrent with Intel’s “Skylake” Xeon E5 v5 rollout sometime late next year.

“This is a great smorgasbord of things, but there is so much more that we have to do,” said Parikh. “We have to keep pushing the envelope and find ways to keep building more of these building blocks as a community so we can solve all of these interesting problems that we are worried about.”
This is what Facebook has been up to lately. For instance, the elements that make up a Wedge top of rack switch can be assembled in different ways to create an aggregation switch that sits upstream from the top of rackers. Or, in the case of serving for the front-end web applications that provide the Facebook experience, moving from two-socket “Haswell” Xeon E5 v3 to custom “Broadwell” Xeon D processors in “Yosemite” microservers. Or, retrofitting the Open Vault storage array, which is based on cheap SATA disks, with integrated PCI-Express switching and an NVM-Express driver stack to create the “Lightning” flash arrays.
The Yosemite microservers were announced at last year’s Open Compute Summit, concurrent with Intel’s initial rollout of the Xeon D processors that were created specifically to keep the ARM insurgency at bay in the hyperscale glass houses. Intel subsequently revamped the Xeon D line last November and quietly launched a new part, the 16-core Xeon D-1587, in February initially for Facebook and is now making it available to anyone who wants it.

Steve Berg, director of cloud product marketing at Intel’s Data Center Group, tells The Next Platform that this Xeon D-1581 part was initially created for storage workloads, but was modified to run at a higher 1.9 GHz clock speed and a higher 65 watt thermal design point – and with a warranty reduced from five years to three years because of that harder duty cycle – to meet the performance requirements that Facebook sought with its Yosemite microservers. The previous top-bin eight-core Xeon D-1540 part was rated at 45 watts at 2 GHz. The custom Facebook part had double the cores and a slightly lower clock speed, but Parikh said that the Xeon D system was 40 percent more powerful than the previous generation of Xeon E5 servers. (We will be covering this in-depth separately.) The switch to the Xeon D and the Yosemite servers also allowed the company to increase the density of cores in its racks and memory for running its PHP code.
The important thing is that Facebook had the leverage to get Intel to do what it wants, and the rest of the datacenters of the world can benefit from that.
Facebook also worked very closely with Intel to create a new flash array called “Lightning,” which takes the existing “Knox” Open Vault SATA disk arrays and tweaks them to support very high speed flash that is tightly networked to servers using PCI-Express switching.
With the Facebook servers, the bulk storage is disaggregated from the servers and crammed into the Open Vault storage server, which has its own compute element as well as two trays that, when using disks, hold 15 drives each. With the Lightning design, the large 3.5-inch SATA drives used with the Knox disk arrays are replaced with Intel SSDs and are linked to up to four server nodes through a PCI-Express switch that is embedded in the trays. Each tray has its own switch, which can link to 15 devices using PCI-Express x4 links and up to 30 devices using x2 links. The expansion board that has the PCI-Express switch has eight uplinks running at x4 speeds, which link to server nodes through MiniSAS HD cables.
These cables can be up to 2 meters in length, which is sufficient for hooking servers and storage within the Open Rack. The design is means to allow for the PCI-Express links to be aggregated for servers so the compute to storage ratio can be dialed up or down without changing the hardware. The array has an ASPEED AST2400 baseboard management controller running Facebook’s OpenBMC software. Interestingly, Facebook is scaling back the power consumption of flash from the normal 25 watts a flash SSD has to 14 watts to fit within its power envelope. (Precisely how it is doing this remains unclear.) The Lightning array can support M.2 flash sticks as well as 3.5-inch SSDs as well, if the need arises. Facebook says that it is working on a way to create hot plug NVM drives at the moment that is less cranky and difficult than the method used for PCT-Express disk drives. With the 2.5-inch SSDs, a single Lightning array can hose up to 120 TB of flash. This is not a shared pool of flash, by the way. It is allocated for specific servers and looks like local disk to that server.
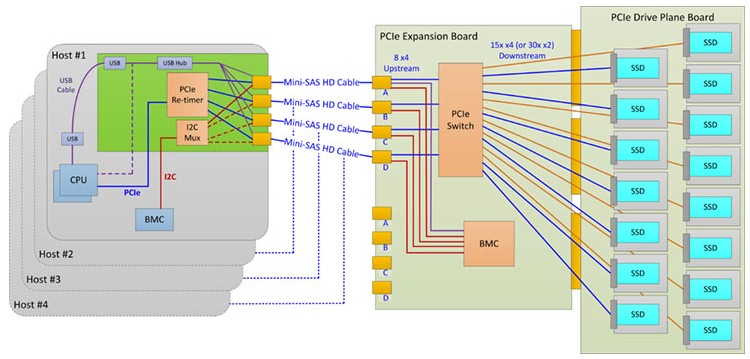
Jason Waxman, general manager of the Cloud Platforms Group at Intel, said in his presentation that the Lightning array could drive an aggregate of 2.5 million I/O operations per second across all of that flash into the servers linked to it, with a latency on the order of 200 microseconds in a 30 TB configuration using slightly faster 1 TB drives instead of fatter 4 TB units that, we presume, have higher latency.
So what’s next? Parikh said that there needs to be more options – and more price/performance options to be specific – in the storage layer of the datacenter.
“The storage industry is such that disk drives are getting bigger, they are not getting more reliable, latency is not improving, and IOPS are not fundamentally changing,” he said. “Flash is also getting slightly bigger, but endurance of flash devices is not improving dramatically, and latency is not going to change by an order of magnitude or two. So we are really kind of stuck with this paradigm where things are scaling out and performance is not getting better. We are not getting what we actually need.”
Parikh gave a shout out to Intel’s 3D XPoint non-volatile memory, which he said could be deployed in a lot of different form factors and referred to as “super-fast memory,” when what we would say is that it is somewhat slower but persistent non-volatile memory. (We knew what he meant.) Memory such as 3D XPoint has much higher endurance, too, and allows for a broader and deeper set of storage tiers for applications to use, and Parikh said the industry has to start working together on how software can be written to exploit this new storage hierarchy.
We think that the Open Compute community is working hard at innovations that we will see with Skylake Xeons, which will come out after 3D XPoint SSDs have ramped in volume and when 3D XPoint memory sticks, which will be byte addressable, will also be available. Late 2017 to early 2018 is going to be an interesting time, particularly with 200 Gb/sec Ethernet and InfiniBand also shipping.


The Eternal Battle Between InfiniBand And Ethernet In HPC
It is always good to have options when it comes to optimizing systems because not all software behaves the same way and not all institutions have the same budgets to try to run their simulations and models on HPC clusters. For this reason, we have seen a variety of interconnects …

Intel Decides To Engineer Its Fab-Filled Future After All
Newly anointed Intel chief executive officer Pat Gelsinger held the coming out party for his strategy to get the world’s largest chip manufacturer and designer back on track, called “Intel Unleashed: Engineering The Future,” on Tuesday after the market closed. It was a strange echo of an essay we wrote …

The Most Complex Chip Ever Made?
Historically Intel put all its cumulative chip knowledge to work advancing Moore’s Law and applying those learnings to its future CPUs. Today, some of those advanced processors are destined for the forthcoming “Aurora” supercomputer at Argonne National Laboratory. However, demanding simulation and modeling workloads also benefit significantly from GPU acceleration. …
Be the first to comment